 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehemoth: Benchmarking Unlearning in LLMs Using Fully Synthetic Data
Jan 30, 2026As artificial neural networks, and specifically large language models, have improved rapidly in capabilities and quality, they have increasingly been deployed in real-world applications, from customer service to Google search, despite the fact that they frequently make factually incorrect or undesirable statements. This trend has inspired practical and academic interest in model editing, that is, in adjusting the weights of the model to modify its likely outputs for queries relating to a specific fact or set of facts. This may be done either to amend a fact or set of facts, for instance, to fix a frequent error in the training data, or to suppress a fact or set of facts entirely, for instance, in case of dangerous knowledge. Multiple methods have been proposed to do such edits. However, at the same time, it has been shown that such model editing can be brittle and incomplete. Moreover the effectiveness of any model editing method necessarily depends on the data on which the model is trained, and, therefore, a good understanding of the interaction of the training data distribution and the way it is stored in the network is necessary and helpful to reliably perform model editing. However, working with large language models trained on real-world data does not allow us to understand this relationship or fully measure the effects of model editing. We therefore propose Behemoth, a fully synthetic data generation framework. To demonstrate the practical insights from the framework, we explore model editing in the context of simple tabular data, demonstrating surprising findings that, in some cases, echo real-world results, for instance, that in some cases restricting the update rank results in a more effective update. The code is available at https://github.com/IST-DASLab/behemoth.git.
Position: It's Time to Act on the Risk of Efficient Personalized Text Generation
Feb 10, 2025The recent surge in high-quality open-sourced Generative AI text models (colloquially: LLMs), as well as efficient finetuning techniques, has opened the possibility of creating high-quality personalized models, i.e., models generating text attuned to a specific individual's needs and capable of credibly imitating their writing style by leveraging that person's own data to refine an open-source model. The technology to create such models is accessible to private individuals, and training and running such models can be done cheaply on consumer-grade hardware. These advancements are a huge gain for usability and privacy. This position paper argues, however, that these advancements also introduce new safety risks by making it practically feasible for malicious actors to impersonate specific individuals at scale, for instance for the purpose of phishing emails, based on small amounts of publicly available text. We further argue that these risks are complementary to - and distinct from - the much-discussed risks of other impersonation attacks such as image, voice, or video deepfakes, and are not adequately addressed by the larger research community, or the current generation of open - and closed-source models.
Hacking Generative Models with Differentiable Network Bending
Oct 07, 2023



In this work, we propose a method to 'hack' generative models, pushing their outputs away from the original training distribution towards a new objective. We inject a small-scale trainable module between the intermediate layers of the model and train it for a low number of iterations, keeping the rest of the network frozen. The resulting output images display an uncanny quality, given by the tension between the original and new objectives that can be exploited for artistic purposes.
SPADE: Sparsity-Guided Debugging for Deep Neural Networks
Oct 06, 2023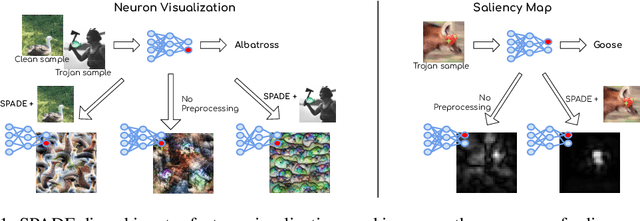
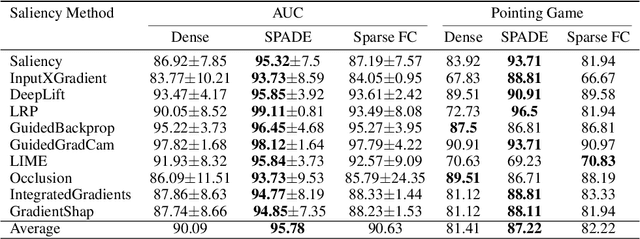

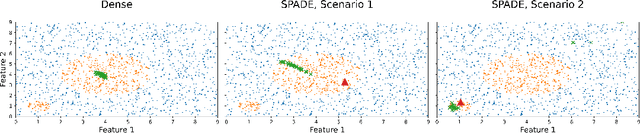
Interpretability, broadly defined as mechanisms for understanding why and how machine learning models reach their decisions, is one of the key open goals at the intersection of deep learning theory and practice. Towards this goal, multiple tools have been proposed to aid a human examiner in reasoning about a network's behavior in general or on a set of instances. However, the outputs of these tools-such as input saliency maps or neuron visualizations-are frequently difficult for a human to interpret, or even misleading, due, in particular, to the fact that neurons can be multifaceted, i.e., a single neuron can be associated with multiple distinct feature combinations. In this paper, we present a new general approach to address this problem, called SPADE, which, given a trained model and a target sample, uses sample-targeted pruning to provide a "trace" of the network's execution on the sample, reducing the network to the connections that are most relevant to the specific prediction. We demonstrate that preprocessing with SPADE significantly increases both the accuracy of image saliency maps across several interpretability methods and the usefulness of neuron visualizations, aiding humans in reasoning about network behavior. Our findings show that sample-specific pruning of connections can disentangle multifaceted neurons, leading to consistently improved interpretability.
Accurate Neural Network Pruning Requires Rethinking Sparse Optimization
Aug 03, 2023Obtaining versions of deep neural networks that are both highly-accurate and highly-sparse is one of the main challenges in the area of model compression, and several high-performance pruning techniques have been investigated by the community. Yet, much less is known about the interaction between sparsity and the standard stochastic optimization techniques used for training sparse networks, and most existing work uses standard dense schedules and hyperparameters for training sparse networks. In this work, we examine the impact of high sparsity on model training using the standard computer vision and natural language processing sparsity benchmarks. We begin by showing that using standard dense training recipes for sparse training is suboptimal, and results in under-training. We provide new approaches for mitigating this issue for both sparse pre-training of vision models (e.g. ResNet50/ImageNet) and sparse fine-tuning of language models (e.g. BERT/GLUE), achieving state-of-the-art results in both settings in the high-sparsity regime, and providing detailed analyses for the difficulty of sparse training in both scenarios. Our work sets a new threshold in terms of the accuracies that can be achieved under high sparsity, and should inspire further research into improving sparse model training, to reach higher accuracies under high sparsity, but also to do so efficiently.
Bias in Pruned Vision Models: In-Depth Analysis and Countermeasures
Apr 25, 2023Pruning - that is, setting a significant subset of the parameters of a neural network to zero - is one of the most popular methods of model compression. Yet, several recent works have raised the issue that pruning may induce or exacerbate bias in the output of the compressed model. Despite existing evidence for this phenomenon, the relationship between neural network pruning and induced bias is not well-understood. In this work, we systematically investigate and characterize this phenomenon in Convolutional Neural Networks for computer vision. First, we show that it is in fact possible to obtain highly-sparse models, e.g. with less than 10% remaining weights, which do not decrease in accuracy nor substantially increase in bias when compared to dense models. At the same time, we also find that, at higher sparsities, pruned models exhibit higher uncertainty in their outputs, as well as increased correlations, which we directly link to increased bias. We propose easy-to-use criteria which, based only on the uncompressed model, establish whether bias will increase with pruning, and identify the samples most susceptible to biased predictions post-compression.
SparseProp: Efficient Sparse Backpropagation for Faster Training of Neural Networks
Feb 09, 2023
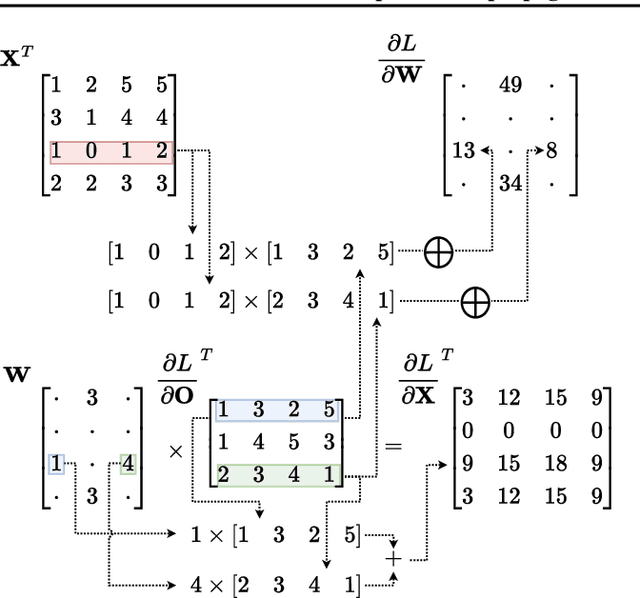
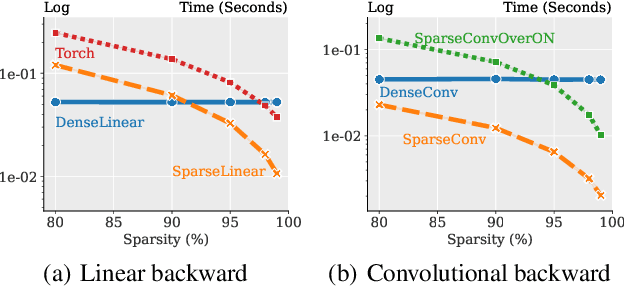

We provide a new efficient version of the backpropagation algorithm, specialized to the case where the weights of the neural network being trained are sparse. Our algorithm is general, as it applies to arbitrary (unstructured) sparsity and common layer types (e.g., convolutional or linear). We provide a fast vectorized implementation on commodity CPUs, and show that it can yield speedups in end-to-end runtime experiments, both in transfer learning using already-sparsified networks, and in training sparse networks from scratch. Thus, our results provide the first support for sparse training on commodity hardware.
How Well Do Sparse Imagenet Models Transfer?
Dec 23, 2021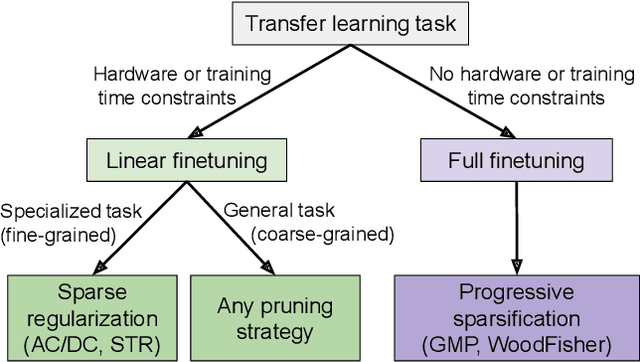

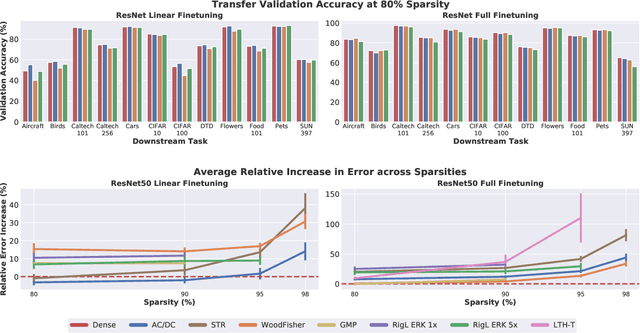
Transfer learning is a classic paradigm by which models pretrained on large "upstream" datasets are adapted to yield good results on "downstream," specialized datasets. Generally, it is understood that more accurate models on the "upstream" dataset will provide better transfer accuracy "downstream". In this work, we perform an in-depth investigation of this phenomenon in the context of convolutional neural networks (CNNs) trained on the ImageNet dataset, which have been pruned - that is, compressed by sparsifiying their connections. Specifically, we consider transfer using unstructured pruned models obtained by applying several state-of-the-art pruning methods, including magnitude-based, second-order, re-growth and regularization approaches, in the context of twelve standard transfer tasks. In a nutshell, our study shows that sparse models can match or even outperform the transfer performance of dense models, even at high sparsities, and, while doing so, can lead to significant inference and even training speedups. At the same time, we observe and analyze significant differences in the behaviour of different pruning methods.
AC/DC: Alternating Compressed/DeCompressed Training of Deep Neural Networks
Jun 23, 2021
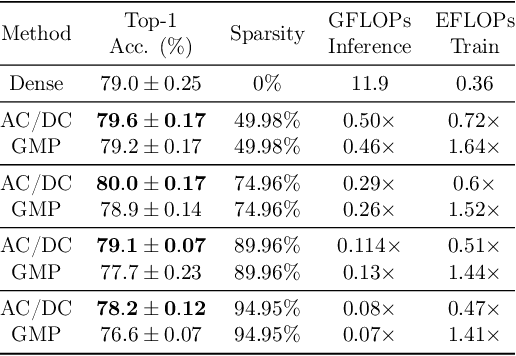
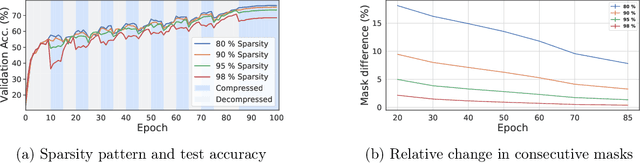
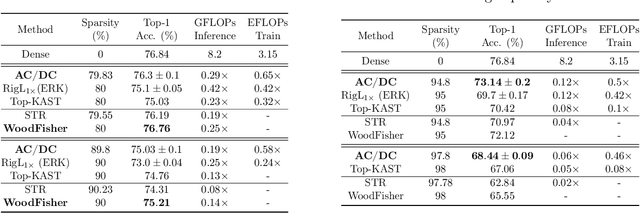
The increasing computational requirements of deep neural networks (DNNs) have led to significant interest in obtaining DNN models that are sparse, yet accurate. Recent work has investigated the even harder case of sparse training, where the DNN weights are, for as much as possible, already sparse to reduce computational costs during training. Existing sparse training methods are mainly empirical and often have lower accuracy relative to the dense baseline. In this paper, we present a general approach called Alternating Compressed/DeCompressed (AC/DC) training of DNNs, demonstrate convergence for a variant of the algorithm, and show that AC/DC outperforms existing sparse training methods in accuracy at similar computational budgets; at high sparsity levels, AC/DC even outperforms existing methods that rely on accurate pre-trained dense models. An important property of AC/DC is that it allows co-training of dense and sparse models, yielding accurate sparse-dense model pairs at the end of the training process. This is useful in practice, where compressed variants may be desirable for deployment in resource-constrained settings without re-doing the entire training flow, and also provides us with insights into the accuracy gap between dense and compressed models.
FLEA: Provably Fair Multisource Learning from Unreliable Training Data
Jun 22, 2021



Fairness-aware learning aims at constructing classifiers that not only make accurate predictions, but do not discriminate against specific groups. It is a fast-growing area of machine learning with far-reaching societal impact. However, existing fair learning methods are vulnerable to accidental or malicious artifacts in the training data, which can cause them to unknowingly produce unfair classifiers. In this work we address the problem of fair learning from unreliable training data in the robust multisource setting, where the available training data comes from multiple sources, a fraction of which might be not representative of the true data distribution. We introduce FLEA, a filtering-based algorithm that allows the learning system to identify and suppress those data sources that would have a negative impact on fairness or accuracy if they were used for training. We show the effectiveness of our approach by a diverse range of experiments on multiple datasets. Additionally we prove formally that, given enough data, FLEA protects the learner against unreliable data as long as the fraction of affected data sources is less than half.