 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPADE: Sparsity-Guided Debugging for Deep Neural Networks
Paper and Code
Oct 06, 2023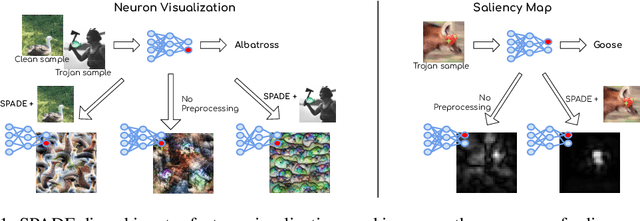
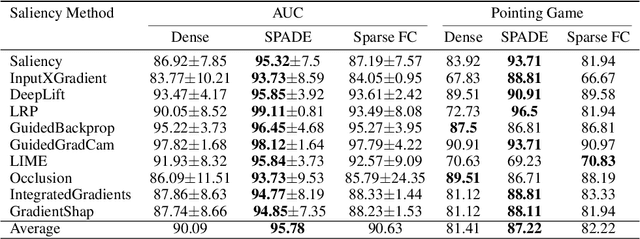

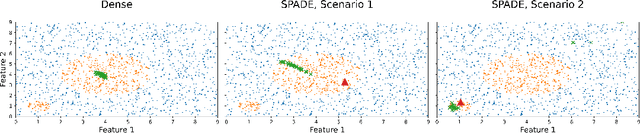
Interpretability, broadly defined as mechanisms for understanding why and how machine learning models reach their decisions, is one of the key open goals at the intersection of deep learning theory and practice. Towards this goal, multiple tools have been proposed to aid a human examiner in reasoning about a network's behavior in general or on a set of instances. However, the outputs of these tools-such as input saliency maps or neuron visualizations-are frequently difficult for a human to interpret, or even misleading, due, in particular, to the fact that neurons can be multifaceted, i.e., a single neuron can be associated with multiple distinct feature combinations. In this paper, we present a new general approach to address this problem, called SPADE, which, given a trained model and a target sample, uses sample-targeted pruning to provide a "trace" of the network's execution on the sample, reducing the network to the connections that are most relevant to the specific prediction. We demonstrate that preprocessing with SPADE significantly increases both the accuracy of image saliency maps across several interpretability methods and the usefulness of neuron visualizations, aiding humans in reasoning about network behavior. Our findings show that sample-specific pruning of connections can disentangle multifaceted neurons, leading to consistently improved interpretability.