 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Dark Patterns of Personalized Persuasion in Large Language Models: Exposing Persuasive Linguistic Features for Big Five Personality Traits in LLMs Responses
Nov 12, 2024



This study explores how the Large Language Models (LLMs) adjust linguistic features to create personalized persuasive outputs. While research showed that LLMs personalize outputs, a gap remains in understanding the linguistic features of their persuasive capabilities. We identified 13 linguistic features crucial for influencing personalities across different levels of the Big Five model of personality. We analyzed how prompts with personality trait information influenced the output of 19 LLMs across five model families. The findings show that models use more anxiety-related words for neuroticism, increase achievement-related words for conscientiousness, and employ fewer cognitive processes words for openness to experience. Some model families excel at adapting language for openness to experience, others for conscientiousness, while only one model adapts language for neuroticism. Our findings show how LLMs tailor responses based on personality cues in prompts, indicating their potential to create persuasive content affecting the mind and well-being of the recipients.
Big Tech influence over AI research revisited: memetic analysis of attribution of ideas to affiliation
Dec 20, 2023There exists a growing discourse around the domination of Big Tech on the landscape of artificial intelligence (AI) research, yet our comprehension of this phenomenon remains cursory. This paper aims to broaden and deepen our understanding of Big Tech's reach and power within AI research. It highlights the dominance not merely in terms of sheer publication volume but rather in the propagation of new ideas or \textit{memes}. Current studies often oversimplify the concept of influence to the share of affiliations in academic papers, typically sourced from limited databases such as arXiv or specific academic conferences. The main goal of this paper is to unravel the specific nuances of such influence, determining which AI ideas are predominantly driven by Big Tech entities. By employing network and memetic analysis on AI-oriented paper abstracts and their citation network, we are able to grasp a deeper insight into this phenomenon. By utilizing two databases: OpenAlex and S2ORC, we are able to perform such analysis on a much bigger scale than previous attempts. Our findings suggest, that while Big Tech-affiliated papers are disproportionately more cited in some areas, the most cited papers are those affiliated with both Big Tech and Academia. Focusing on the most contagious memes, their attribution to specific affiliation groups (Big Tech, Academia, mixed affiliation) seems to be equally distributed between those three groups. This suggests that the notion of Big Tech domination over AI research is oversimplified in the discourse. Ultimately, this more nuanced understanding of Big Tech's and Academia's influence could inform a more symbiotic alliance between these stakeholders which would better serve the dual goals of societal welfare and the scientific integrity of AI research.
HADES: Homologous Automated Document Exploration and Summarization
Feb 25, 2023This paper introduces HADES, a novel tool for automatic comparative documents with similar structures. HADES is designed to streamline the work of professionals dealing with large volumes of documents, such as policy documents, legal acts, and scientific papers. The tool employs a multi-step pipeline that begins with processing PDF documents using topic modeling, summarization, and analysis of the most important words for each topic. The process concludes with an interactive web app with visualizations that facilitate the comparison of the documents. HADES has the potential to significantly improve the productivity of professionals dealing with high volumes of documents, reducing the time and effort required to complete tasks related to comparative document analysis. Our package is publically available on GitHub.
Climate Policy Tracker: Pipeline for automated analysis of public climate policies
Nov 10, 2022



The number of standardized policy documents regarding climate policy and their publication frequency is significantly increasing. The documents are long and tedious for manual analysis, especially for policy experts, lawmakers, and citizens who lack access or domain expertise to utilize data analytics tools. Potential consequences of such a situation include reduced citizen governance and involvement in climate policies and an overall surge in analytics costs, rendering less accessibility for the public. In this work, we use a Latent Dirichlet Allocation-based pipeline for the automatic summarization and analysis of 10-years of national energy and climate plans (NECPs) for the period from 2021 to 2030, established by 27 Member States of the European Union. We focus on analyzing policy framing, the language used to describe specific issues, to detect essential nuances in the way governments frame their climate policies and achieve climate goals. The methods leverage topic modeling and clustering for the comparative analysis of policy documents across different countries. It allows for easier integration in potential user-friendly applications for the development of theories and processes of climate policy. This would further lead to better citizen governance and engagement over climate policies and public policy research.
MAIR: Framework for mining relationships between research articles, strategies, and regulations in the field of explainable artificial intelligence
Jul 29, 2021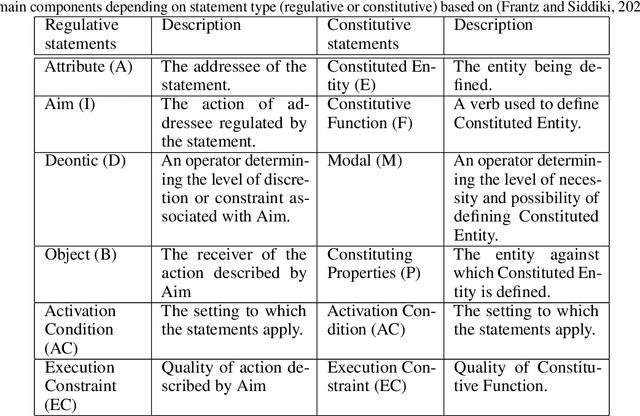
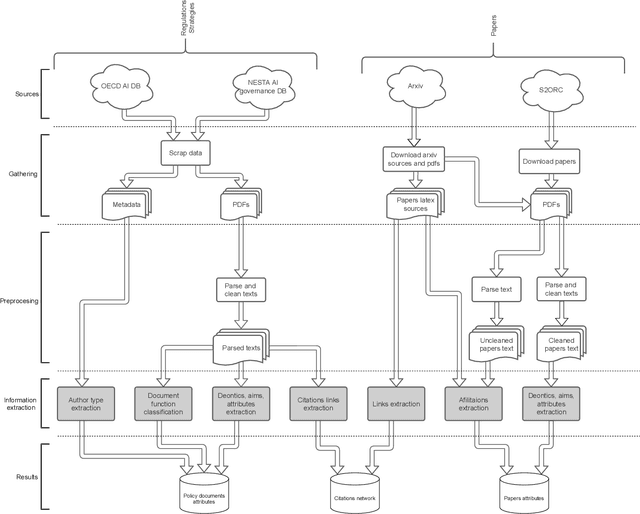
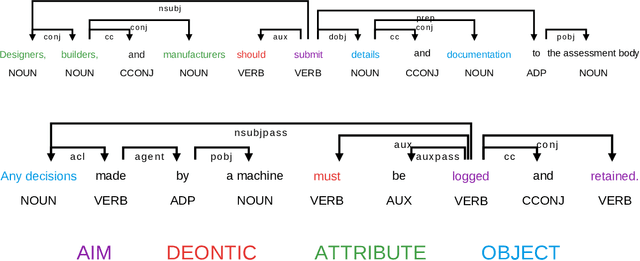
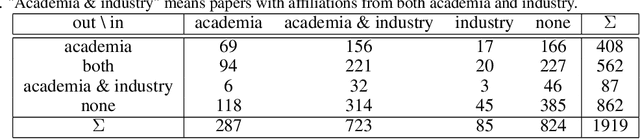
The growing number of AI applications, also for high-stake decisions, increases the interest in Explainable and Interpretable Machine Learning (XI-ML). This trend can be seen both in the increasing number of regulations and strategies for developing trustworthy AI and the growing number of scientific papers dedicated to this topic. To ensure the sustainable development of AI, it is essential to understand the dynamics of the impact of regulation on research papers as well as the impact of scientific discourse on AI-related policies. This paper introduces a novel framework for joint analysis of AI-related policy documents and eXplainable Artificial Intelligence (XAI) research papers. The collected documents are enriched with metadata and interconnections, using various NLP methods combined with a methodology inspired by Institutional Grammar. Based on the information extracted from collected documents, we showcase a series of analyses that help understand interactions, similarities, and differences between documents at different stages of institutionalization. To the best of our knowledge, this is the first work to use automatic language analysis tools to understand the dynamics between XI-ML methods and regulations. We believe that such a system contributes to better cooperation between XAI researchers and AI policymakers.
Statistical analysis of emotions and opinions at Digg website
Apr 16, 2012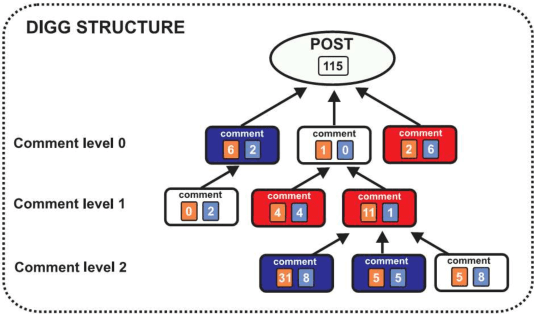
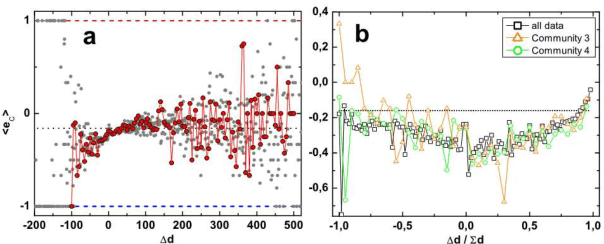
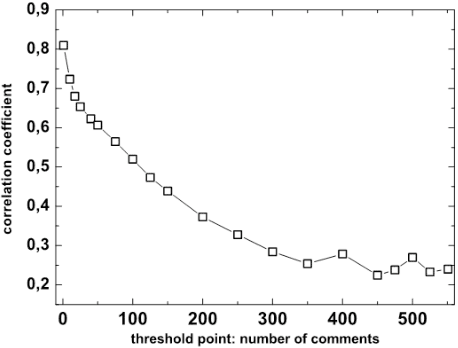
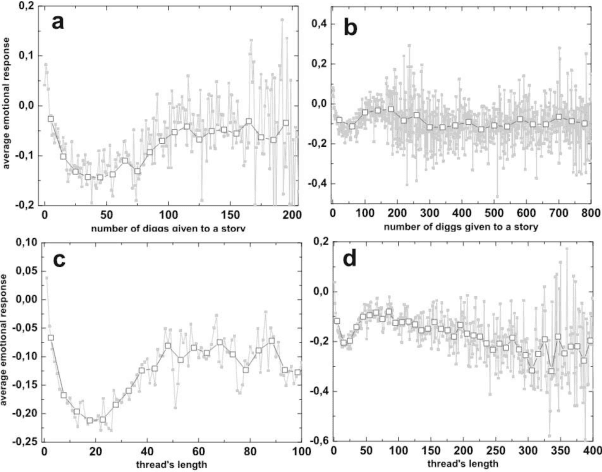
We performed statistical analysis on data from the Digg.com website, which enables its users to express their opinion on news stories by taking part in forum-like discussions as well as directly evaluate previous posts and stories by assigning so called "diggs". Owing to fact that the content of each post has been annotated with its emotional value, apart from the strictly structural properties, the study also includes an analysis of the average emotional response of the posts commenting the main story. While analysing correlations at the story level, an interesting relationship between the number of diggs and the number of comments received by a story was found. The correlation between the two quantities is high for data where small threads dominate and consistently decreases for longer threads. However, while the correlation of the number of diggs and the average emotional response tends to grow for longer threads, correlations between numbers of comments and the average emotional response are almost zero. We also show that the initial set of comments given to a story has a substantial impact on the further "life" of the discussion: high negative average emotions in the first 10 comments lead to longer threads while the opposite situation results in shorter discussions. We also suggest presence of two different mechanisms governing the evolution of the discussion and, consequently, its length.
* 26 pages, 16 figures, 6 tables
Entropy-growth-based model of emotionally charged online dialogues
Jan 26, 2012
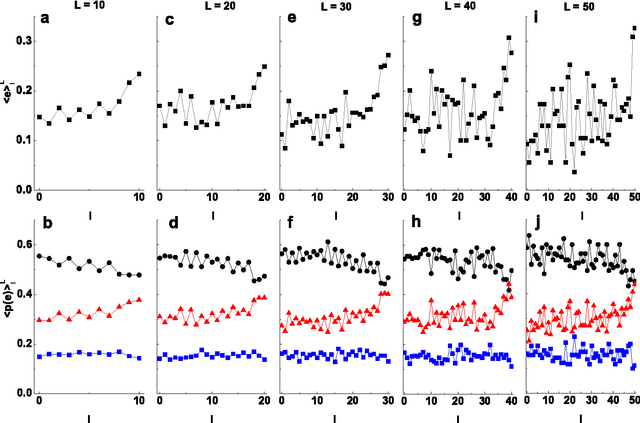
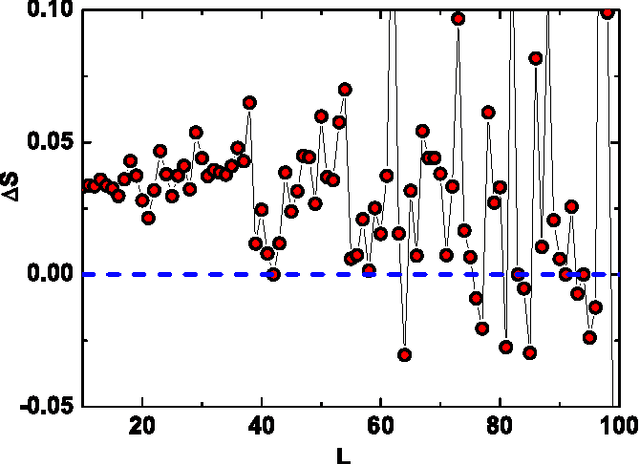
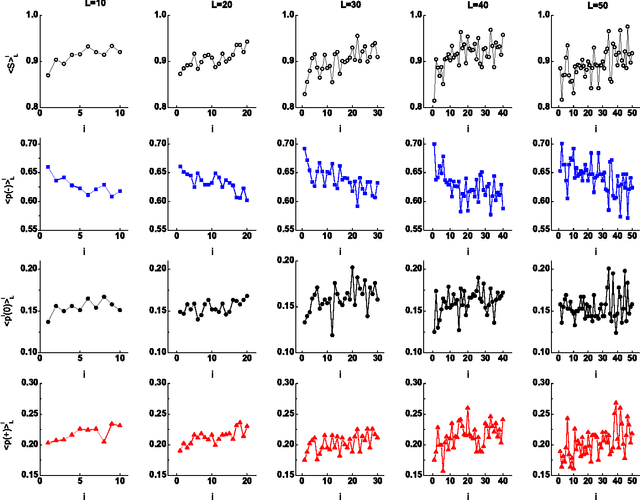
We analyze emotionally annotated massive data from IRC (Internet Relay Chat) and model the dialogues between its participants by assuming that the driving force for the discussion is the entropy growth of emotional probability distribution. This process is claimed to be correlated to the emergence of the power-law distribution of the discussion lengths observed in the dialogues. We perform numerical simulations based on the noticed phenomenon obtaining a good agreement with the real data. Finally, we propose a method to artificially prolong the duration of the discussion that relies on the entropy of emotional probability distribution.
* 9 pages, 2 tables
Emotional Analysis of Blogs and Forums Data
Aug 30, 2011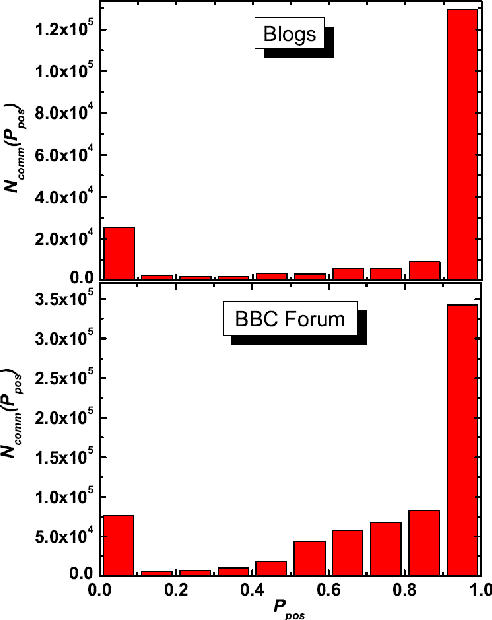
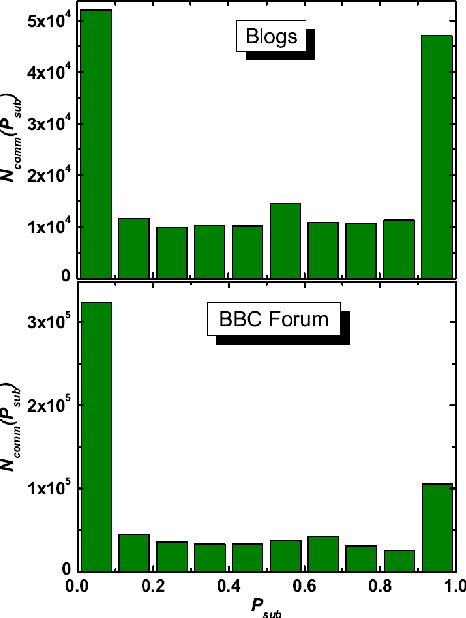
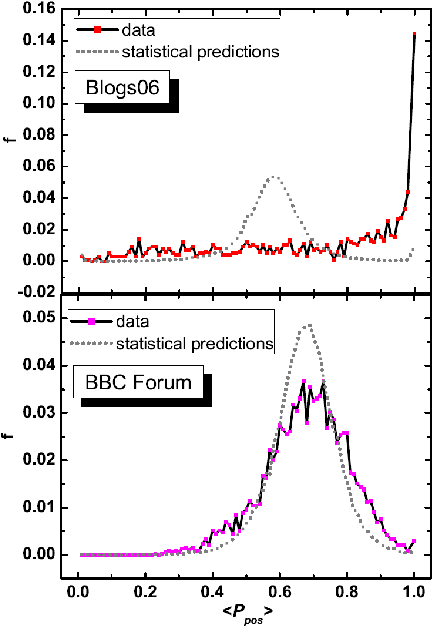
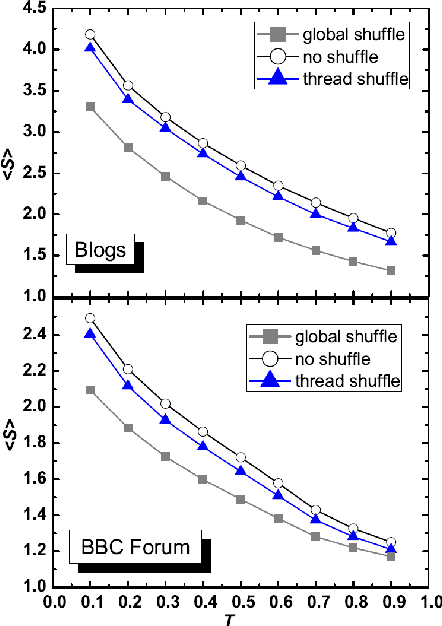
We perform a statistical analysis of emotionally annotated comments in two large online datasets, examining chains of consecutive posts in the discussions. Using comparisons with randomised data we show that there is a high level of correlation for the emotional content of messages.
* REVTEX format, 5 pages, 6 figures, 2 tables, accepted to Acta Physica Polonica A