 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDREAM-S: Speculative Decoding with Searchable Drafting and Target-Aware Refinement for Multimodal Generation
May 30, 2026Speculative decoding (SD) has proven to be an effective technique for accelerating autoregressive generation in large language models (LLMs) however, its application to vision-language models (VLMs) remains relatively unexplored. We propose~\textit{DREAM-S}, a novel SD framework designed specifically for fast and efficient decoding in VLMs. DREAM-S leverages a neural architecture search (NAS) framework with target-aware supernet training to automatically identify both the optimal interaction strategy between the draft and target models, and the most suitable draft model architecture for the underlying hardware implementation platform. DREAM-S additionally incorporates adaptive intermediate feature distillation, guided by attention entropy, to enable efficient draft training. Experiments on a range of well-established VLMs show that DREAM-S achieves up to a $3.85\times$ speedup compared to standard decoding approaches and significantly outperforms existing SD baselines. The code is publicly available at: https://github.com/SAI-Lab-NYU/DREAM-S .
DREAM-R: Multimodal Speculative Reasoning with RL-Based Refined Drafting, Precise Verification, and Fully Parallel Execution
May 27, 2026Speculative reasoning has recently been proposed as a means to accelerate reasoning-intensive generation in large multimodal models, but its effectiveness is often constrained by misalignment between speculative drafts and target-verified reasoning. In this work, we introduce DREAM-R, a framework that substantially improves the performance of speculative reasoning. At its core, DREAM-R employs Speculative Alignment Policy Optimization (SAPO), a reinforcement-learning objective that trains draft models to generate reasoning steps that are both faithful to target trajectories and concise. We further propose a Threshold-based Verification Mechanism (TBVM) that uses a ratio-based criterion to provide stable and interpretable acceptance of speculative steps only when positive evidence clearly dominates, thereby preventing error propagation. Building on these components, we develop a Fully Parallel Speculative Reasoning (FPSR) framework that parallelizes draft generation, target-side reasoning, and verification across multi-step reasoning, enabling early stopping and clean fallback. Experiments on reasoning-heavy benchmarks demonstrate up to speedup while preserving target-model accuracy, yielding substantial efficiency gains without compromising reasoning quality.
CodeQuant: Unified Clustering and Quantization for Enhanced Outlier Smoothing in Low-Precision Mixture-of-Experts
Apr 12, 2026Outliers have emerged as a fundamental bottleneck in preserving accuracy for low-precision large models, particularly within Mixture-of-Experts (MoE) architectures that are increasingly central to large-scale language modeling. Under post-training quantization (PTQ), these outliers induce substantial quantization errors, leading to severe accuracy degradation. While recent rotation-based smoothing techniques alleviate the problem by redistributing outlier magnitudes, residual errors remain and continue to impede reliable low-precision deployment. In this work, we tackle this challenge by introducing \textit{CodeQuant}, a unified quantization-and-clustering scheme that contains smoothing activation outliers via learnable rotation and absorbing weight outliers into fine-tuned cluster centroids for MoE. This design reduces the influence of extreme values by fitting them within cluster centroids, thereby lowering quantization error while maintaining expressive capacity. Coupled with a dedicated kernel design for GPU and CPU, CodeQuant achieves up to $4.15\times$ speedup while delivering significantly higher accuracy than state-of-the-art quantization approaches across diverse MoE models. Our results highlight CodeQuant as a promising direction for efficient and accurate deployment of MoE-based large language models under low-precision constraints. Our code is available at https://github.com/SAI-Lab-NYU/CodeQuant.
DREAM: Drafting with Refined Target Features and Entropy-Adaptive Cross-Attention Fusion for Multimodal Speculative Decoding
May 25, 2025Speculative decoding (SD) has emerged as a powerful method for accelerating autoregressive generation in large language models (LLMs), yet its integration into vision-language models (VLMs) remains underexplored. We introduce DREAM, a novel speculative decoding framework tailored for VLMs that combines three key innovations: (1) a cross-attention-based mechanism to inject intermediate features from the target model into the draft model for improved alignment, (2) adaptive intermediate feature selection based on attention entropy to guide efficient draft model training, and (3) visual token compression to reduce draft model latency. DREAM enables efficient, accurate, and parallel multimodal decoding with significant throughput improvement. Experiments across a diverse set of recent popular VLMs, including LLaVA, Pixtral, SmolVLM and Gemma3, demonstrate up to 3.6x speedup over conventional decoding and significantly outperform prior SD baselines in both inference throughput and speculative draft acceptance length across a broad range of multimodal benchmarks. The code is publicly available at: https://github.com/SAI-Lab-NYU/DREAM.git
MASSV: Multimodal Adaptation and Self-Data Distillation for Speculative Decoding of Vision-Language Models
May 15, 2025Speculative decoding significantly accelerates language model inference by enabling a lightweight draft model to propose multiple tokens that a larger target model verifies simultaneously. However, applying this technique to vision-language models (VLMs) presents two fundamental challenges: small language models that could serve as efficient drafters lack the architectural components to process visual inputs, and their token predictions fail to match those of VLM target models that consider visual context. We introduce Multimodal Adaptation and Self-Data Distillation for Speculative Decoding of Vision-Language Models (MASSV), which transforms existing small language models into effective multimodal drafters through a two-phase approach. MASSV first connects the target VLM's vision encoder to the draft model via a lightweight trainable projector, then applies self-distilled visual instruction tuning using responses generated by the target VLM to align token predictions. Comprehensive experiments across the Qwen2.5-VL and Gemma3 model families demonstrate that MASSV increases accepted length by up to 30% and delivers end-to-end inference speedups of up to 1.46x on visually-grounded tasks. MASSV provides a scalable, architecture-compatible method for accelerating both current and future VLMs.
SD$^2$: Self-Distilled Sparse Drafters
Apr 10, 2025Speculative decoding is a powerful technique for reducing the latency of Large Language Models (LLMs), offering a fault-tolerant framework that enables the use of highly compressed draft models. In this work, we introduce Self-Distilled Sparse Drafters (SD$^2$), a novel methodology that leverages self-data distillation and fine-grained weight sparsity to produce highly efficient and well-aligned draft models. SD$^2$ systematically enhances draft token acceptance rates while significantly reducing Multiply-Accumulate operations (MACs), even in the Universal Assisted Generation (UAG) setting, where draft and target models originate from different model families. On a Llama-3.1-70B target model, SD$^2$ provides a $\times$1.59 higher Mean Accepted Length (MAL) compared to layer-pruned draft models and reduces MACs by over 43.87% with a 8.36% reduction in MAL compared to a dense draft models. Our results highlight the potential of sparsity-aware fine-tuning and compression strategies to improve LLM inference efficiency while maintaining alignment with target models.
Self-Data Distillation for Recovering Quality in Pruned Large Language Models
Oct 15, 2024Large language models have driven significant progress in natural language processing, but their deployment requires substantial compute and memory resources. As models scale, compression techniques become essential for balancing model quality with computational efficiency. Structured pruning, which removes less critical components of the model, is a promising strategy for reducing complexity. However, one-shot pruning often results in significant quality degradation, particularly in tasks requiring multi-step reasoning. To recover lost quality, supervised fine-tuning (SFT) is commonly applied, but it can lead to catastrophic forgetting by shifting the model's learned data distribution. Therefore, addressing the degradation from both pruning and SFT is essential to preserve the original model's quality. In this work, we propose self-data distilled fine-tuning to address these challenges. Our approach leverages the original, unpruned model to generate a distilled dataset that preserves semantic richness and mitigates catastrophic forgetting by maintaining alignment with the base model's knowledge. Empirically, we demonstrate that self-data distillation consistently outperforms standard SFT, improving average accuracy by up to 8% on the HuggingFace OpenLLM Leaderboard v1. Specifically, when pruning 6 decoder blocks on Llama3.1-8B Instruct (i.e., 32 to 26 layers, reducing the model size from 8.03B to 6.72B parameters), our method retains 91.2% of the original model's accuracy compared to 81.7% with SFT, while reducing real-world FLOPs by 16.30%. Furthermore, our approach scales effectively across datasets, with the quality improving as the dataset size increases.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
MediSwift: Efficient Sparse Pre-trained Biomedical Language Models
Mar 01, 2024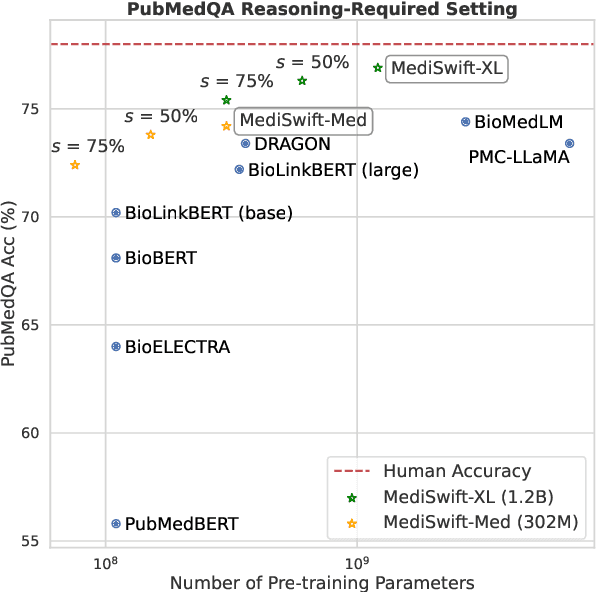
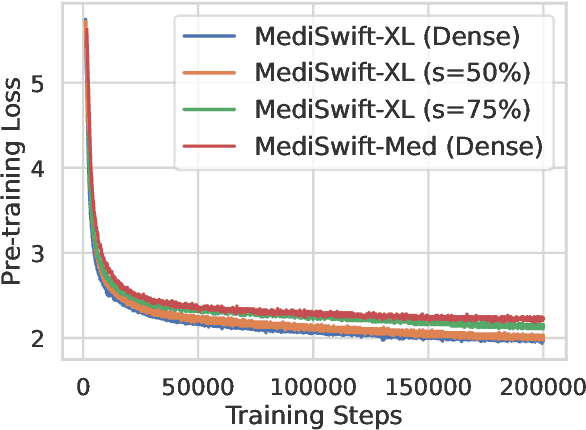
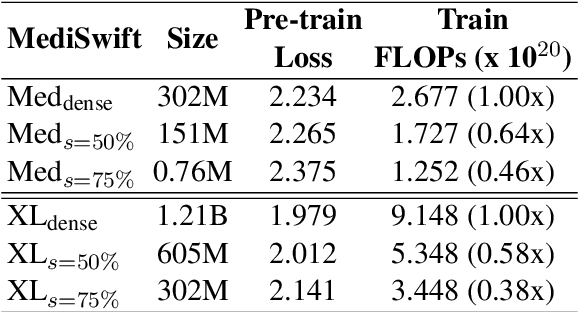
Large language models (LLMs) are typically trained on general source data for various domains, but a recent surge in domain-specific LLMs has shown their potential to outperform general-purpose models in domain-specific tasks (e.g., biomedicine). Although domain-specific pre-training enhances efficiency and leads to smaller models, the computational costs of training these LLMs remain high, posing budgeting challenges. We introduce MediSwift, a suite of biomedical LMs that leverage sparse pre-training on domain-specific biomedical text data. By inducing up to 75% weight sparsity during the pre-training phase, MediSwift achieves a 2-2.5x reduction in training FLOPs. Notably, all sparse pre-training was performed on the Cerebras CS-2 system, which is specifically designed to realize the acceleration benefits from unstructured weight sparsity, thereby significantly enhancing the efficiency of the MediSwift models. Through subsequent dense fine-tuning and strategic soft prompting, MediSwift models outperform existing LLMs up to 7B parameters on biomedical tasks, setting new benchmarks w.r.t efficiency-accuracy on tasks such as PubMedQA. Our results show that sparse pre-training, along with dense fine-tuning and soft prompting, offers an effective method for creating high-performing, computationally efficient models in specialized domains.
Sparse Iso-FLOP Transformations for Maximizing Training Efficiency
Mar 25, 2023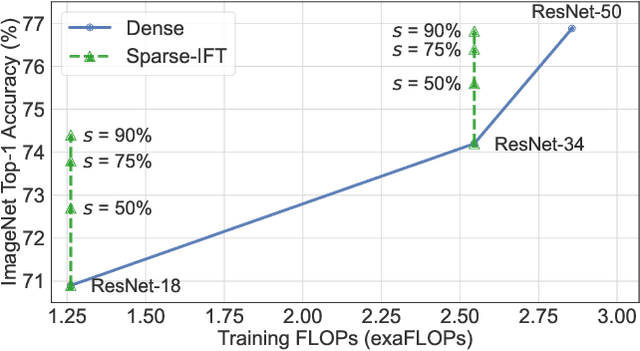
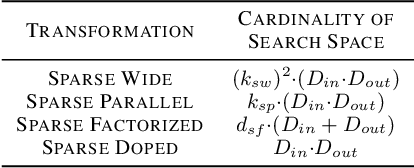
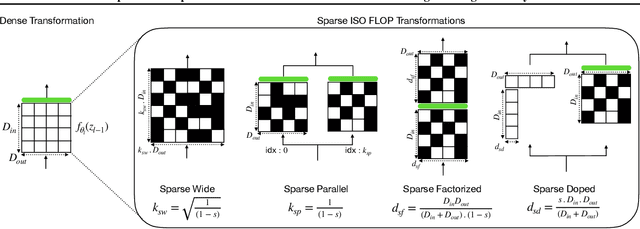
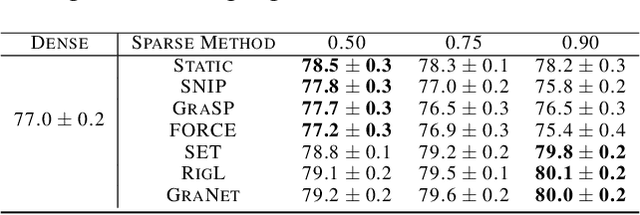
Recent works have explored the use of weight sparsity to improve the training efficiency (test accuracy w.r.t training FLOPs) of deep neural networks (DNNs). These works aim to reduce training FLOPs but training with sparse weights often leads to accuracy loss or requires longer training schedules, making the resulting training efficiency less clear. In contrast, we focus on using sparsity to increase accuracy while using the same FLOPs as the dense model and show training efficiency gains through higher accuracy. In this work, we introduce Sparse-IFT, a family of Sparse Iso-FLOP Transformations which are used as drop-in replacements for dense layers to improve their representational capacity and FLOP efficiency. Each transformation is parameterized by a single hyperparameter (sparsity level) and provides a larger search space to find optimal sparse masks. Without changing any training hyperparameters, replacing dense layers with Sparse-IFT leads to significant improvements across computer vision (CV) and natural language processing (NLP) tasks, including ResNet-18 on ImageNet (+3.5%) and GPT-3 Small on WikiText-103 (-0.4 PPL), both matching larger dense model variants that use 2x or more FLOPs. To our knowledge, this is the first work to demonstrate the use of sparsity for improving the accuracy of dense models via a simple-to-use set of sparse transformations. Code is available at: https://github.com/CerebrasResearch/Sparse-IFT.