 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrojan horse hunt in deep forecasting models: Insights from the European Space Agency competition
Mar 20, 2026Forecasting plays a crucial role in modern safety-critical applications, such as space operations. However, the increasing use of deep forecasting models introduces a new security risk of trojan horse attacks, carried out by hiding a backdoor in the training data or directly in the model weights. Once implanted, the backdoor is activated by a specific trigger pattern at test time, causing the model to produce manipulated predictions. We focus on this issue in our \textit{Trojan Horse Hunt} data science competition, where more than 200 teams faced the task of identifying triggers hidden in deep forecasting models for spacecraft telemetry. We describe the novel task formulation, benchmark set, evaluation protocol, and best solutions from the competition. We further summarize key insights and research directions for effective identification of triggers in time series forecasting models. All materials are publicly available on the official competition webpage https://www.kaggle.com/competitions/trojan-horse-hunt-in-space.
Fake or Real: The Impostor Hunt in Texts for Space Operations
Jul 17, 2025The "Fake or Real" competition hosted on Kaggle (\href{https://www.kaggle.com/competitions/fake-or-real-the-impostor-hunt}{https://www.kaggle.com/competitions/fake-or-real-the-impostor-hunt}) is the second part of a series of follow-up competitions and hackathons related to the "Assurance for Space Domain AI Applications" project funded by the European Space Agency (\href{https://assurance-ai.space-codev.org/}{https://assurance-ai.space-codev.org/}). The competition idea is based on two real-life AI security threats identified within the project -- data poisoning and overreliance in Large Language Models. The task is to distinguish between the proper output from LLM and the output generated under malicious modification of the LLM. As this problem was not extensively researched, participants are required to develop new techniques to address this issue or adjust already existing ones to this problem's statement.
Divide, Specialize, and Route: A New Approach to Efficient Ensemble Learning
Jun 25, 2025Ensemble learning has proven effective in boosting predictive performance, but traditional methods such as bagging, boosting, and dynamic ensemble selection (DES) suffer from high computational cost and limited adaptability to heterogeneous data distributions. To address these limitations, we propose Hellsemble, a novel and interpretable ensemble framework for binary classification that leverages dataset complexity during both training and inference. Hellsemble incrementally partitions the dataset into circles of difficulty by iteratively passing misclassified instances from simpler models to subsequent ones, forming a committee of specialised base learners. Each model is trained on increasingly challenging subsets, while a separate router model learns to assign new instances to the most suitable base model based on inferred difficulty. Hellsemble achieves strong classification accuracy while maintaining computational efficiency and interpretability. Experimental results on OpenML-CC18 and Tabzilla benchmarks demonstrate that Hellsemble often outperforms classical ensemble methods. Our findings suggest that embracing instance-level difficulty offers a promising direction for constructing efficient and robust ensemble systems.
MASCOTS: Model-Agnostic Symbolic COunterfactual explanations for Time Series
Mar 28, 2025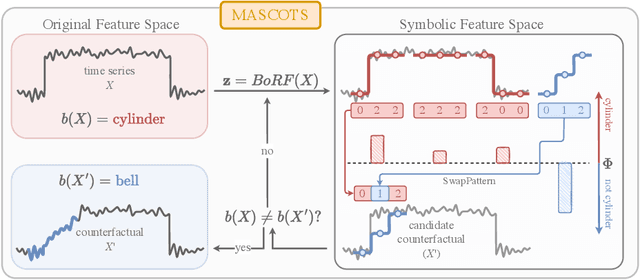
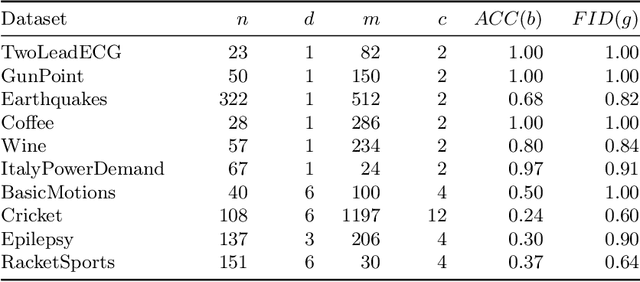

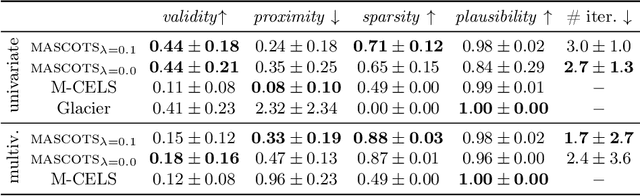
Counterfactual explanations provide an intuitive way to understand model decisions by identifying minimal changes required to alter an outcome. However, applying counterfactual methods to time series models remains challenging due to temporal dependencies, high dimensionality, and the lack of an intuitive human-interpretable representation. We introduce MASCOTS, a method that leverages the Bag-of-Receptive-Fields representation alongside symbolic transformations inspired by Symbolic Aggregate Approximation. By operating in a symbolic feature space, it enhances interpretability while preserving fidelity to the original data and model. Unlike existing approaches that either depend on model structure or autoencoder-based sampling, MASCOTS directly generates meaningful and diverse counterfactual observations in a model-agnostic manner, operating on both univariate and multivariate data. We evaluate MASCOTS on univariate and multivariate benchmark datasets, demonstrating comparable validity, proximity, and plausibility to state-of-the-art methods, while significantly improving interpretability and sparsity. Its symbolic nature allows for explanations that can be expressed visually, in natural language, or through semantic representations, making counterfactual reasoning more accessible and actionable.
The Dark Patterns of Personalized Persuasion in Large Language Models: Exposing Persuasive Linguistic Features for Big Five Personality Traits in LLMs Responses
Nov 12, 2024



This study explores how the Large Language Models (LLMs) adjust linguistic features to create personalized persuasive outputs. While research showed that LLMs personalize outputs, a gap remains in understanding the linguistic features of their persuasive capabilities. We identified 13 linguistic features crucial for influencing personalities across different levels of the Big Five model of personality. We analyzed how prompts with personality trait information influenced the output of 19 LLMs across five model families. The findings show that models use more anxiety-related words for neuroticism, increase achievement-related words for conscientiousness, and employ fewer cognitive processes words for openness to experience. Some model families excel at adapting language for openness to experience, others for conscientiousness, while only one model adapts language for neuroticism. Our findings show how LLMs tailor responses based on personality cues in prompts, indicating their potential to create persuasive content affecting the mind and well-being of the recipients.
Rethinking of Encoder-based Warm-start Methods in Hyperparameter Optimization
Mar 07, 2024Effectively representing heterogeneous tabular datasets for meta-learning remains an open problem. Previous approaches rely on predefined meta-features, for example, statistical measures or landmarkers. Encoder-based models, such as Dataset2Vec, allow us to extract significant meta-features automatically without human intervention. This research introduces a novel encoder-based representation of tabular datasets implemented within the liltab package available on GitHub https://github.com/azoz01/liltab. Our package is based on an established model for heterogeneous tabular data proposed in [Iwata and Kumagai, 2020]. The proposed approach employs a different model for encoding feature relationships, generating alternative representations compared to existing methods like Dataset2Vec. Both of them leverage the fundamental assumption of dataset similarity learning. In this work, we evaluate Dataset2Vec and liltab on two common meta-tasks - representing entire datasets and hyperparameter optimization warm-start. However, validation on an independent metaMIMIC dataset highlights the nuanced challenges in representation learning. We show that general representations may not suffice for some meta-tasks where requirements are not explicitly considered during extraction. [Iwata and Kumagai, 2020] Tomoharu Iwata and Atsutoshi Kumagai. Meta-learning from Tasks with Heterogeneous Attribute Spaces. In Advances in Neural Information Processing Systems, 2020.