 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Sybil: Explaining Deep Lung Cancer Risk Prediction Through Generative Interventional Attributions
Jan 30, 2026Lung cancer remains the leading cause of cancer mortality, driving the development of automated screening tools to alleviate radiologist workload. Standing at the frontier of this effort is Sybil, a deep learning model capable of predicting future risk solely from computed tomography (CT) with high precision. However, despite extensive clinical validation, current assessments rely purely on observational metrics. This correlation-based approach overlooks the model's actual reasoning mechanism, necessitating a shift to causal verification to ensure robust decision-making before clinical deployment. We propose S(H)NAP, a model-agnostic auditing framework that constructs generative interventional attributions validated by expert radiologists. By leveraging realistic 3D diffusion bridge modeling to systematically modify anatomical features, our approach isolates object-specific causal contributions to the risk score. Providing the first interventional audit of Sybil, we demonstrate that while the model often exhibits behavior akin to an expert radiologist, differentiating malignant pulmonary nodules from benign ones, it suffers from critical failure modes, including dangerous sensitivity to clinically unjustified artifacts and a distinct radial bias.
Underestimation of lung regions on chest X-ray segmentation masks assessed by comparison with total lung volume evaluated on computed tomography
Feb 18, 2024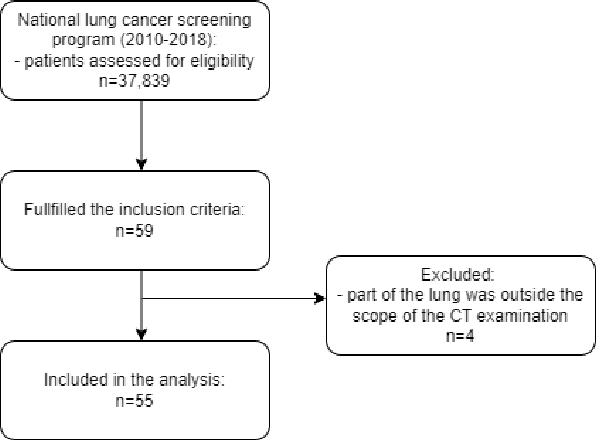
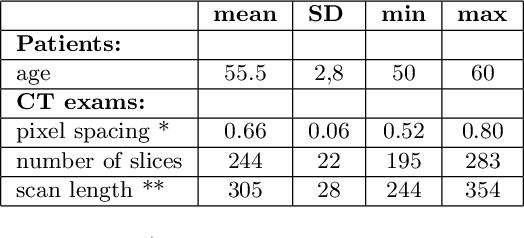
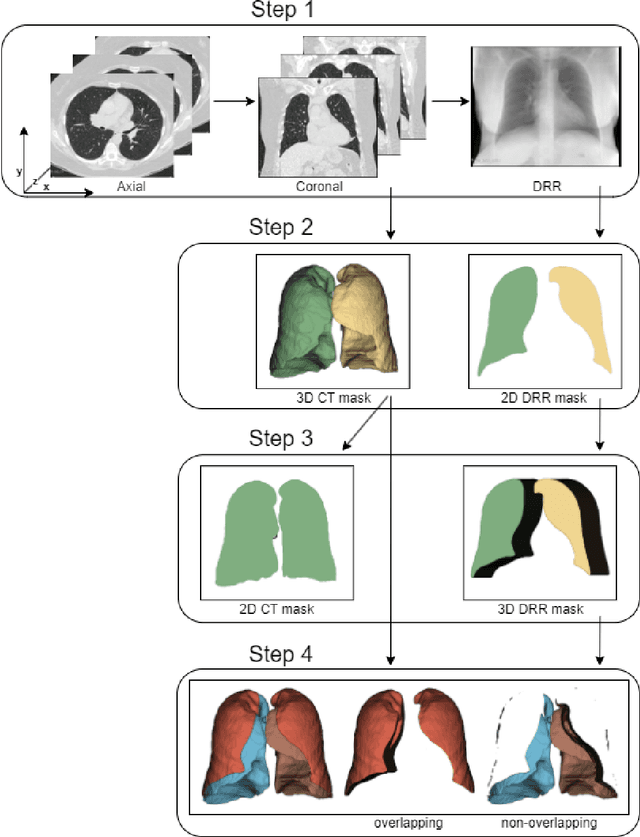
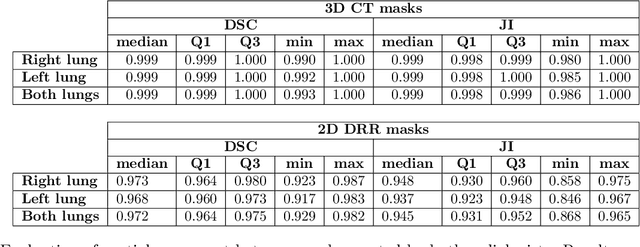
Lung mask creation lacks well-defined criteria and standardized guidelines, leading to a high degree of subjectivity between annotators. In this study, we assess the underestimation of lung regions on chest X-ray segmentation masks created according to the current state-of-the-art method, by comparison with total lung volume evaluated on computed tomography (CT). We show, that lung X-ray masks created by following the contours of the heart, mediastinum, and diaphragm significantly underestimate lung regions and exclude substantial portions of the lungs from further assessment, which may result in numerous clinical errors.
Prevention is better than cure: a case study of the abnormalities detection in the chest
May 18, 2023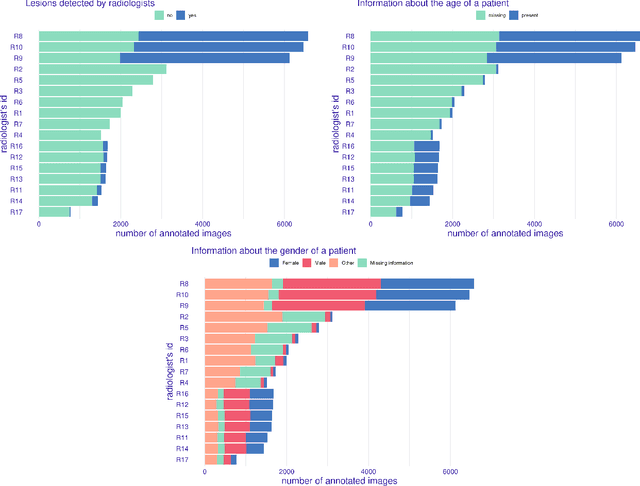

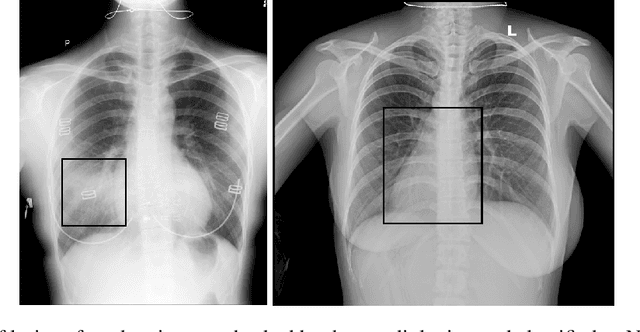

Prevention is better than cure. This old truth applies not only to the prevention of diseases but also to the prevention of issues with AI models used in medicine. The source of malfunctioning of predictive models often lies not in the training process but reaches the data acquisition phase or design of the experiment phase. In this paper, we analyze in detail a single use case - a Kaggle competition related to the detection of abnormalities in X-ray lung images. We demonstrate how a series of simple tests for data imbalance exposes faults in the data acquisition and annotation process. Complex models are able to learn such artifacts and it is difficult to remove this bias during or after the training. Errors made at the data collection stage make it difficult to validate the model correctly. Based on this use case, we show how to monitor data and model balance (fairness) throughout the life cycle of a predictive model, from data acquisition to parity analysis of model scores.
Hospital Length of Stay Prediction Based on Multi-modal Data towards Trustworthy Human-AI Collaboration in Radiomics
Mar 17, 2023To what extent can the patient's length of stay in a hospital be predicted using only an X-ray image? We answer this question by comparing the performance of machine learning survival models on a novel multi-modal dataset created from 1235 images with textual radiology reports annotated by humans. Although black-box models predict better on average than interpretable ones, like Cox proportional hazards, they are not inherently understandable. To overcome this trust issue, we introduce time-dependent model explanations into the human-AI decision making process. Explaining models built on both: human-annotated and algorithm-extracted radiomics features provides valuable insights for physicians working in a hospital. We believe the presented approach to be general and widely applicable to other time-to-event medical use cases. For reproducibility, we open-source code and the TLOS dataset at https://github.com/mi2datalab/xlungs-trustworthy-los-prediction.
Do not repeat these mistakes -- a critical appraisal of applications of explainable artificial intelligence for image based COVID-19 detection
Dec 16, 2020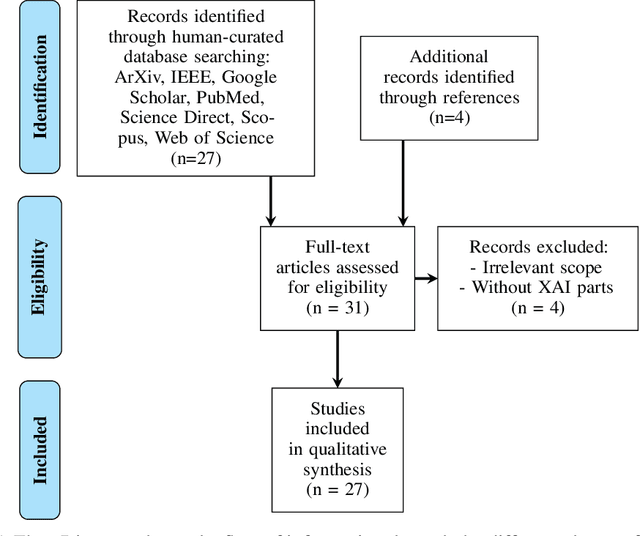
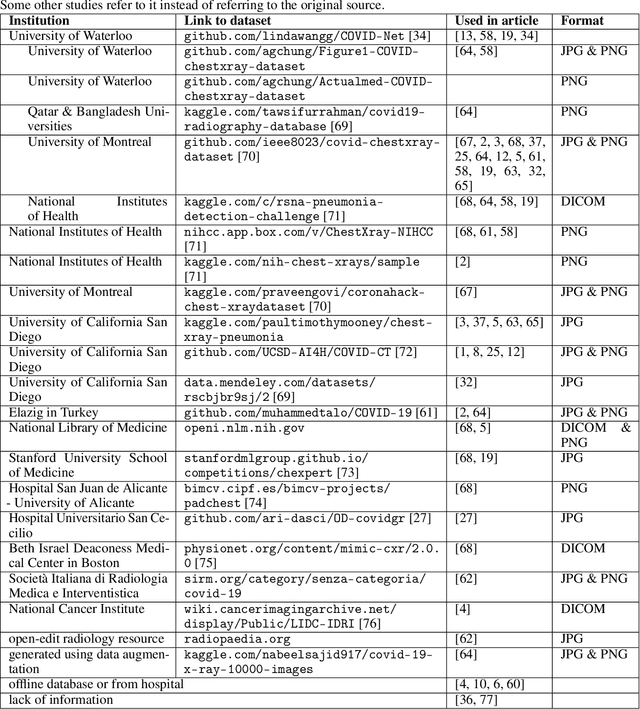
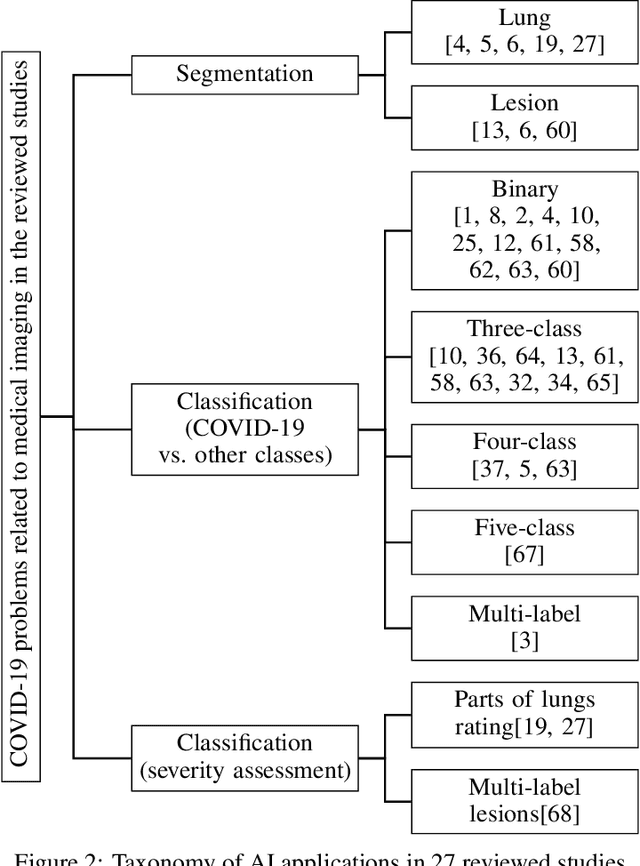
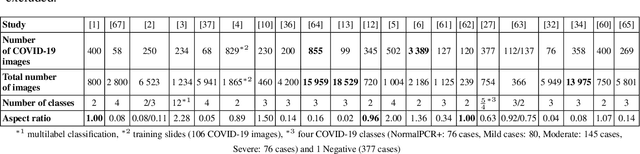
The sudden outbreak and uncontrolled spread of COVID-19 disease is one of the most important global problems today. In a short period of time, it has led to the development of many deep neural network models for COVID-19 detection with modules for explainability. In this work, we carry out a systematic analysis of various aspects of proposed models. Our analysis revealed numerous mistakes made at different stages of data acquisition, model development, and explanation construction. In this work, we overview the approaches proposed in the surveyed ML articles and indicate typical errors emerging from the lack of deep understanding of the radiography domain. We present the perspective of both: experts in the field - radiologists, and deep learning engineers dealing with model explanations. The final result is a proposed a checklist with the minimum conditions to be met by a reliable COVID-19 diagnostic model.