 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFooling Partial Dependence via Data Poisoning
Jun 01, 2021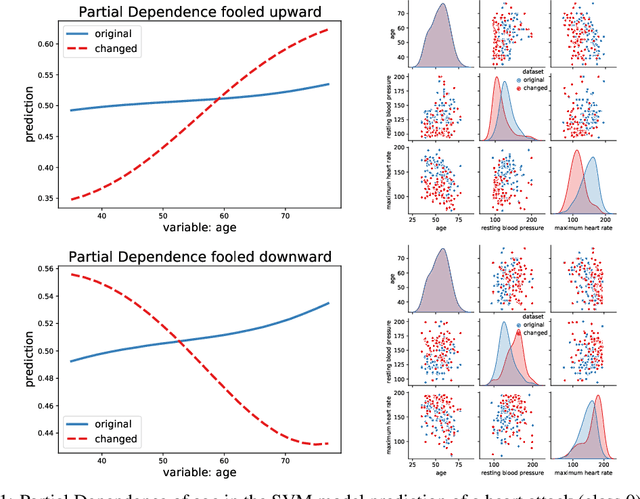
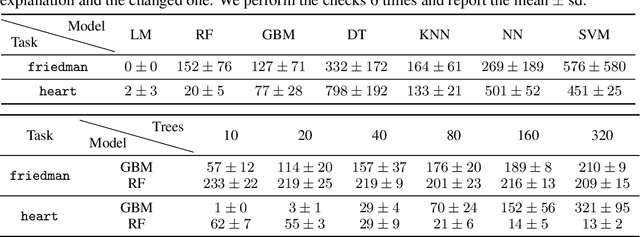
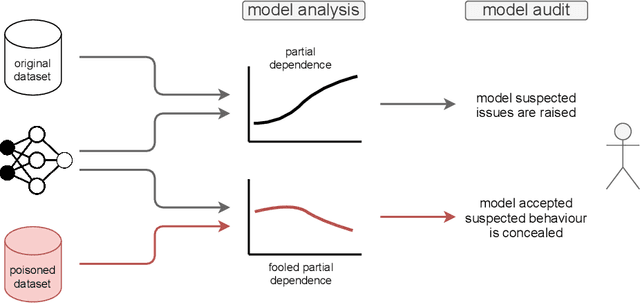
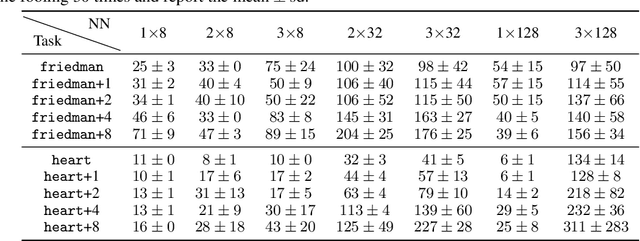
Many methods have been developed to understand complex predictive models and high expectations are placed on post-hoc model explainability. It turns out that such explanations are not robust nor trustworthy, and they can be fooled. This paper presents techniques for attacking Partial Dependence (plots, profiles, PDP), which are among the most popular methods of explaining any predictive model trained on tabular data. We showcase that PD can be manipulated in an adversarial manner, which is alarming, especially in financial or medical applications where auditability became a must-have trait supporting black-box models. The fooling is performed via poisoning the data to bend and shift explanations in the desired direction using genetic and gradient algorithms. To the best of our knowledge, this is the first work performing attacks on variable dependence explanations. The novel approach of using a genetic algorithm for doing so is highly transferable as it generalizes both ways: in a model-agnostic and an explanation-agnostic manner.
Do not explain without context: addressing the blind spot of model explanations
May 28, 2021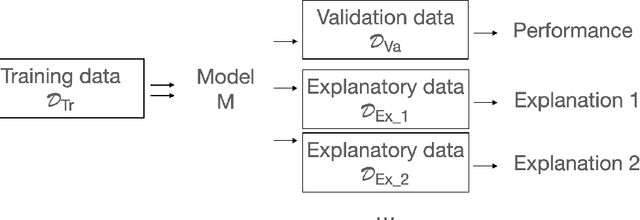
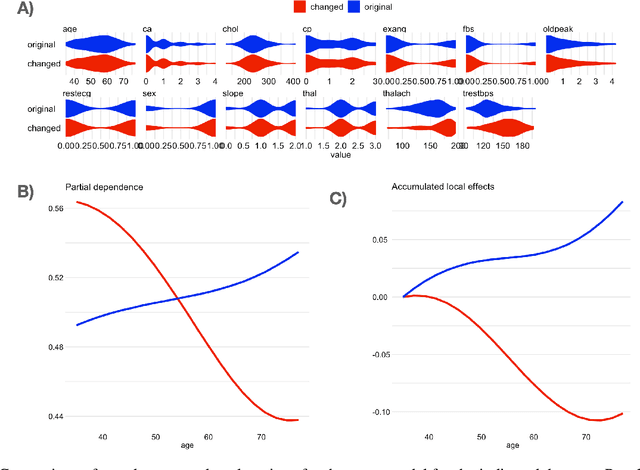
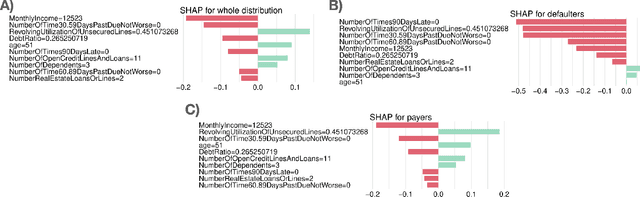
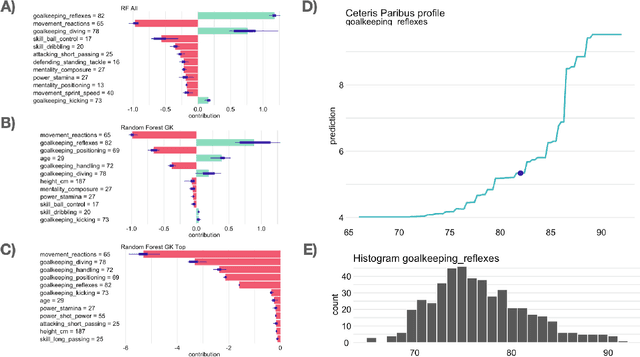
The increasing number of regulations and expectations of predictive machine learning models, such as so called right to explanation, has led to a large number of methods promising greater interpretability. High demand has led to a widespread adoption of XAI techniques like Shapley values, Partial Dependence profiles or permutational variable importance. However, we still do not know enough about their properties and how they manifest in the context in which explanations are created by analysts, reviewed by auditors, and interpreted by various stakeholders. This paper highlights a blind spot which, although critical, is often overlooked when monitoring and auditing machine learning models: the effect of the reference data on the explanation calculation. We discuss that many model explanations depend directly or indirectly on the choice of the referenced data distribution. We showcase examples where small changes in the distribution lead to drastic changes in the explanations, such as a change in trend or, alarmingly, a conclusion. Consequently, we postulate that obtaining robust and useful explanations always requires supporting them with a broader context.
dalex: Responsible Machine Learning with Interactive Explainability and Fairness in Python
Dec 28, 2020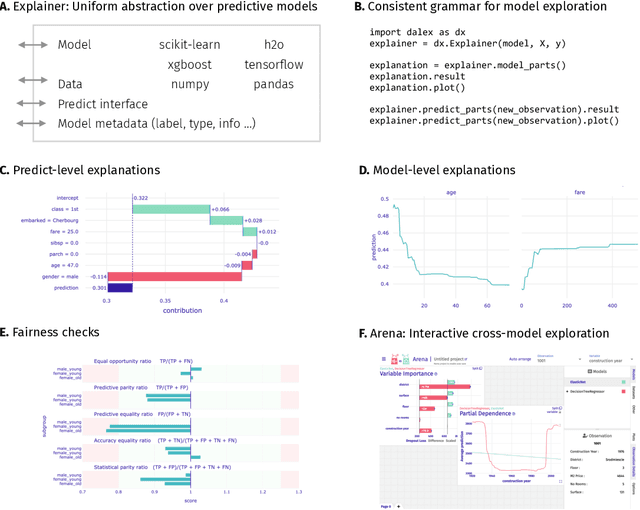
The increasing amount of available data, computing power, and the constant pursuit for higher performance results in the growing complexity of predictive models. Their black-box nature leads to opaqueness debt phenomenon inflicting increased risks of discrimination, lack of reproducibility, and deflated performance due to data drift. To manage these risks, good MLOps practices ask for better validation of model performance and fairness, higher explainability, and continuous monitoring. The necessity of deeper model transparency appears not only from scientific and social domains, but also emerging laws and regulations on artificial intelligence. To facilitate the development of responsible machine learning models, we showcase dalex, a Python package which implements the model-agnostic interface for interactive model exploration. It adopts the design crafted through the development of various tools for responsible machine learning; thus, it aims at the unification of the existing solutions. This library's source code and documentation are available under open license at https://python.drwhy.ai/.
MementoML: Performance of selected machine learning algorithm configurations on OpenML100 datasets
Aug 30, 2020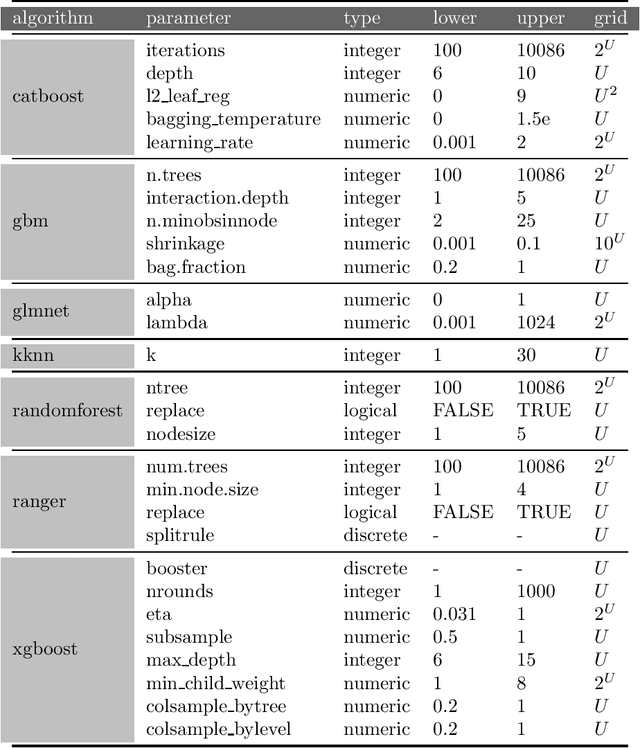
Finding optimal hyperparameters for the machine learning algorithm can often significantly improve its performance. But how to choose them in a time-efficient way? In this paper we present the protocol of generating benchmark data describing the performance of different ML algorithms with different hyperparameter configurations. Data collected in this way is used to study the factors influencing the algorithm's performance. This collection was prepared for the purposes of the study presented in the EPP study. We tested algorithms performance on dense grid of hyperparameters. Tested datasets and hyperparameters were chosen before any algorithm has run and were not changed. This is a different approach than the one usually used in hyperparameter tuning, where the selection of candidate hyperparameters depends on the results obtained previously. However, such selection allows for systematic analysis of performance sensitivity from individual hyperparameters. This resulted in a comprehensive dataset of such benchmarks that we would like to share. We hope, that computed and collected result may be helpful for other researchers. This paper describes the way data was collected. Here you can find benchmarks of 7 popular machine learning algorithms on 39 OpenML datasets. The detailed data forming this benchmark are available at: https://www.kaggle.com/mi2datalab/mementoml.