 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Ensemble-Based Travel Mode Prediction
Apr 22, 2024Travel mode choice (TMC) prediction, which can be formulated as a classification task, helps in understanding what makes citizens choose different modes of transport for individual trips. This is also a major step towards fostering sustainable transportation. As behaviour may evolve over time, we also face the question of detecting concept drift in the data. This necessitates using appropriate methods to address potential concept drift. In particular, it is necessary to decide whether batch or stream mining methods should be used to develop periodically updated TMC models. To address the challenge of the development of TMC models, we propose the novel Incremental Ensemble of Batch and Stream Models (IEBSM) method aimed at adapting travel mode choice classifiers to concept drift possibly occurring in the data. It relies on the combination of drift detectors with batch learning and stream mining models. We compare it against batch and incremental learners, including methods relying on active drift detection. Experiments with varied travel mode data sets representing both city and country levels show that the IEBSM method both detects drift in travel mode data and successfully adapts the models to evolving travel mode choice data. The method has a higher rank than batch and stream learners.
* This preprint has not undergone peer review or any post-submission improvements or corrections. The Version of Record of this contribution is published in Advances in Intelligent Data Analysis XXII. IDA 2024. Lecture Notes in Computer Science, vol 14641. Springer, and is available online at Cham https://doi.org/10.1007/978-3-031-58547-0_16 The preprint includes 12+22 pages, 1+1 figures
Deep spatial context: when attention-based models meet spatial regression
Jan 18, 2024We propose 'Deep spatial context' (DSCon) method, which serves for investigation of the attention-based vision models using the concept of spatial context. It was inspired by histopathologists, however, the method can be applied to various domains. The DSCon allows for a quantitative measure of the spatial context's role using three Spatial Context Measures: $SCM_{features}$, $SCM_{targets}$, $SCM_{residuals}$ to distinguish whether the spatial context is observable within the features of neighboring regions, their target values (attention scores) or residuals, respectively. It is achieved by integrating spatial regression into the pipeline. The DSCon helps to verify research questions. The experiments reveal that spatial relationships are much bigger in the case of the classification of tumor lesions than normal tissues. Moreover, it turns out that the larger the size of the neighborhood taken into account within spatial regression, the less valuable contextual information is. Furthermore, it is observed that the spatial context measure is the largest when considered within the feature space as opposed to the targets and residuals.
Do not explain without context: addressing the blind spot of model explanations
May 28, 2021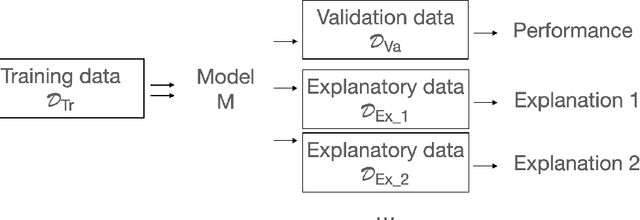
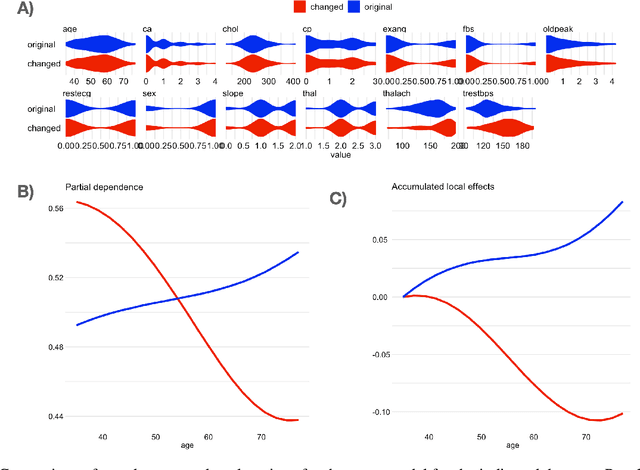
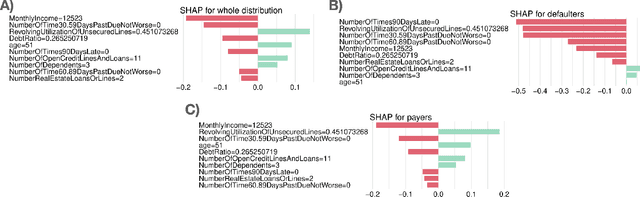
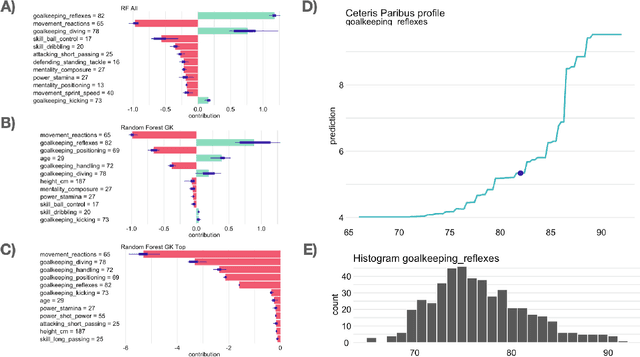
The increasing number of regulations and expectations of predictive machine learning models, such as so called right to explanation, has led to a large number of methods promising greater interpretability. High demand has led to a widespread adoption of XAI techniques like Shapley values, Partial Dependence profiles or permutational variable importance. However, we still do not know enough about their properties and how they manifest in the context in which explanations are created by analysts, reviewed by auditors, and interpreted by various stakeholders. This paper highlights a blind spot which, although critical, is often overlooked when monitoring and auditing machine learning models: the effect of the reference data on the explanation calculation. We discuss that many model explanations depend directly or indirectly on the choice of the referenced data distribution. We showcase examples where small changes in the distribution lead to drastic changes in the explanations, such as a change in trend or, alarmingly, a conclusion. Consequently, we postulate that obtaining robust and useful explanations always requires supporting them with a broader context.