 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBig Tech influence over AI research revisited: memetic analysis of attribution of ideas to affiliation
Dec 20, 2023



There exists a growing discourse around the domination of Big Tech on the landscape of artificial intelligence (AI) research, yet our comprehension of this phenomenon remains cursory. This paper aims to broaden and deepen our understanding of Big Tech's reach and power within AI research. It highlights the dominance not merely in terms of sheer publication volume but rather in the propagation of new ideas or \textit{memes}. Current studies often oversimplify the concept of influence to the share of affiliations in academic papers, typically sourced from limited databases such as arXiv or specific academic conferences. The main goal of this paper is to unravel the specific nuances of such influence, determining which AI ideas are predominantly driven by Big Tech entities. By employing network and memetic analysis on AI-oriented paper abstracts and their citation network, we are able to grasp a deeper insight into this phenomenon. By utilizing two databases: OpenAlex and S2ORC, we are able to perform such analysis on a much bigger scale than previous attempts. Our findings suggest, that while Big Tech-affiliated papers are disproportionately more cited in some areas, the most cited papers are those affiliated with both Big Tech and Academia. Focusing on the most contagious memes, their attribution to specific affiliation groups (Big Tech, Academia, mixed affiliation) seems to be equally distributed between those three groups. This suggests that the notion of Big Tech domination over AI research is oversimplified in the discourse. Ultimately, this more nuanced understanding of Big Tech's and Academia's influence could inform a more symbiotic alliance between these stakeholders which would better serve the dual goals of societal welfare and the scientific integrity of AI research.
Contrastive News and Social Media Linking using BERT for Articles and Tweets across Dual Platforms
Dec 11, 2023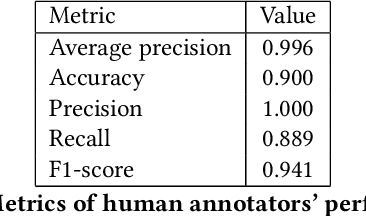
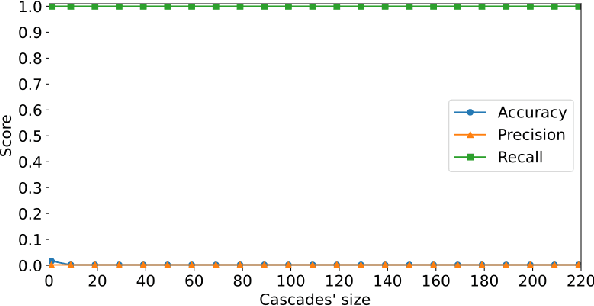
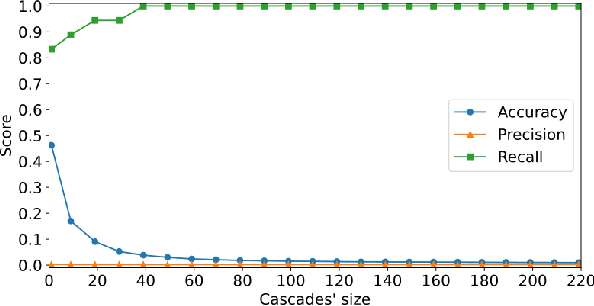

X (formerly Twitter) has evolved into a contemporary agora, offering a platform for individuals to express opinions and viewpoints on current events. The majority of the topics discussed on Twitter are directly related to ongoing events, making it an important source for monitoring public discourse. However, linking tweets to specific news presents a significant challenge due to their concise and informal nature. Previous approaches, including topic models, graph-based models, and supervised classifiers, have fallen short in effectively capturing the unique characteristics of tweets and articles. Inspired by the success of the CLIP model in computer vision, which employs contrastive learning to model similarities between images and captions, this paper introduces a contrastive learning approach for training a representation space where linked articles and tweets exhibit proximity. We present our contrastive learning approach, CATBERT (Contrastive Articles Tweets BERT), leveraging pre-trained BERT models. The model is trained and tested on a dataset containing manually labeled English and Polish tweets and articles related to the Russian-Ukrainian war. We evaluate CATBERT's performance against traditional approaches like LDA, and the novel method based on OpenAI embeddings, which has not been previously applied to this task. Our findings indicate that CATBERT demonstrates superior performance in associating tweets with relevant news articles. Furthermore, we demonstrate the performance of the models when applied to finding the main topic -- represented by an article -- of the whole cascade of tweets. In this new task, we report the performance of the different models in dependence on the cascade size.
HADES: Homologous Automated Document Exploration and Summarization
Feb 25, 2023



This paper introduces HADES, a novel tool for automatic comparative documents with similar structures. HADES is designed to streamline the work of professionals dealing with large volumes of documents, such as policy documents, legal acts, and scientific papers. The tool employs a multi-step pipeline that begins with processing PDF documents using topic modeling, summarization, and analysis of the most important words for each topic. The process concludes with an interactive web app with visualizations that facilitate the comparison of the documents. HADES has the potential to significantly improve the productivity of professionals dealing with high volumes of documents, reducing the time and effort required to complete tasks related to comparative document analysis. Our package is publically available on GitHub.
Climate Policy Tracker: Pipeline for automated analysis of public climate policies
Nov 10, 2022



The number of standardized policy documents regarding climate policy and their publication frequency is significantly increasing. The documents are long and tedious for manual analysis, especially for policy experts, lawmakers, and citizens who lack access or domain expertise to utilize data analytics tools. Potential consequences of such a situation include reduced citizen governance and involvement in climate policies and an overall surge in analytics costs, rendering less accessibility for the public. In this work, we use a Latent Dirichlet Allocation-based pipeline for the automatic summarization and analysis of 10-years of national energy and climate plans (NECPs) for the period from 2021 to 2030, established by 27 Member States of the European Union. We focus on analyzing policy framing, the language used to describe specific issues, to detect essential nuances in the way governments frame their climate policies and achieve climate goals. The methods leverage topic modeling and clustering for the comparative analysis of policy documents across different countries. It allows for easier integration in potential user-friendly applications for the development of theories and processes of climate policy. This would further lead to better citizen governance and engagement over climate policies and public policy research.