 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Privacy to Generalization: Linear Max-Information Bounds for DP-SGD
May 25, 2026Understanding the relationship between generalization and privacy remains a central challenge in modern machine learning theory, particularly for deep networks trained by variants of differentially private stochastic gradient descent (DP-SGD). In this work we make progress on this persistent open problem by proving a finite-sample bound on the approximate max-information of DP-SGD that exhibits scaling properties comparable with (Dwork et al, 2015)'s classic result for $ε$-differentially private algorithms, namely at most linear in the dataset size. From our result we obtain a general-purpose PAC-Bayes generalization bound in which the necessary prior distribution can be learned by DP-SGD, as well as a generalization bound for DP-SGD-trained models themselves, with a complexity term that is fully explicit and controlled by the optimization hyperparameters.
Beyond Square Roots: Explicit Memory-Efficient Factorization for Multi-Epoch Private Learning
May 18, 2026Correlated-noise mechanisms are among the most promising approaches for improving the utility of differentially private model training, but rigorous guarantees require explicit, analyzable factorizations, and practical deployment requires memory efficiency. Recent works have developed banded inverse factorizations, which address both requirements by exploiting a banded structure in the correlation matrix. The bandwidth controls the size of the noise buffer used to correlate noise across iterations, and thus governs the tradeoff between utility and memory cost. Existing factorizations highlight this tradeoff: DP-$λ$CGD achieves high memory efficiency by using only a one-step noise buffer, but this limits its utility gains, while the banded inverse square root (BISR) factorization exploits larger correlation windows and is asymptotically optimal for large bandwidths but performs poorly at low bandwidths. We propose $γ$-BIFR, a unified generalization of both factorizations. In the low-memory, low-bandwidth regime, $γ$-BIFR significantly improves RMSE, amplified RMSE, and private training performance, while yielding tighter theoretical guarantees for multi-participation error in multi-epoch training.
Adaptive Sampling for Private Worst-Case Group Optimization
Feb 11, 2026Models trained by minimizing the average loss often fail to be accurate on small or hard-to-learn groups of the data. Various methods address this issue by optimizing a weighted objective that focuses on the worst-performing groups. However, this approach becomes problematic when learning with differential privacy, as unequal data weighting can result in inhomogeneous privacy guarantees, in particular weaker privacy for minority groups. In this work, we introduce a new algorithm for differentially private worst-case group optimization called ASC (Adaptively Sampled and Clipped Worst-case Group Optimization). It adaptively controls both the sampling rate and the clipping threshold of each group. Thereby, it allows for harder-to-learn groups to be sampled more often while ensuring consistent privacy guarantees across all groups. Comparing ASC to prior work, we show that it results in lower-variance gradients, tighter privacy guarantees, and substantially higher worst-case group accuracy without sacrificing overall average accuracy.
Towards Robust Scaling Laws for Optimizers
Feb 07, 2026The quality of Large Language Model (LLM) pretraining depends on multiple factors, including the compute budget and the choice of optimization algorithm. Empirical scaling laws are widely used to predict loss as model size and training data grow, however, almost all existing studies fix the optimizer (typically AdamW). At the same time, a new generation of optimizers (e.g., Muon, Shampoo, SOAP) promises faster and more stable convergence, but their relationship with model and data scaling is not yet well understood. In this work, we study scaling laws across different optimizers. Empirically, we show that 1) separate Chinchilla-style scaling laws for each optimizer are ill-conditioned and have highly correlated parameters. Instead, 2) we propose a more robust law with shared power-law exponents and optimizer-specific rescaling factors, which enable direct comparison between optimizers. Finally, 3) we provide a theoretical analysis of gradient-based methods for the proxy task of a convex quadratic objective, demonstrating that Chinchilla-style scaling laws emerge naturally as a result of loss decomposition into irreducible, approximation, and optimization errors.
Matrix Factorization for Practical Continual Mean Estimation Under User-Level Differential Privacy
Jan 29, 2026We study continual mean estimation, where data vectors arrive sequentially and the goal is to maintain accurate estimates of the running mean. We address this problem under user-level differential privacy, which protects each user's entire dataset even when they contribute multiple data points. Previous work on this problem has focused on pure differential privacy. While important, this approach limits applicability, as it leads to overly noisy estimates. In contrast, we analyze the problem under approximate differential privacy, adopting recent advances in the Matrix Factorization mechanism. We introduce a novel mean estimation specific factorization, which is both efficient and accurate, achieving asymptotically lower mean-squared error bounds in continual mean estimation under user-level differential privacy.
DP-$λ$CGD: Efficient Noise Correlation for Differentially Private Model Training
Jan 29, 2026Differentially private stochastic gradient descent (DP-SGD) is the gold standard for training machine learning models with formal differential privacy guarantees. Several recent extensions improve its accuracy by introducing correlated noise across training iterations. Matrix factorization mechanisms are a prominent example, but they correlate noise across many iterations and require storing previously added noise vectors, leading to substantial memory overhead in some settings. In this work, we propose a new noise correlation strategy that correlates noise only with the immediately preceding iteration and cancels a controlled portion of it. Our method relies on noise regeneration using a pseudorandom noise generator, eliminating the need to store past noise. As a result, it requires no additional memory beyond standard DP-SGD. We show that the computational overhead is minimal and empirically demonstrate improved accuracy over DP-SGD.
Learning Quantized Continuous Controllers for Integer Hardware
Nov 17, 2025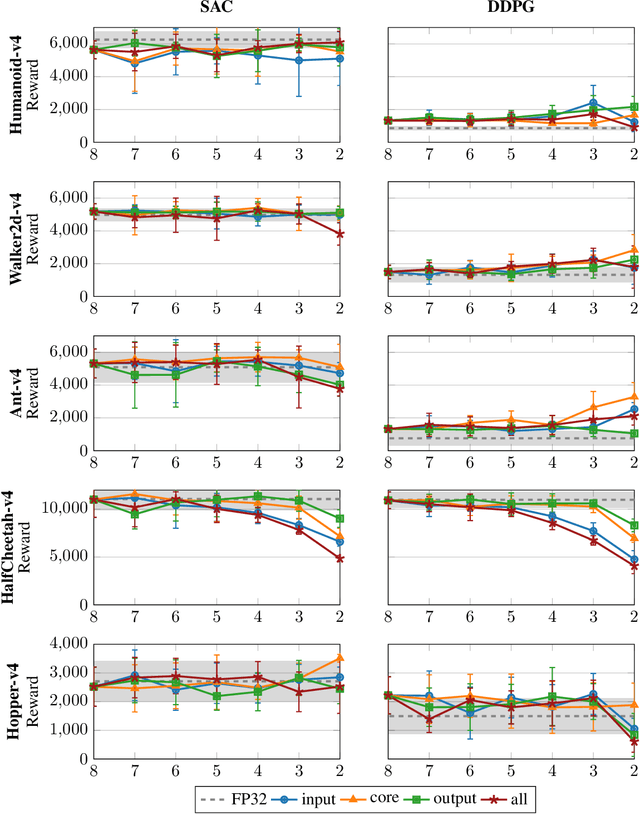
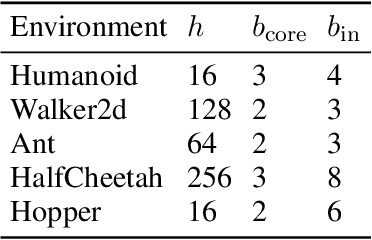
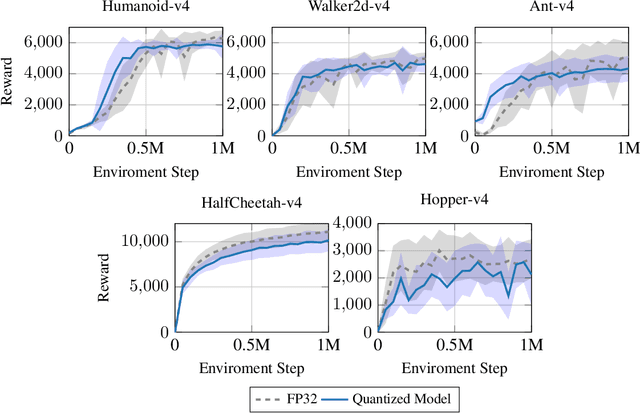

Deploying continuous-control reinforcement learning policies on embedded hardware requires meeting tight latency and power budgets. Small FPGAs can deliver these, but only if costly floating point pipelines are avoided. We study quantization-aware training (QAT) of policies for integer inference and we present a learning-to-hardware pipeline that automatically selects low-bit policies and synthesizes them to an Artix-7 FPGA. Across five MuJoCo tasks, we obtain policy networks that are competitive with full precision (FP32) policies but require as few as 3 or even only 2 bits per weight, and per internal activation value, as long as input precision is chosen carefully. On the target hardware, the selected policies achieve inference latencies on the order of microseconds and consume microjoules per action, favorably comparing to a quantized reference. Last, we observe that the quantized policies exhibit increased input noise robustness compared to the floating-point baseline.
Scalable Interconnect Learning in Boolean Networks
Jul 03, 2025Learned Differentiable Boolean Logic Networks (DBNs) already deliver efficient inference on resource-constrained hardware. We extend them with a trainable, differentiable interconnect whose parameter count remains constant as input width grows, allowing DBNs to scale to far wider layers than earlier learnable-interconnect designs while preserving their advantageous accuracy. To further reduce model size, we propose two complementary pruning stages: an SAT-based logic equivalence pass that removes redundant gates without affecting performance, and a similarity-based, data-driven pass that outperforms a magnitude-style greedy baseline and offers a superior compression-accuracy trade-off.
Differentially Private Federated $k$-Means Clustering with Server-Side Data
Jun 04, 2025Clustering is a cornerstone of data analysis that is particularly suited to identifying coherent subgroups or substructures in unlabeled data, as are generated continuously in large amounts these days. However, in many cases traditional clustering methods are not applicable, because data are increasingly being produced and stored in a distributed way, e.g. on edge devices, and privacy concerns prevent it from being transferred to a central server. To address this challenge, we present \acronym, a new algorithm for $k$-means clustering that is fully-federated as well as differentially private. Our approach leverages (potentially small and out-of-distribution) server-side data to overcome the primary challenge of differentially private clustering methods: the need for a good initialization. Combining our initialization with a simple federated DP-Lloyds algorithm we obtain an algorithm that achieves excellent results on synthetic and real-world benchmark tasks. We also provide a theoretical analysis of our method that provides bounds on the convergence speed and cluster identification success.
Logic Gate Neural Networks are Good for Verification
May 26, 2025Learning-based systems are increasingly deployed across various domains, yet the complexity of traditional neural networks poses significant challenges for formal verification. Unlike conventional neural networks, learned Logic Gate Networks (LGNs) replace multiplications with Boolean logic gates, yielding a sparse, netlist-like architecture that is inherently more amenable to symbolic verification, while still delivering promising performance. In this paper, we introduce a SAT encoding for verifying global robustness and fairness in LGNs. We evaluate our method on five benchmark datasets, including a newly constructed 5-class variant, and find that LGNs are both verification-friendly and maintain strong predictive performance.