 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDarwinLM: Evolutionary Structured Pruning of Large Language Models
Feb 11, 2025



Large Language Models (LLMs) have achieved significant success across various NLP tasks. However, their massive computational costs limit their widespread use, particularly in real-time applications. Structured pruning offers an effective solution by compressing models and directly providing end-to-end speed improvements, regardless of the hardware environment. Meanwhile, different components of the model exhibit varying sensitivities towards pruning, calling for \emph{non-uniform} model compression. However, a pruning method should not only identify a capable substructure, but also account for post-compression training. To this end, we propose \sysname, a method for \emph{training-aware} structured pruning. \sysname builds upon an evolutionary search process, generating multiple offspring models in each generation through mutation, and selecting the fittest for survival. To assess the effect of post-training, we incorporate a lightweight, multistep training process within the offspring population, progressively increasing the number of tokens and eliminating poorly performing models in each selection stage. We validate our method through extensive experiments on Llama-2-7B, Llama-3.1-8B and Qwen-2.5-14B-Instruct, achieving state-of-the-art performance for structured pruning. For instance, \sysname surpasses ShearedLlama while requiring $5\times$ less training data during post-compression training.
"Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization
Nov 04, 2024



Despite the popularity of large language model (LLM) quantization for inference acceleration, significant uncertainty remains regarding the accuracy-performance trade-offs associated with various quantization formats. We present a comprehensive empirical study of quantized accuracy, evaluating popular quantization formats (FP8, INT8, INT4) across academic benchmarks and real-world tasks, on the entire Llama-3.1 model family. Additionally, our study examines the difference in text generated by quantized models versus their uncompressed counterparts. Beyond benchmarks, we also present a couple of quantization improvements which allowed us to obtain state-of-the-art accuracy recovery results. Our investigation, encompassing over 500,000 individual evaluations, yields several key findings: (1) FP8 weight and activation quantization (W8A8-FP) is lossless across all model scales, (2) INT8 weight and activation quantization (W8A8-INT), when properly tuned, incurs surprisingly low 1-3% accuracy degradation, and (3) INT4 weight-only quantization (W4A16-INT) is competitive with 8-bit integer weight and activation quantization. To address the question of the "best" format for a given deployment environment, we conduct inference performance analysis using the popular open-source vLLM framework on various GPU architectures. We find that W4A16 offers the best cost-efficiency for synchronous deployments, and for asynchronous deployment on mid-tier GPUs. At the same time, W8A8 formats excel in asynchronous "continuous batching" deployment of mid- and large-size models on high-end GPUs. Our results provide a set of practical guidelines for deploying quantized LLMs across scales and performance requirements.
EvoPress: Towards Optimal Dynamic Model Compression via Evolutionary Search
Oct 18, 2024



The high computational costs of large language models (LLMs) have led to a flurry of research on LLM compression, via methods such as quantization, sparsification, or structured pruning. A new frontier in this area is given by \emph{dynamic, non-uniform} compression methods, which adjust the compression levels (e.g., sparsity) per-block or even per-layer in order to minimize accuracy loss, while guaranteeing a global compression threshold. Yet, current methods rely on heuristics for identifying the "importance" of a given layer towards the loss, based on assumptions such as \emph{error monotonicity}, i.e. that the end-to-end model compression error is proportional to the sum of layer-wise errors. In this paper, we revisit this area, and propose a new and general approach for dynamic compression that is provably optimal in a given input range. We begin from the motivating observation that, in general, \emph{error monotonicity does not hold for LLMs}: compressed models with lower sum of per-layer errors can perform \emph{worse} than models with higher error sums. To address this, we propose a new general evolutionary framework for dynamic LLM compression called EvoPress, which has provable convergence, and low sample and evaluation complexity. We show that these theoretical guarantees lead to highly competitive practical performance for dynamic compression of Llama, Mistral and Phi models. Via EvoPress, we set new state-of-the-art results across all compression approaches: structural pruning (block/layer dropping), unstructured sparsity, as well as quantization with dynamic bitwidths. Our code is available at https://github.com/IST-DASLab/EvoPress.
Mathador-LM: A Dynamic Benchmark for Mathematical Reasoning on Large Language Models
Jun 18, 2024We introduce Mathador-LM, a new benchmark for evaluating the mathematical reasoning on large language models (LLMs), combining ruleset interpretation, planning, and problem-solving. This benchmark is inspired by the Mathador game, where the objective is to reach a target number using basic arithmetic operations on a given set of base numbers, following a simple set of rules. We show that, across leading LLMs, we obtain stable average performance while generating benchmark instances dynamically, following a target difficulty level. Thus, our benchmark alleviates concerns about test-set leakage into training data, an issue that often undermines popular benchmarks. Additionally, we conduct a comprehensive evaluation of both open and closed-source state-of-the-art LLMs on Mathador-LM. Our findings reveal that contemporary models struggle with Mathador-LM, scoring significantly lower than average 5th graders. This stands in stark contrast to their strong performance on popular mathematical reasoning benchmarks.
MicroAdam: Accurate Adaptive Optimization with Low Space Overhead and Provable Convergence
May 24, 2024We propose a new variant of the Adam optimizer [Kingma and Ba, 2014] called MICROADAM that specifically minimizes memory overheads, while maintaining theoretical convergence guarantees. We achieve this by compressing the gradient information before it is fed into the optimizer state, thereby reducing its memory footprint significantly. We control the resulting compression error via a novel instance of the classical error feedback mechanism from distributed optimization [Seide et al., 2014, Alistarh et al., 2018, Karimireddy et al., 2019] in which the error correction information is itself compressed to allow for practical memory gains. We prove that the resulting approach maintains theoretical convergence guarantees competitive to those of AMSGrad, while providing good practical performance. Specifically, we show that MICROADAM can be implemented efficiently on GPUs: on both million-scale (BERT) and billion-scale (LLaMA) models, MicroAdam provides practical convergence competitive to that of the uncompressed Adam baseline, with lower memory usage and similar running time. Our code is available at https://github.com/IST-DASLab/MicroAdam.
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
May 06, 2024Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
How to Prune Your Language Model: Recovering Accuracy on the "Sparsity May Cry'' Benchmark
Dec 21, 2023Pruning large language models (LLMs) from the BERT family has emerged as a standard compression benchmark, and several pruning methods have been proposed for this task. The recent ``Sparsity May Cry'' (SMC) benchmark put into question the validity of all existing methods, exhibiting a more complex setup where many known pruning methods appear to fail. We revisit the question of accurate BERT-pruning during fine-tuning on downstream datasets, and propose a set of general guidelines for successful pruning, even on the challenging SMC benchmark. First, we perform a cost-vs-benefits analysis of pruning model components, such as the embeddings and the classification head; second, we provide a simple-yet-general way of scaling training, sparsification and learning rate schedules relative to the desired target sparsity; finally, we investigate the importance of proper parametrization for Knowledge Distillation in the context of LLMs. Our simple insights lead to state-of-the-art results, both on classic BERT-pruning benchmarks, as well as on the SMC benchmark, showing that even classic gradual magnitude pruning (GMP) can yield competitive results, with the right approach.
Sparse Fine-tuning for Inference Acceleration of Large Language Models
Oct 13, 2023We consider the problem of accurate sparse fine-tuning of large language models (LLMs), that is, fine-tuning pretrained LLMs on specialized tasks, while inducing sparsity in their weights. On the accuracy side, we observe that standard loss-based fine-tuning may fail to recover accuracy, especially at high sparsities. To address this, we perform a detailed study of distillation-type losses, determining an L2-based distillation approach we term SquareHead which enables accurate recovery even at higher sparsities, across all model types. On the practical efficiency side, we show that sparse LLMs can be executed with speedups by taking advantage of sparsity, for both CPU and GPU runtimes. While the standard approach is to leverage sparsity for computational reduction, we observe that in the case of memory-bound LLMs sparsity can also be leveraged for reducing memory bandwidth. We exhibit end-to-end results showing speedups due to sparsity, while recovering accuracy, on T5 (language translation), Whisper (speech translation), and open GPT-type (MPT for text generation). For MPT text generation, we show for the first time that sparse fine-tuning can reach 75% sparsity without accuracy drops, provide notable end-to-end speedups for both CPU and GPU inference, and highlight that sparsity is also compatible with quantization approaches. Models and software for reproducing our results are provided in Section 6.
Accurate Neural Network Pruning Requires Rethinking Sparse Optimization
Aug 03, 2023Obtaining versions of deep neural networks that are both highly-accurate and highly-sparse is one of the main challenges in the area of model compression, and several high-performance pruning techniques have been investigated by the community. Yet, much less is known about the interaction between sparsity and the standard stochastic optimization techniques used for training sparse networks, and most existing work uses standard dense schedules and hyperparameters for training sparse networks. In this work, we examine the impact of high sparsity on model training using the standard computer vision and natural language processing sparsity benchmarks. We begin by showing that using standard dense training recipes for sparse training is suboptimal, and results in under-training. We provide new approaches for mitigating this issue for both sparse pre-training of vision models (e.g. ResNet50/ImageNet) and sparse fine-tuning of language models (e.g. BERT/GLUE), achieving state-of-the-art results in both settings in the high-sparsity regime, and providing detailed analyses for the difficulty of sparse training in both scenarios. Our work sets a new threshold in terms of the accuracies that can be achieved under high sparsity, and should inspire further research into improving sparse model training, to reach higher accuracies under high sparsity, but also to do so efficiently.
Error Feedback Can Accurately Compress Preconditioners
Jun 16, 2023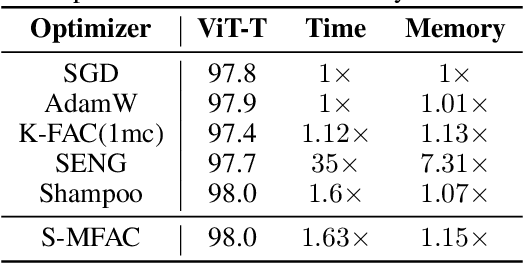
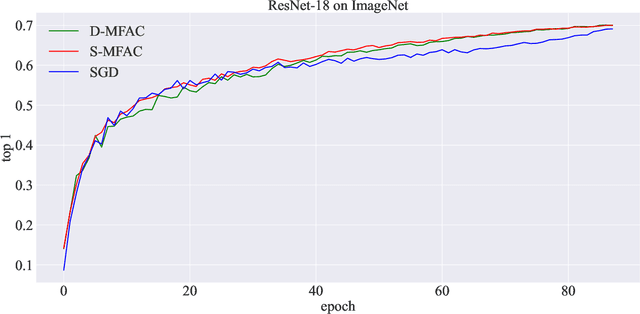
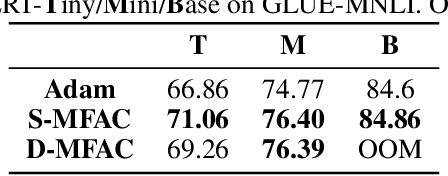
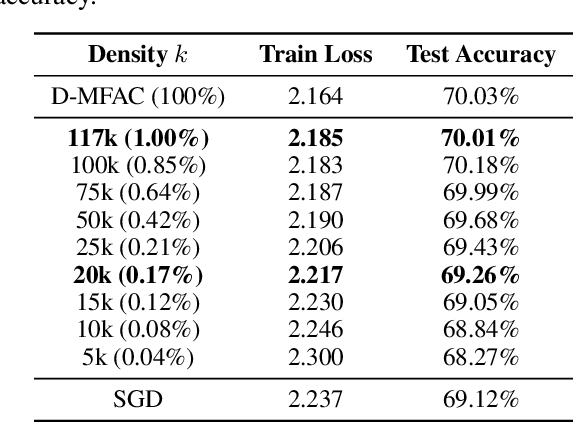
Leveraging second-order information at the scale of deep networks is one of the main lines of approach for improving the performance of current optimizers for deep learning. Yet, existing approaches for accurate full-matrix preconditioning, such as Full-Matrix Adagrad (GGT) or Matrix-Free Approximate Curvature (M-FAC) suffer from massive storage costs when applied even to medium-scale models, as they must store a sliding window of gradients, whose memory requirements are multiplicative in the model dimension. In this paper, we address this issue via an efficient and simple-to-implement error-feedback technique that can be applied to compress preconditioners by up to two orders of magnitude in practice, without loss of convergence. Specifically, our approach compresses the gradient information via sparsification or low-rank compression \emph{before} it is fed into the preconditioner, feeding the compression error back into future iterations. Extensive experiments on deep neural networks for vision show that this approach can compress full-matrix preconditioners by up to two orders of magnitude without impact on accuracy, effectively removing the memory overhead of full-matrix preconditioning for implementations of full-matrix Adagrad (GGT) and natural gradient (M-FAC). Our code is available at https://github.com/IST-DASLab/EFCP.