 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning with Low-Rank Structure for Data Selection
Jun 14, 2026In the data selection problem, the objective is to choose a small, representative subset of data that can be used to efficiently train a machine learning model. Sener and Savarese [ICLR 2018] showed that, given an embedding representation of the data and suitable geometric assumptions, heuristics based on $k$-center clustering can be used to perform data selection. This perspective was further explored by Axiotis et. al. [ICML 2024], who proposed a data selection approach based on $k$-means clustering and sensitivity sampling. However, these methods rely on the assumption that the dataset exhibits intrinsic geometric structure that can be effectively captured by clustering, whereas many modern datasets instead possess global algebraic structure that is better exploited by low-rank approximation or principal component analysis. In this paper, we introduce a new data selection framework based on low-rank approximation and residual-based sampling, formulated through the lens of row subset selection and loss-preserving coreset construction. Given an embedding representation of the data satisfying mild regularity conditions, which can be interpreted as algebraic or angular notions of Lipschitz continuity, we show that it is possible to select a weighted subset of $\tilde{O}\left(k + \frac{1}{\varepsilon^2}\right)$ data points whose average loss approximates the average loss over the full dataset within a $(1+\varepsilon)$ relative error, up to an additive $\varepsilon Φ_k$ term, where $Φ_k$ denotes the optimal rank-$k$ approximation cost of the embedding matrix. We complement these theoretical guarantees with empirical evaluations, demonstrating that on a range of real-world datasets, our data selection approach achieves improved performance over prior strategies based on uniform sampling or clustering-based sensitivity sampling.
GSQ: Highly-Accurate Low-Precision Scalar Quantization for LLMs via Gumbel-Softmax Sampling
Apr 20, 2026Weight quantization has become a standard tool for efficient LLM deployment, especially for local inference, where models are now routinely served at 2-3 bits per parameter. The state of the art is currently split into two sets of methods: simple scalar quantization techniques, such as GPTQ or AWQ, which are widely deployed but plateau in accuracy at 3-4 bits per parameter (bpp), and "second-generation" vector- or trellis-quantized methods, such as QTIP, GPTVQ and AQLM, which push the accuracy frontier at low bit-widths but are notoriously hard to implement and to scale, and have gained relatively less traction. In this paper, we ask whether this gap is fundamental, or whether a carefully optimized scalar quantizer can recover most of it. We answer in the affirmative, by introducing GSQ (Gumbel-Softmax Quantization), a post-training scalar quantization method which jointly learns the per-coordinate grid assignments and the per-group scales using a Gumbel-Softmax relaxation of the discrete grid. GSQ matches the cardinality of the relaxation to the small number of levels available in the target bit-width regime (e.g., 3-8 levels for ternary and 3 bpp, respectively), making the relaxation tight and the optimization tractable. Practically, on the standard Llama-3.1-8B/70B-Instruct models, GSQ closes most of the gap between scalar quantization and the QTIP frontier at 2 and 3 bits, while using a symmetric scalar grid with group-wise quantization, and thus fully compatible with existing scalar inference kernels. We further show that GSQ scales to trillion-scale Mixture-of-Experts models such as Kimi-K2.5, where vector-quantized methods are difficult to apply.
ECO: Quantized Training without Full-Precision Master Weights
Jan 29, 2026Quantization has significantly improved the compute and memory efficiency of Large Language Model (LLM) training. However, existing approaches still rely on accumulating their updates in high-precision: concretely, gradient updates must be applied to a high-precision weight buffer, known as $\textit{master weights}$. This buffer introduces substantial memory overhead, particularly for Sparse Mixture of Experts (SMoE) models, where model parameters and optimizer states dominate memory usage. To address this, we introduce the Error-Compensating Optimizer (ECO), which eliminates master weights by applying updates directly to quantized parameters. ECO quantizes weights after each step and carefully injects the resulting quantization error into the optimizer momentum, forming an error-feedback loop with no additional memory. We prove that, under standard assumptions and a decaying learning rate, ECO converges to a constant-radius neighborhood of the optimum, while naive master-weight removal can incur an error that is inversely proportional to the learning rate. We show empirical results for pretraining small Transformers (30-800M), a Gemma-3 1B model, and a 2.1B parameter Sparse MoE model with FP8 quantization, and fine-tuning DeepSeek-MoE-16B in INT4 precision. Throughout, ECO matches baselines with master weights up to near-lossless accuracy, significantly shifting the static memory vs validation loss Pareto frontier.
Efficient Data Selection at Scale via Influence Distillation
May 25, 2025Effective data selection is critical for efficient training of modern Large Language Models (LLMs). This paper introduces Influence Distillation, a novel, mathematically-justified framework for data selection that employs second-order information to optimally weight training samples. By distilling each sample's influence on a target distribution, our method assigns model-specific weights that are used to select training data for LLM fine-tuning, guiding it toward strong performance on the target domain. We derive these optimal weights for both Gradient Descent and Adam optimizers. To ensure scalability and reduce computational cost, we propose a $\textit{landmark-based approximation}$: influence is precisely computed for a small subset of "landmark" samples and then efficiently propagated to all other samples to determine their weights. We validate Influence Distillation by applying it to instruction tuning on the Tulu V2 dataset, targeting a range of tasks including GSM8k, SQuAD, and MMLU, across several models from the Llama and Qwen families. Experiments show that Influence Distillation matches or outperforms state-of-the-art performance while achieving up to $3.5\times$ faster selection.
Quartet: Native FP4 Training Can Be Optimal for Large Language Models
May 20, 2025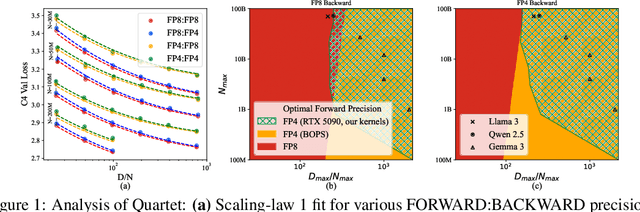


The rapid advancement of large language models (LLMs) has been paralleled by unprecedented increases in computational demands, with training costs for state-of-the-art models doubling every few months. Training models directly in low-precision arithmetic offers a solution, by improving both computational throughput and energy efficiency. Specifically, NVIDIA's recent Blackwell architecture facilitates extremely low-precision operations, specifically FP4 variants, promising substantial efficiency gains. Yet, current algorithms for training LLMs in FP4 precision face significant accuracy degradation and often rely on mixed-precision fallbacks. In this paper, we systematically investigate hardware-supported FP4 training and introduce Quartet, a new approach enabling accurate, end-to-end FP4 training with all the major computations (in e.g. linear layers) being performed in low precision. Through extensive evaluations on Llama-type models, we reveal a new low-precision scaling law that quantifies performance trade-offs across varying bit-widths and allows us to identify a "near-optimal" low-precision training technique in terms of accuracy-vs-computation, called Quartet. We implement Quartet using optimized CUDA kernels tailored for NVIDIA Blackwell GPUs, and show that it can achieve state-of-the-art accuracy for FP4 precision, successfully training billion-scale models. Our method demonstrates that fully FP4-based training is a competitive alternative to standard-precision and FP8 training. Our code is available at https://github.com/IST-DASLab/Quartet.
QuEST: Stable Training of LLMs with 1-Bit Weights and Activations
Feb 07, 2025



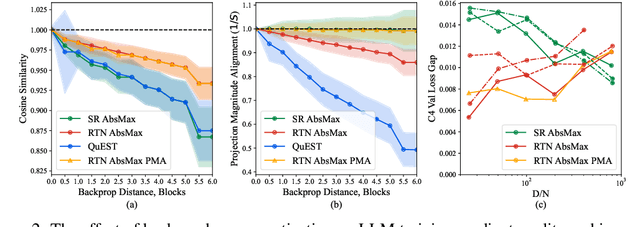
One approach to reducing the massive costs of large language models (LLMs) is the use of quantized or sparse representations for training or deployment. While post-training compression methods are very popular, the question of obtaining even more accurate compressed models by directly training over such representations, i.e., Quantization-Aware Training (QAT), is still open: for example, a recent study (arXiv:2411.04330v2) put the "optimal" bit-width at which models can be trained using QAT, while staying accuracy-competitive with standard FP16/BF16 precision, at 8-bits weights and activations. We advance this state-of-the-art via a new method called QuEST, which is Pareto-competitive with FP16, i.e., it provides better accuracy at lower model size, while training models with weights and activations in 4-bits or less. Moreover, QuEST allows stable training with 1-bit weights and activations. QuEST achieves this by improving two key aspects of QAT methods: (1) accurate and fast quantization of the (continuous) distributions of weights and activations via Hadamard normalization and MSE-optimal fitting; (2) a new trust gradient estimator based on the idea of explicitly minimizing the error between the noisy gradient computed over quantized states and the "true" (but unknown) full-precision gradient. Experiments on Llama-type architectures show that QuEST induces stable scaling laws across the entire range of hardware-supported precisions, and can be extended to sparse representations. We provide GPU kernel support showing that models produced by QuEST can be executed efficiently. Our code is available at https://github.com/IST-DASLab/QuEST.
HALO: Hadamard-Assisted Lossless Optimization for Efficient Low-Precision LLM Training and Fine-Tuning
Jan 05, 2025



Quantized training of Large Language Models (LLMs) remains an open challenge, as maintaining accuracy while performing all matrix multiplications in low precision has proven difficult. This is particularly the case when fine-tuning pre-trained models, which often already have large weight and activation outlier values that render quantized optimization difficult. We present HALO, a novel quantization-aware training approach for Transformers that enables accurate and efficient low-precision training by combining 1) strategic placement of Hadamard rotations in both forward and backward passes, to mitigate outliers during the low-precision computation, 2) FSDP integration for low-precision communication, and 3) high-performance kernel support. Our approach ensures that all large matrix multiplications during the forward and backward passes are executed in lower precision. Applied to LLAMA-family models, HALO achieves near-full-precision-equivalent results during fine-tuning on various tasks, while delivering up to 1.31x end-to-end speedup for full fine-tuning on RTX 4090 GPUs. Our method supports both standard and parameter-efficient fine-tuning (PEFT) methods, both backed by efficient kernel implementations. Our results demonstrate the first practical approach to fully quantized LLM fine-tuning that maintains accuracy in FP8 precision, while delivering performance benefits.
RoSA: Accurate Parameter-Efficient Fine-Tuning via Robust Adaptation
Jan 12, 2024



We investigate parameter-efficient fine-tuning (PEFT) methods that can provide good accuracy under limited computational and memory budgets in the context of large language models (LLMs). We present a new PEFT method called Robust Adaptation (RoSA) inspired by robust principal component analysis (PCA) that jointly trains $\textit{low-rank}$ and $\textit{highly-sparse}$ components on top of a set of fixed pretrained weights to efficiently approximate the performance of a full-fine-tuning (FFT) solution. Across a series of challenging generative tasks such as grade-school math and SQL query generation, which require fine-tuning for good performance, we show that RoSA outperforms both LoRA and pure sparse fine-tuning, at the same parameter budget. We provide system support for RoSA to complement the training algorithm, specifically in the form of sparse GPU kernels which enable memory- and computationally-efficient training. Our code will be made available at https://github.com/IST-DASLab/RoSA.
SparseProp: Efficient Sparse Backpropagation for Faster Training of Neural Networks
Feb 09, 2023
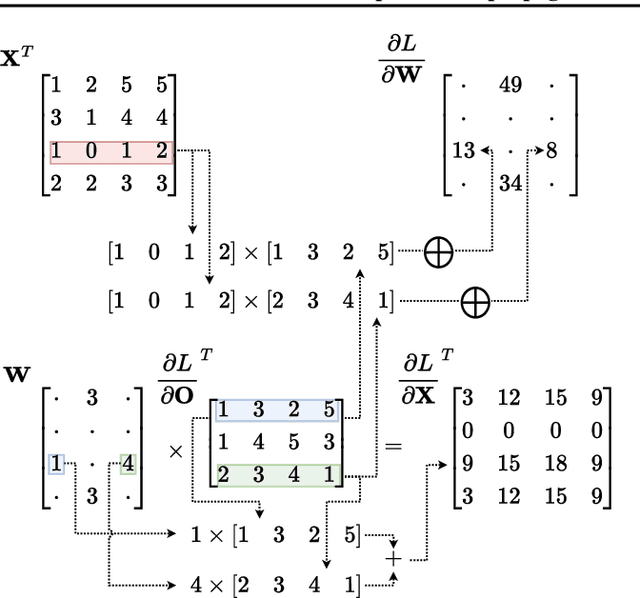
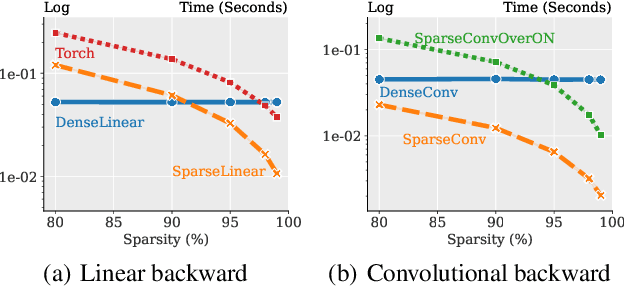

We provide a new efficient version of the backpropagation algorithm, specialized to the case where the weights of the neural network being trained are sparse. Our algorithm is general, as it applies to arbitrary (unstructured) sparsity and common layer types (e.g., convolutional or linear). We provide a fast vectorized implementation on commodity CPUs, and show that it can yield speedups in end-to-end runtime experiments, both in transfer learning using already-sparsified networks, and in training sparse networks from scratch. Thus, our results provide the first support for sparse training on commodity hardware.