 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes context matter in digital pathology?
May 23, 2024



The development of Artificial Intelligence for healthcare is of great importance. Models can sometimes achieve even superior performance to human experts, however, they can reason based on spurious features. This is not acceptable to the experts as it is expected that the models catch the valid patterns in the data following domain expertise. In the work, we analyse whether Deep Learning (DL) models for vision follow the histopathologists' practice so that when diagnosing a part of a lesion, they take into account also the surrounding tissues which serve as context. It turns out that the performance of DL models significantly decreases when the amount of contextual information is limited, therefore contextual information is valuable at prediction time. Moreover, we show that the models sometimes behave in an unstable way as for some images, they change the predictions many times depending on the size of the context. It may suggest that partial contextual information can be misleading.
Position paper: Do not explain without context
Apr 28, 2024Does the stethoscope in the picture make the adjacent person a doctor or a patient? This, of course, depends on the contextual relationship of the two objects. If it is obvious, why don not explanation methods for vision models use contextual information? In this paper, we (1) review the most popular methods of explaining computer vision models by pointing out that they do not take into account context information, (2) provide examples of real-world use cases where spatial context plays a significant role, (3) propose new research directions that may lead to better use of context information in explaining computer vision models, (4) argue that a change in approach to explanations is needed from 'where' to 'how'.
Deep spatial context: when attention-based models meet spatial regression
Jan 18, 2024We propose 'Deep spatial context' (DSCon) method, which serves for investigation of the attention-based vision models using the concept of spatial context. It was inspired by histopathologists, however, the method can be applied to various domains. The DSCon allows for a quantitative measure of the spatial context's role using three Spatial Context Measures: $SCM_{features}$, $SCM_{targets}$, $SCM_{residuals}$ to distinguish whether the spatial context is observable within the features of neighboring regions, their target values (attention scores) or residuals, respectively. It is achieved by integrating spatial regression into the pipeline. The DSCon helps to verify research questions. The experiments reveal that spatial relationships are much bigger in the case of the classification of tumor lesions than normal tissues. Moreover, it turns out that the larger the size of the neighborhood taken into account within spatial regression, the less valuable contextual information is. Furthermore, it is observed that the spatial context measure is the largest when considered within the feature space as opposed to the targets and residuals.
Lightweight Conditional Model Extrapolation for Streaming Data under Class-Prior Shift
Jun 10, 2022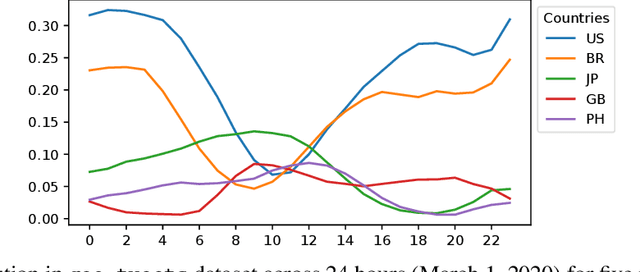
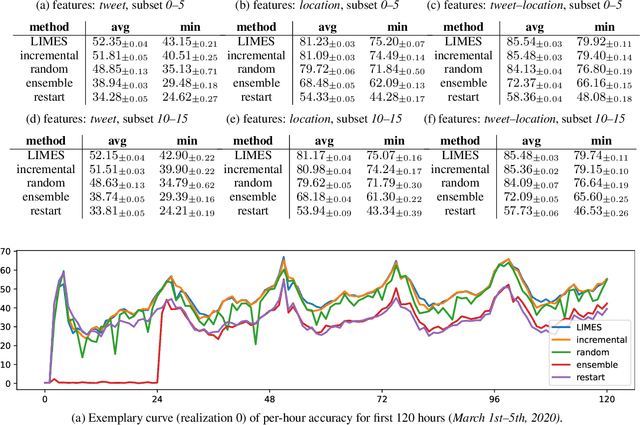
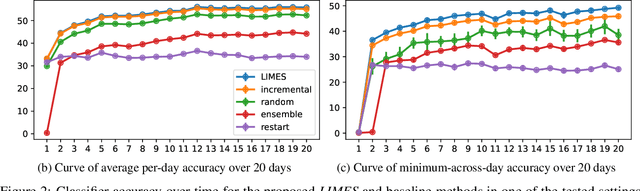
We introduce LIMES, a new method for learning with non-stationary streaming data, inspired by the recent success of meta-learning. The main idea is not to attempt to learn a single classifier that would have to work well across all occurring data distributions, nor many separate classifiers, but to exploit a hybrid strategy: we learn a single set of model parameters from which a specific classifier for any specific data distribution is derived via classifier adaptation. Assuming a multi-class classification setting with class-prior shift, the adaptation step can be performed analytically with only the classifier's bias terms being affected. Another contribution of our work is an extrapolation step that predicts suitable adaptation parameters for future time steps based on the previous data. In combination, we obtain a lightweight procedure for learning from streaming data with varying class distribution that adds no trainable parameters and almost no memory or computational overhead compared to training a single model. Experiments on a set of exemplary tasks using Twitter data show that LIMES achieves higher accuracy than alternative approaches, especially with respect to the relevant real-world metric of lowest within-day accuracy.
Do not repeat these mistakes -- a critical appraisal of applications of explainable artificial intelligence for image based COVID-19 detection
Dec 16, 2020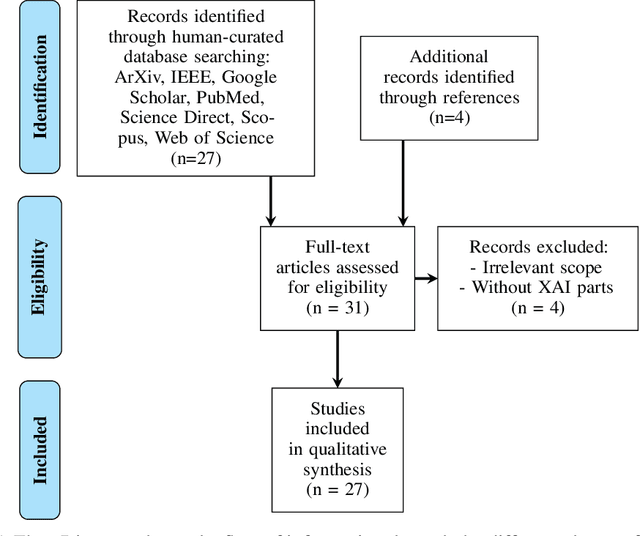
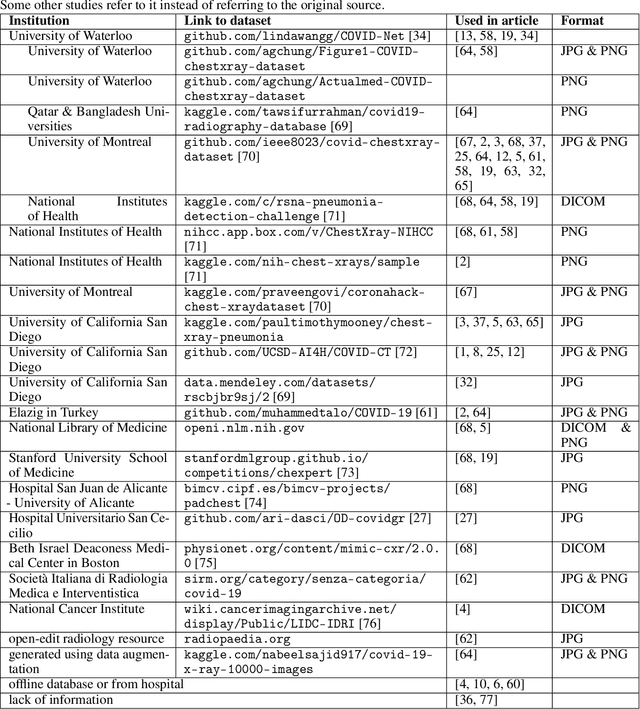
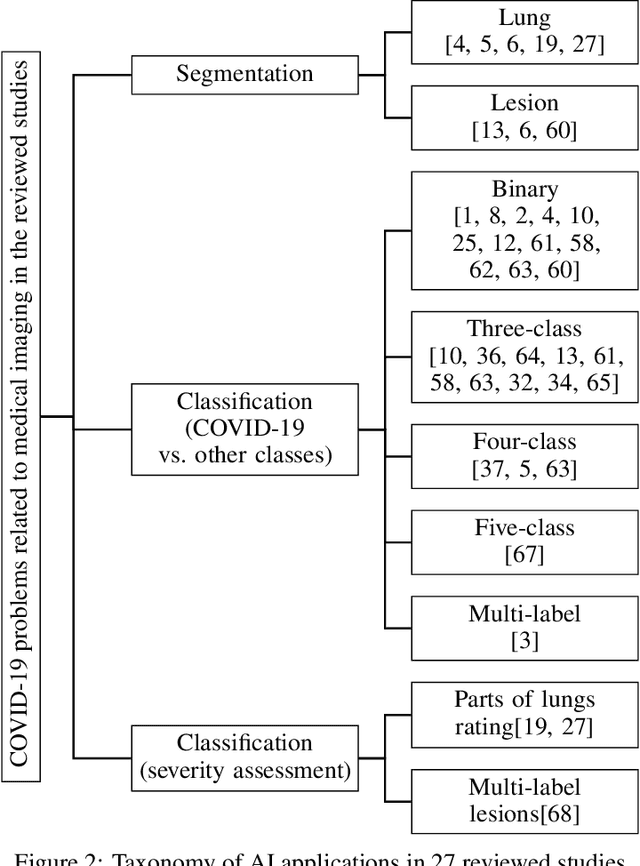
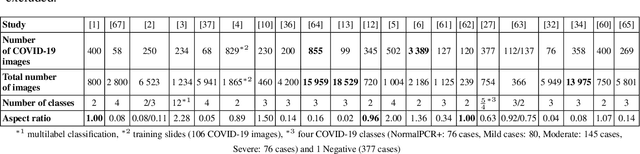
The sudden outbreak and uncontrolled spread of COVID-19 disease is one of the most important global problems today. In a short period of time, it has led to the development of many deep neural network models for COVID-19 detection with modules for explainability. In this work, we carry out a systematic analysis of various aspects of proposed models. Our analysis revealed numerous mistakes made at different stages of data acquisition, model development, and explanation construction. In this work, we overview the approaches proposed in the surveyed ML articles and indicate typical errors emerging from the lack of deep understanding of the radiography domain. We present the perspective of both: experts in the field - radiologists, and deep learning engineers dealing with model explanations. The final result is a proposed a checklist with the minimum conditions to be met by a reliable COVID-19 diagnostic model.