 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal-Counterfactual RAG: The Integration of Causal-Counterfactual Reasoning into RAG
Sep 17, 2025


Large language models (LLMs) have transformed natural language processing (NLP), enabling diverse applications by integrating large-scale pre-trained knowledge. However, their static knowledge limits dynamic reasoning over external information, especially in knowledge-intensive domains. Retrieval-Augmented Generation (RAG) addresses this challenge by combining retrieval mechanisms with generative modeling to improve contextual understanding. Traditional RAG systems suffer from disrupted contextual integrity due to text chunking and over-reliance on semantic similarity for retrieval, often resulting in shallow and less accurate responses. We propose Causal-Counterfactual RAG, a novel framework that integrates explicit causal graphs representing cause-effect relationships into the retrieval process and incorporates counterfactual reasoning grounded on the causal structure. Unlike conventional methods, our framework evaluates not only direct causal evidence but also the counterfactuality of associated causes, combining results from both to generate more robust, accurate, and interpretable answers. By leveraging causal pathways and associated hypothetical scenarios, Causal-Counterfactual RAG preserves contextual coherence, reduces hallucination, and enhances reasoning fidelity.
$μ$nit Scaling: Simple and Scalable FP8 LLM Training
Feb 09, 2025Large Language Model training with 8-bit floating point (FP8) formats promises significant efficiency improvements, but reduced numerical precision makes training challenging. It is currently possible to train in FP8 only if one is willing to tune various hyperparameters, reduce model scale, or accept the overhead of computing dynamic scale factors. We demonstrate simple, scalable FP8 training that requires no dynamic scaling factors or special hyperparameters, even at large model sizes. Our method, $\mu$nit Scaling ($\mu$S), also enables simple hyperparameter transfer across model widths, matched numerics across training and inference, and other desirable properties. $\mu$nit Scaling is straightforward to implement, consisting of a set of minimal interventions based on a first-principles analysis of common transformer operations. We validate our method by training models from 1B to 13B parameters, performing all hidden linear layer computations in FP8. We achieve quality equal to higher precision baselines while also training up to 33% faster.
AAVENUE: Detecting LLM Biases on NLU Tasks in AAVE via a Novel Benchmark
Aug 27, 2024Detecting biases in natural language understanding (NLU) for African American Vernacular English (AAVE) is crucial to developing inclusive natural language processing (NLP) systems. To address dialect-induced performance discrepancies, we introduce AAVENUE ({AAVE} {N}atural Language {U}nderstanding {E}valuation), a benchmark for evaluating large language model (LLM) performance on NLU tasks in AAVE and Standard American English (SAE). AAVENUE builds upon and extends existing benchmarks like VALUE, replacing deterministic syntactic and morphological transformations with a more flexible methodology leveraging LLM-based translation with few-shot prompting, improving performance across our evaluation metrics when translating key tasks from the GLUE and SuperGLUE benchmarks. We compare AAVENUE and VALUE translations using five popular LLMs and a comprehensive set of metrics including fluency, BARTScore, quality, coherence, and understandability. Additionally, we recruit fluent AAVE speakers to validate our translations for authenticity. Our evaluations reveal that LLMs consistently perform better on SAE tasks than AAVE-translated versions, underscoring inherent biases and highlighting the need for more inclusive NLP models. We have open-sourced our source code on GitHub and created a website to showcase our work at https://aavenue.live.
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
May 06, 2024Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
Sparse Iso-FLOP Transformations for Maximizing Training Efficiency
Mar 25, 2023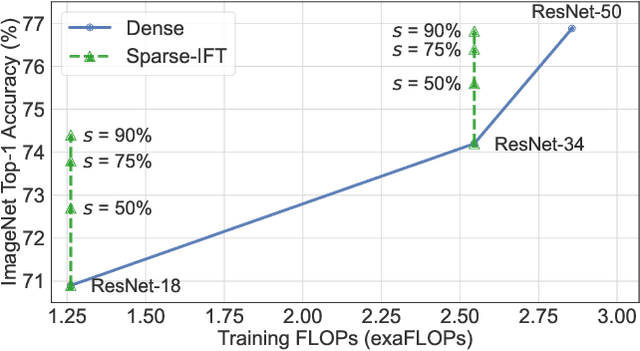
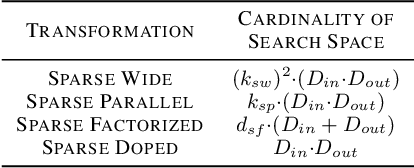
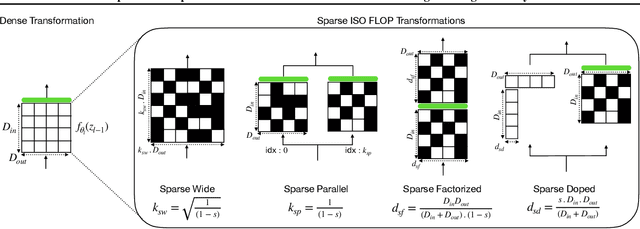
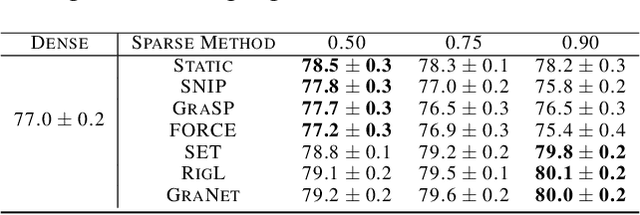
Recent works have explored the use of weight sparsity to improve the training efficiency (test accuracy w.r.t training FLOPs) of deep neural networks (DNNs). These works aim to reduce training FLOPs but training with sparse weights often leads to accuracy loss or requires longer training schedules, making the resulting training efficiency less clear. In contrast, we focus on using sparsity to increase accuracy while using the same FLOPs as the dense model and show training efficiency gains through higher accuracy. In this work, we introduce Sparse-IFT, a family of Sparse Iso-FLOP Transformations which are used as drop-in replacements for dense layers to improve their representational capacity and FLOP efficiency. Each transformation is parameterized by a single hyperparameter (sparsity level) and provides a larger search space to find optimal sparse masks. Without changing any training hyperparameters, replacing dense layers with Sparse-IFT leads to significant improvements across computer vision (CV) and natural language processing (NLP) tasks, including ResNet-18 on ImageNet (+3.5%) and GPT-3 Small on WikiText-103 (-0.4 PPL), both matching larger dense model variants that use 2x or more FLOPs. To our knowledge, this is the first work to demonstrate the use of sparsity for improving the accuracy of dense models via a simple-to-use set of sparse transformations. Code is available at: https://github.com/CerebrasResearch/Sparse-IFT.
SPDF: Sparse Pre-training and Dense Fine-tuning for Large Language Models
Mar 18, 2023

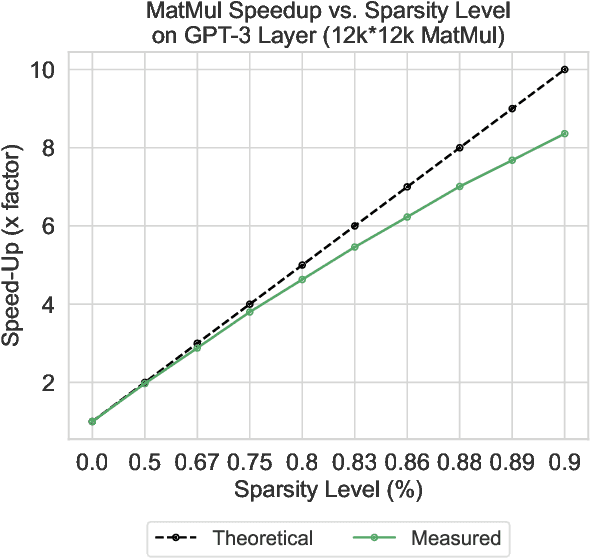
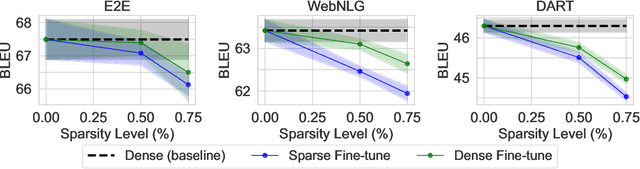
The pre-training and fine-tuning paradigm has contributed to a number of breakthroughs in Natural Language Processing (NLP). Instead of directly training on a downstream task, language models are first pre-trained on large datasets with cross-domain knowledge (e.g., Pile, MassiveText, etc.) and then fine-tuned on task-specific data (e.g., natural language generation, text summarization, etc.). Scaling the model and dataset size has helped improve the performance of LLMs, but unfortunately, this also leads to highly prohibitive computational costs. Pre-training LLMs often require orders of magnitude more FLOPs than fine-tuning and the model capacity often remains the same between the two phases. To achieve training efficiency w.r.t training FLOPs, we propose to decouple the model capacity between the two phases and introduce Sparse Pre-training and Dense Fine-tuning (SPDF). In this work, we show the benefits of using unstructured weight sparsity to train only a subset of weights during pre-training (Sparse Pre-training) and then recover the representational capacity by allowing the zeroed weights to learn (Dense Fine-tuning). We demonstrate that we can induce up to 75% sparsity into a 1.3B parameter GPT-3 XL model resulting in a 2.5x reduction in pre-training FLOPs, without a significant loss in accuracy on the downstream tasks relative to the dense baseline. By rigorously evaluating multiple downstream tasks, we also establish a relationship between sparsity, task complexity, and dataset size. Our work presents a promising direction to train large GPT models at a fraction of the training FLOPs using weight sparsity while retaining the benefits of pre-trained textual representations for downstream tasks.
RevBiFPN: The Fully Reversible Bidirectional Feature Pyramid Network
Jun 28, 2022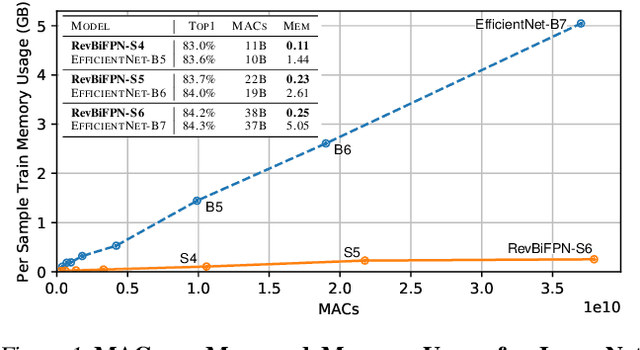
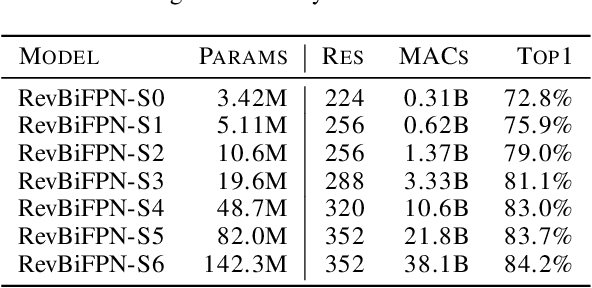
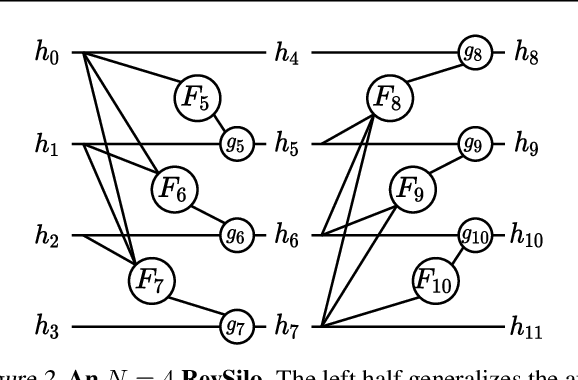
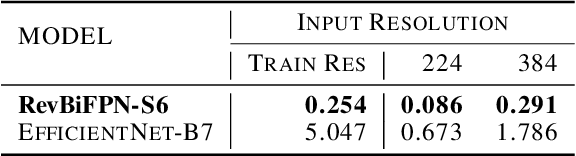
This work introduces the RevSilo, the first reversible module for bidirectional multi-scale feature fusion. Like other reversible methods, RevSilo eliminates the need to store hidden activations by recomputing them. Existing reversible methods, however, do not apply to multi-scale feature fusion and are therefore not applicable to a large class of networks. Bidirectional multi-scale feature fusion promotes local and global coherence and has become a de facto design principle for networks targeting spatially sensitive tasks e.g. HRNet and EfficientDet. When paired with high-resolution inputs, these networks achieve state-of-the-art results across various computer vision tasks, but training them requires substantial accelerator memory for saving large, multi-resolution activations. These memory requirements cap network size and limit progress. Using reversible recomputation, the RevSilo alleviates memory issues while still operating across resolution scales. Stacking RevSilos, we create RevBiFPN, a fully reversible bidirectional feature pyramid network. For classification, RevBiFPN is competitive with networks such as EfficientNet while using up to 19.8x lesser training memory. When fine-tuned on COCO, RevBiFPN provides up to a 2.5% boost in AP over HRNet using fewer MACs and a 2.4x reduction in training-time memory.
DAiSEE: Towards User Engagement Recognition in the Wild
Apr 13, 2018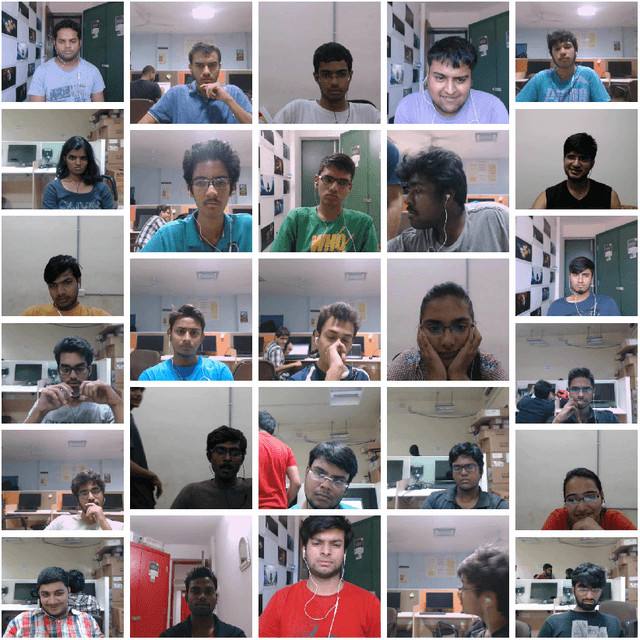

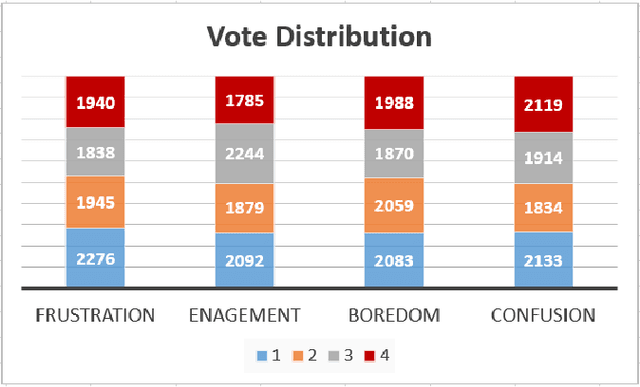
We introduce DAiSEE, the first multi-label video classification dataset comprising of 9068 video snippets captured from 112 users for recognizing the user affective states of boredom, confusion, engagement, and frustration in the wild. The dataset has four levels of labels namely - very low, low, high, and very high for each of the affective states, which are crowd annotated and correlated with a gold standard annotation created using a team of expert psychologists. We have also established benchmark results on this dataset using state-of-the-art video classification methods that are available today. We believe that DAiSEE will provide the research community with challenges in feature extraction, context-based inference, and development of suitable machine learning methods for related tasks, thus providing a springboard for further research. The dataset is available for download at https://iith.ac.in/~daisee-dataset
Approximating Wisdom of Crowds using K-RBMs
Nov 17, 2016
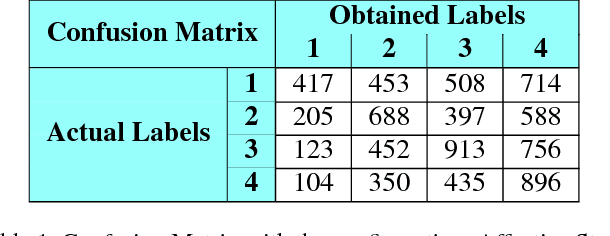
An important way to make large training sets is to gather noisy labels from crowds of non experts. We propose a method to aggregate noisy labels collected from a crowd of workers or annotators. Eliciting labels is important in tasks such as judging web search quality and rating products. Our method assumes that labels are generated by a probability distribution over items and labels. We formulate the method by drawing parallels between Gaussian Mixture Models (GMMs) and Restricted Boltzmann Machines (RBMs) and show that the problem of vote aggregation can be viewed as one of clustering. We use K-RBMs to perform clustering. We finally show some empirical evaluations over real datasets.