 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQIGen: Generating Efficient Kernels for Quantized Inference on Large Language Models
Jul 07, 2023


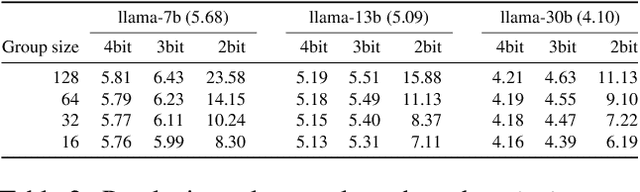
We present ongoing work on a new automatic code generation approach for supporting quantized generative inference on LLMs such as LLaMA or OPT on off-the-shelf CPUs. Our approach is informed by the target architecture and a performance model, including both hardware characteristics and method-specific accuracy constraints. Results on CPU-based inference for LLaMA models show that our approach can lead to high performance and high accuracy, comparing favorably to the best existing open-source solution. A preliminary implementation is available at https://github.com/IST-DASLab/QIGen.
SparseProp: Efficient Sparse Backpropagation for Faster Training of Neural Networks
Feb 09, 2023
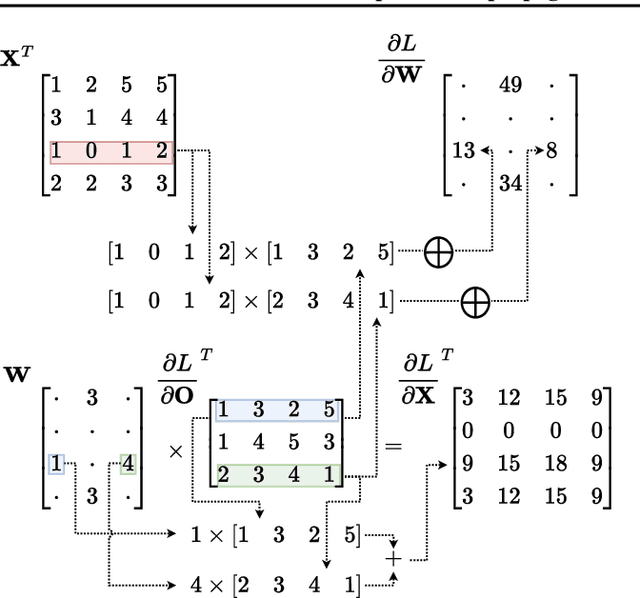
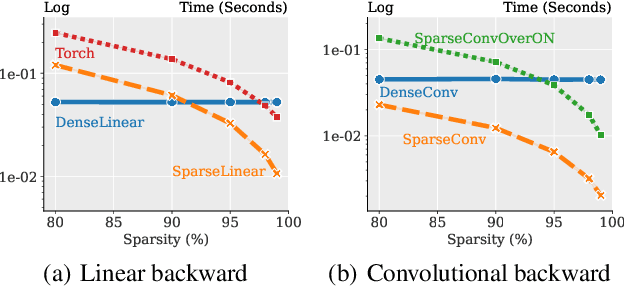

We provide a new efficient version of the backpropagation algorithm, specialized to the case where the weights of the neural network being trained are sparse. Our algorithm is general, as it applies to arbitrary (unstructured) sparsity and common layer types (e.g., convolutional or linear). We provide a fast vectorized implementation on commodity CPUs, and show that it can yield speedups in end-to-end runtime experiments, both in transfer learning using already-sparsified networks, and in training sparse networks from scratch. Thus, our results provide the first support for sparse training on commodity hardware.