 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide, Specialize, and Route: A New Approach to Efficient Ensemble Learning
Jun 25, 2025Ensemble learning has proven effective in boosting predictive performance, but traditional methods such as bagging, boosting, and dynamic ensemble selection (DES) suffer from high computational cost and limited adaptability to heterogeneous data distributions. To address these limitations, we propose Hellsemble, a novel and interpretable ensemble framework for binary classification that leverages dataset complexity during both training and inference. Hellsemble incrementally partitions the dataset into circles of difficulty by iteratively passing misclassified instances from simpler models to subsequent ones, forming a committee of specialised base learners. Each model is trained on increasingly challenging subsets, while a separate router model learns to assign new instances to the most suitable base model based on inferred difficulty. Hellsemble achieves strong classification accuracy while maintaining computational efficiency and interpretability. Experimental results on OpenML-CC18 and Tabzilla benchmarks demonstrate that Hellsemble often outperforms classical ensemble methods. Our findings suggest that embracing instance-level difficulty offers a promising direction for constructing efficient and robust ensemble systems.
Deciphering AutoML Ensembles: cattleia's Assistance in Decision-Making
Mar 19, 2024
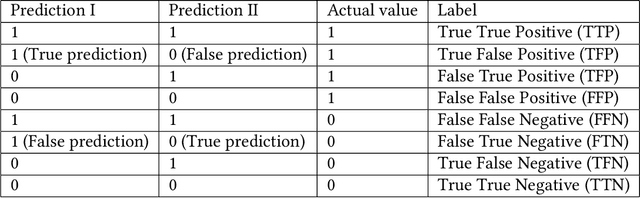
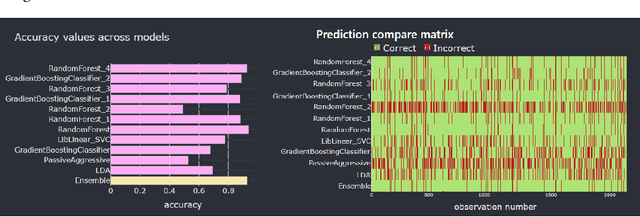

In many applications, model ensembling proves to be better than a single predictive model. Hence, it is the most common post-processing technique in Automated Machine Learning (AutoML). The most popular frameworks use ensembles at the expense of reducing the interpretability of the final models. In our work, we propose cattleia - an application that deciphers the ensembles for regression, multiclass, and binary classification tasks. This tool works with models built by three AutoML packages: auto-sklearn, AutoGluon, and FLAML. The given ensemble is analyzed from different perspectives. We conduct a predictive performance investigation through evaluation metrics of the ensemble and its component models. We extend the validation perspective by introducing new measures to assess the diversity and complementarity of the model predictions. Moreover, we apply explainable artificial intelligence (XAI) techniques to examine the importance of variables. Summarizing obtained insights, we can investigate and adjust the weights with a modification tool to tune the ensemble in the desired way. The application provides the aforementioned aspects through dedicated interactive visualizations, making it accessible to a diverse audience. We believe the cattleia can support users in decision-making and deepen the comprehension of AutoML frameworks.
Rethinking of Encoder-based Warm-start Methods in Hyperparameter Optimization
Mar 07, 2024Effectively representing heterogeneous tabular datasets for meta-learning remains an open problem. Previous approaches rely on predefined meta-features, for example, statistical measures or landmarkers. Encoder-based models, such as Dataset2Vec, allow us to extract significant meta-features automatically without human intervention. This research introduces a novel encoder-based representation of tabular datasets implemented within the liltab package available on GitHub https://github.com/azoz01/liltab. Our package is based on an established model for heterogeneous tabular data proposed in [Iwata and Kumagai, 2020]. The proposed approach employs a different model for encoding feature relationships, generating alternative representations compared to existing methods like Dataset2Vec. Both of them leverage the fundamental assumption of dataset similarity learning. In this work, we evaluate Dataset2Vec and liltab on two common meta-tasks - representing entire datasets and hyperparameter optimization warm-start. However, validation on an independent metaMIMIC dataset highlights the nuanced challenges in representation learning. We show that general representations may not suffice for some meta-tasks where requirements are not explicitly considered during extraction. [Iwata and Kumagai, 2020] Tomoharu Iwata and Atsutoshi Kumagai. Meta-learning from Tasks with Heterogeneous Attribute Spaces. In Advances in Neural Information Processing Systems, 2020.
SeFNet: Bridging Tabular Datasets with Semantic Feature Nets
Jun 20, 2023Machine learning applications cover a wide range of predictive tasks in which tabular datasets play a significant role. However, although they often address similar problems, tabular datasets are typically treated as standalone tasks. The possibilities of using previously solved problems are limited due to the lack of structured contextual information about their features and the lack of understanding of the relations between them. To overcome this limitation, we propose a new approach called Semantic Feature Net (SeFNet), capturing the semantic meaning of the analyzed tabular features. By leveraging existing ontologies and domain knowledge, SeFNet opens up new opportunities for sharing insights between diverse predictive tasks. One such opportunity is the Dataset Ontology-based Semantic Similarity (DOSS) measure, which quantifies the similarity between datasets using relations across their features. In this paper, we present an example of SeFNet prepared for a collection of predictive tasks in healthcare, with the features' relations derived from the SNOMED-CT ontology. The proposed SeFNet framework and the accompanying DOSS measure address the issue of limited contextual information in tabular datasets. By incorporating domain knowledge and establishing semantic relations between features, we enhance the potential for meta-learning and enable valuable insights to be shared across different predictive tasks.
Consolidated learning -- a domain-specific model-free optimization strategy with examples for XGBoost and MIMIC-IV
Jan 27, 2022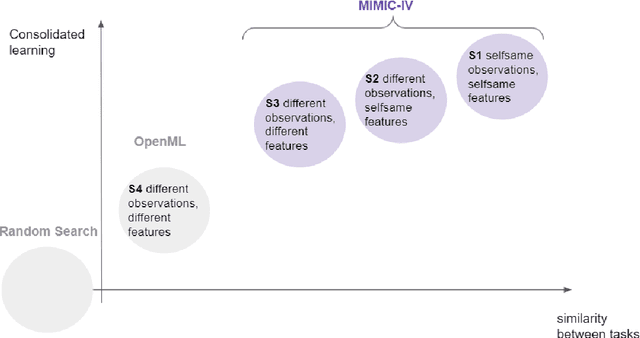
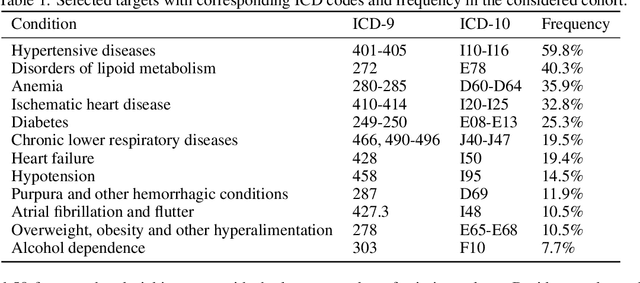
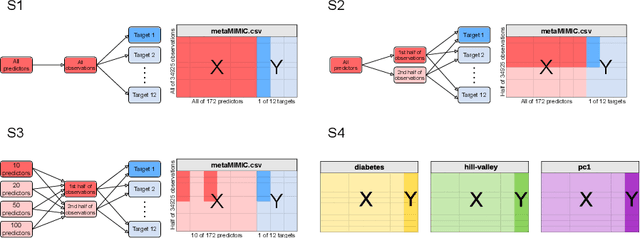
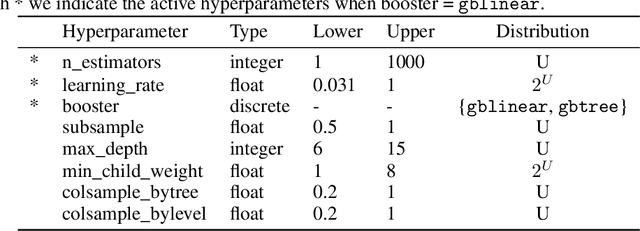
For many machine learning models, a choice of hyperparameters is a crucial step towards achieving high performance. Prevalent meta-learning approaches focus on obtaining good hyperparameters configurations with a limited computational budget for a completely new task based on the results obtained from the prior tasks. This paper proposes a new formulation of the tuning problem, called consolidated learning, more suited to practical challenges faced by model developers, in which a large number of predictive models are created on similar data sets. In such settings, we are interested in the total optimization time rather than tuning for a single task. We show that a carefully selected static portfolio of hyperparameters yields good results for anytime optimization, maintaining ease of use and implementation. Moreover, we point out how to construct such a portfolio for specific domains. The improvement in the optimization is possible due to more efficient transfer of hyperparameter configurations between similar tasks. We demonstrate the effectiveness of this approach through an empirical study for XGBoost algorithm and the collection of predictive tasks extracted from the MIMIC-IV medical database; however, consolidated learning is applicable in many others fields.
Do not explain without context: addressing the blind spot of model explanations
May 28, 2021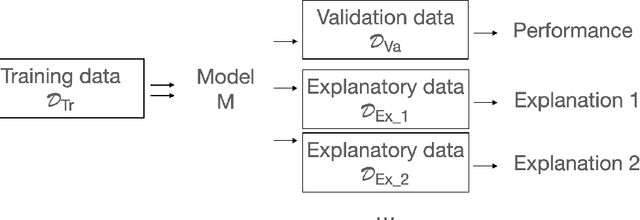
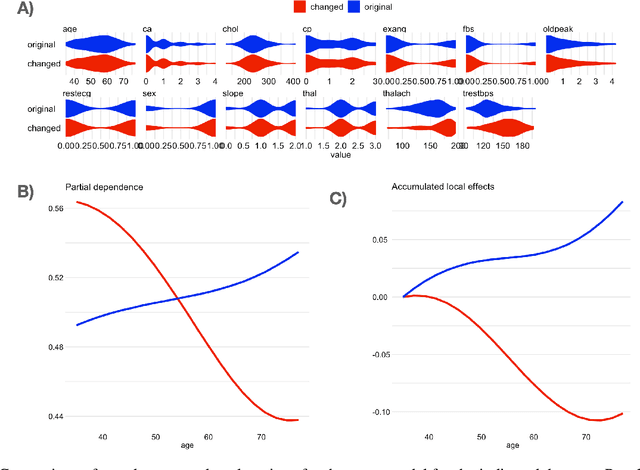
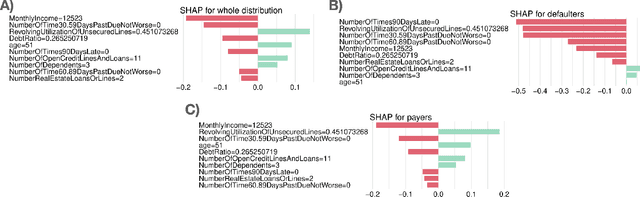
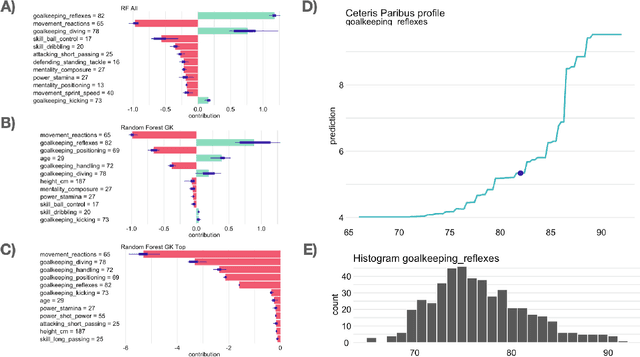
The increasing number of regulations and expectations of predictive machine learning models, such as so called right to explanation, has led to a large number of methods promising greater interpretability. High demand has led to a widespread adoption of XAI techniques like Shapley values, Partial Dependence profiles or permutational variable importance. However, we still do not know enough about their properties and how they manifest in the context in which explanations are created by analysts, reviewed by auditors, and interpreted by various stakeholders. This paper highlights a blind spot which, although critical, is often overlooked when monitoring and auditing machine learning models: the effect of the reference data on the explanation calculation. We discuss that many model explanations depend directly or indirectly on the choice of the referenced data distribution. We showcase examples where small changes in the distribution lead to drastic changes in the explanations, such as a change in trend or, alarmingly, a conclusion. Consequently, we postulate that obtaining robust and useful explanations always requires supporting them with a broader context.
Does imputation matter? Benchmark for predictive models
Jul 06, 2020



Incomplete data are common in practical applications. Most predictive machine learning models do not handle missing values so they require some preprocessing. Although many algorithms are used for data imputation, we do not understand the impact of the different methods on the predictive models' performance. This paper is first that systematically evaluates the empirical effectiveness of data imputation algorithms for predictive models. The main contributions are (1) the recommendation of a general method for empirical benchmarking based on real-life classification tasks and the (2) comparative analysis of different imputation methods for a collection of data sets and a collection of ML algorithms.
Towards better understanding of meta-features contributions
Feb 11, 2020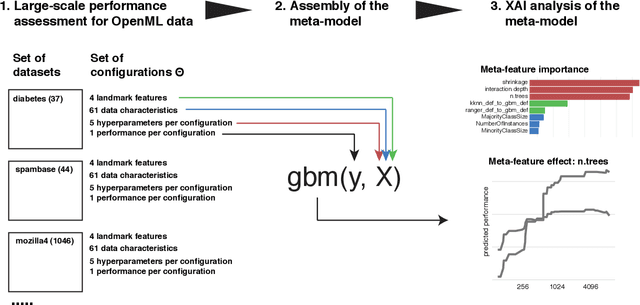
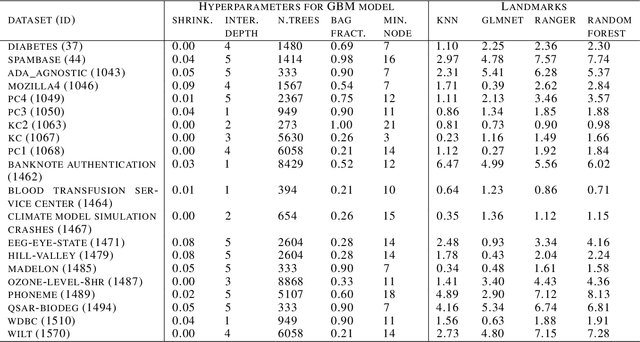

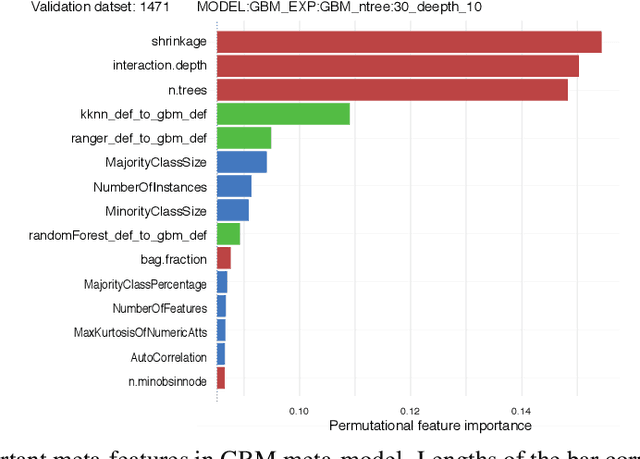
Meta learning is a difficult problem as the expected performance of a model is affected by various aspects such as selected hyperparameters, dataset properties and landmarkers. Existing approaches are focused on searching for the best model but do not explain how these different aspects contribute to the performance of a model. To build a new generation of meta-models we need a deeper understanding of relative importance of meta-features and construction of better meta-features. In this paper we (1) introduce a method that can be used to understand how meta-features influence a model performance, (2) discuss the relative importance of different groups of meta-features, (3) analyse in detail the most informative hyperparameters that may result in insights for selection of empirical priors of engineering for hyperparameters. To our knowledge this is the first paper that uses techniques developed for eXplainable Artificial Intelligence (XAI) to examine the behaviour of a meta model.