 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuartet II: Accurate LLM Pre-Training in NVFP4 by Improved Unbiased Gradient Estimation
Jan 30, 2026The NVFP4 lower-precision format, supported in hardware by NVIDIA Blackwell GPUs, promises to allow, for the first time, end-to-end fully-quantized pre-training of massive models such as LLMs. Yet, existing quantized training methods still sacrifice some of the representation capacity of this format in favor of more accurate unbiased quantized gradient estimation by stochastic rounding (SR), losing noticeable accuracy relative to standard FP16 and FP8 training. In this paper, improve the state of the art for quantized training in NVFP4 via a novel unbiased quantization routine for micro-scaled formats, called MS-EDEN, that has more than 2x lower quantization error than SR. We integrate it into a novel fully-NVFP4 quantization scheme for linear layers, called Quartet II. We show analytically that Quartet II achieves consistently better gradient estimation across all major matrix multiplications, both on the forward and on the backward passes. In addition, our proposal synergizes well with recent training improvements aimed specifically at NVFP4. We further validate Quartet II on end-to-end LLM training with up to 1.9B parameters on 38B tokens. We provide kernels for execution on NVIDIA Blackwell GPUs with up to 4.2x speedup over BF16. Our code is available at https://github.com/IST-DASLab/Quartet-II .
Quartet: Native FP4 Training Can Be Optimal for Large Language Models
May 20, 2025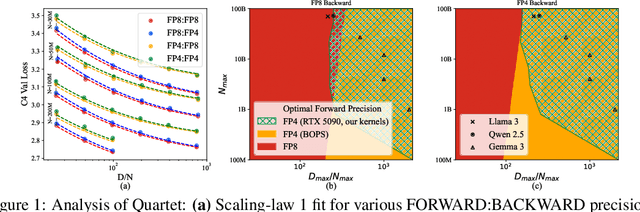


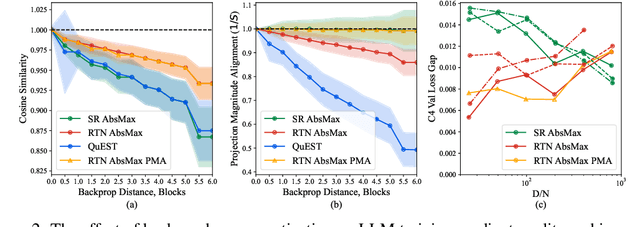
The rapid advancement of large language models (LLMs) has been paralleled by unprecedented increases in computational demands, with training costs for state-of-the-art models doubling every few months. Training models directly in low-precision arithmetic offers a solution, by improving both computational throughput and energy efficiency. Specifically, NVIDIA's recent Blackwell architecture facilitates extremely low-precision operations, specifically FP4 variants, promising substantial efficiency gains. Yet, current algorithms for training LLMs in FP4 precision face significant accuracy degradation and often rely on mixed-precision fallbacks. In this paper, we systematically investigate hardware-supported FP4 training and introduce Quartet, a new approach enabling accurate, end-to-end FP4 training with all the major computations (in e.g. linear layers) being performed in low precision. Through extensive evaluations on Llama-type models, we reveal a new low-precision scaling law that quantifies performance trade-offs across varying bit-widths and allows us to identify a "near-optimal" low-precision training technique in terms of accuracy-vs-computation, called Quartet. We implement Quartet using optimized CUDA kernels tailored for NVIDIA Blackwell GPUs, and show that it can achieve state-of-the-art accuracy for FP4 precision, successfully training billion-scale models. Our method demonstrates that fully FP4-based training is a competitive alternative to standard-precision and FP8 training. Our code is available at https://github.com/IST-DASLab/Quartet.
ASIDE: Architectural Separation of Instructions and Data in Language Models
Mar 13, 2025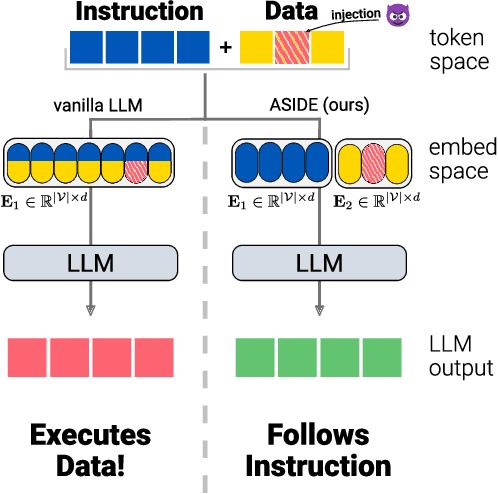
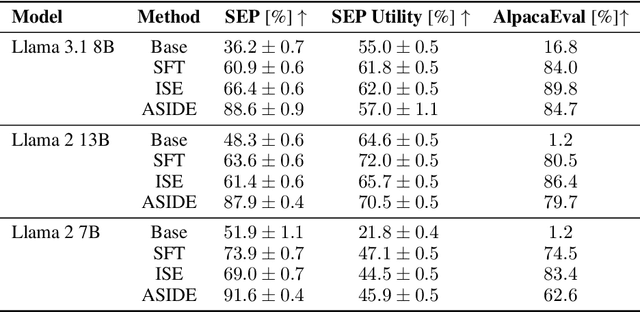
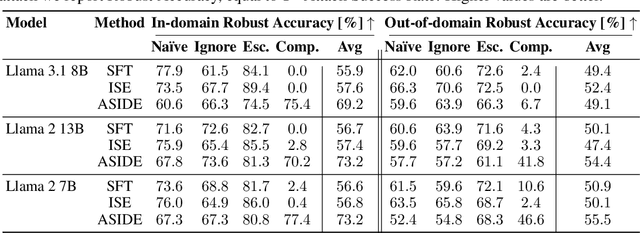
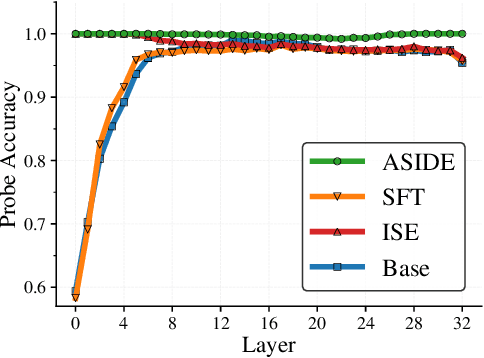
Despite their remarkable performance, large language models lack elementary safety features, and this makes them susceptible to numerous malicious attacks. In particular, previous work has identified the absence of an intrinsic separation between instructions and data as a root cause for the success of prompt injection attacks. In this work, we propose an architectural change, ASIDE, that allows the model to clearly separate between instructions and data by using separate embeddings for them. Instead of training the embeddings from scratch, we propose a method to convert an existing model to ASIDE form by using two copies of the original model's embeddings layer, and applying an orthogonal rotation to one of them. We demonstrate the effectiveness of our method by showing (1) highly increased instruction-data separation scores without a loss in model capabilities and (2) competitive results on prompt injection benchmarks, even without dedicated safety training. Additionally, we study the working mechanism behind our method through an analysis of model representations.
QuEST: Stable Training of LLMs with 1-Bit Weights and Activations
Feb 07, 2025



One approach to reducing the massive costs of large language models (LLMs) is the use of quantized or sparse representations for training or deployment. While post-training compression methods are very popular, the question of obtaining even more accurate compressed models by directly training over such representations, i.e., Quantization-Aware Training (QAT), is still open: for example, a recent study (arXiv:2411.04330v2) put the "optimal" bit-width at which models can be trained using QAT, while staying accuracy-competitive with standard FP16/BF16 precision, at 8-bits weights and activations. We advance this state-of-the-art via a new method called QuEST, which is Pareto-competitive with FP16, i.e., it provides better accuracy at lower model size, while training models with weights and activations in 4-bits or less. Moreover, QuEST allows stable training with 1-bit weights and activations. QuEST achieves this by improving two key aspects of QAT methods: (1) accurate and fast quantization of the (continuous) distributions of weights and activations via Hadamard normalization and MSE-optimal fitting; (2) a new trust gradient estimator based on the idea of explicitly minimizing the error between the noisy gradient computed over quantized states and the "true" (but unknown) full-precision gradient. Experiments on Llama-type architectures show that QuEST induces stable scaling laws across the entire range of hardware-supported precisions, and can be extended to sparse representations. We provide GPU kernel support showing that models produced by QuEST can be executed efficiently. Our code is available at https://github.com/IST-DASLab/QuEST.
HALO: Hadamard-Assisted Lossless Optimization for Efficient Low-Precision LLM Training and Fine-Tuning
Jan 05, 2025



Quantized training of Large Language Models (LLMs) remains an open challenge, as maintaining accuracy while performing all matrix multiplications in low precision has proven difficult. This is particularly the case when fine-tuning pre-trained models, which often already have large weight and activation outlier values that render quantized optimization difficult. We present HALO, a novel quantization-aware training approach for Transformers that enables accurate and efficient low-precision training by combining 1) strategic placement of Hadamard rotations in both forward and backward passes, to mitigate outliers during the low-precision computation, 2) FSDP integration for low-precision communication, and 3) high-performance kernel support. Our approach ensures that all large matrix multiplications during the forward and backward passes are executed in lower precision. Applied to LLAMA-family models, HALO achieves near-full-precision-equivalent results during fine-tuning on various tasks, while delivering up to 1.31x end-to-end speedup for full fine-tuning on RTX 4090 GPUs. Our method supports both standard and parameter-efficient fine-tuning (PEFT) methods, both backed by efficient kernel implementations. Our results demonstrate the first practical approach to fully quantized LLM fine-tuning that maintains accuracy in FP8 precision, while delivering performance benefits.
RoSA: Accurate Parameter-Efficient Fine-Tuning via Robust Adaptation
Jan 12, 2024



We investigate parameter-efficient fine-tuning (PEFT) methods that can provide good accuracy under limited computational and memory budgets in the context of large language models (LLMs). We present a new PEFT method called Robust Adaptation (RoSA) inspired by robust principal component analysis (PCA) that jointly trains $\textit{low-rank}$ and $\textit{highly-sparse}$ components on top of a set of fixed pretrained weights to efficiently approximate the performance of a full-fine-tuning (FFT) solution. Across a series of challenging generative tasks such as grade-school math and SQL query generation, which require fine-tuning for good performance, we show that RoSA outperforms both LoRA and pure sparse fine-tuning, at the same parameter budget. We provide system support for RoSA to complement the training algorithm, specifically in the form of sparse GPU kernels which enable memory- and computationally-efficient training. Our code will be made available at https://github.com/IST-DASLab/RoSA.
Vision Models Can Be Efficiently Specialized via Few-Shot Task-Aware Compression
Mar 25, 2023Recent vision architectures and self-supervised training methods enable vision models that are extremely accurate and general, but come with massive parameter and computational costs. In practical settings, such as camera traps, users have limited resources, and may fine-tune a pretrained model on (often limited) data from a small set of specific categories of interest. These users may wish to make use of modern, highly-accurate models, but are often computationally constrained. To address this, we ask: can we quickly compress large generalist models into accurate and efficient specialists? For this, we propose a simple and versatile technique called Few-Shot Task-Aware Compression (TACO). Given a large vision model that is pretrained to be accurate on a broad task, such as classification over ImageNet-22K, TACO produces a smaller model that is accurate on specialized tasks, such as classification across vehicle types or animal species. Crucially, TACO works in few-shot fashion, i.e. only a few task-specific samples are used, and the procedure has low computational overheads. We validate TACO on highly-accurate ResNet, ViT/DeiT, and ConvNeXt models, originally trained on ImageNet, LAION, or iNaturalist, which we specialize and compress to a diverse set of "downstream" subtasks. TACO can reduce the number of non-zero parameters in existing models by up to 20x relative to the original models, leading to inference speedups of up to 3$\times$, while remaining accuracy-competitive with the uncompressed models on the specialized tasks.