 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevBiFPN: The Fully Reversible Bidirectional Feature Pyramid Network
Jun 28, 2022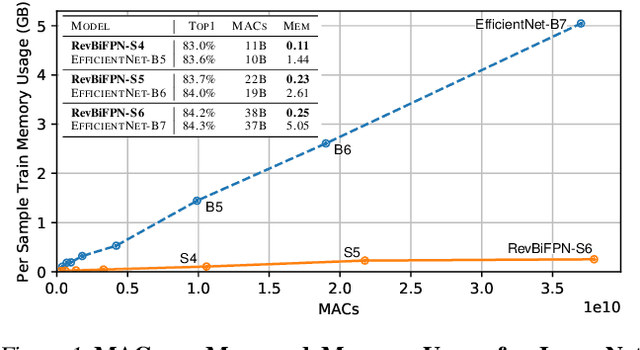
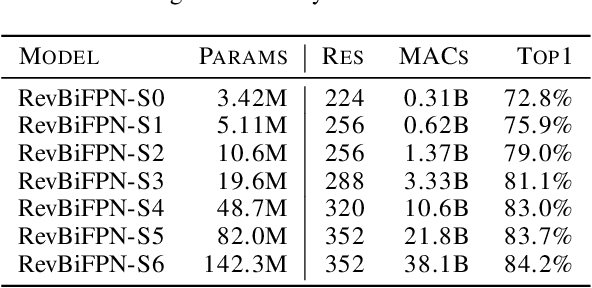
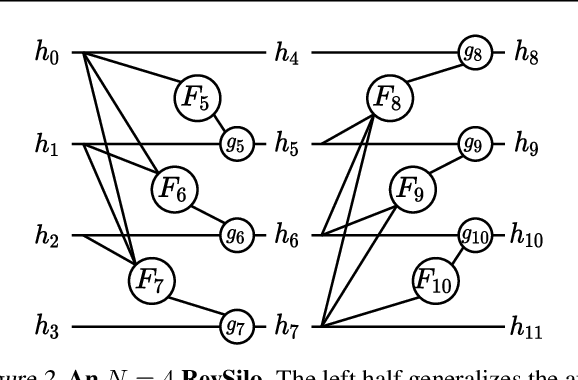
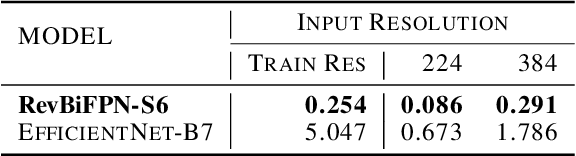
This work introduces the RevSilo, the first reversible module for bidirectional multi-scale feature fusion. Like other reversible methods, RevSilo eliminates the need to store hidden activations by recomputing them. Existing reversible methods, however, do not apply to multi-scale feature fusion and are therefore not applicable to a large class of networks. Bidirectional multi-scale feature fusion promotes local and global coherence and has become a de facto design principle for networks targeting spatially sensitive tasks e.g. HRNet and EfficientDet. When paired with high-resolution inputs, these networks achieve state-of-the-art results across various computer vision tasks, but training them requires substantial accelerator memory for saving large, multi-resolution activations. These memory requirements cap network size and limit progress. Using reversible recomputation, the RevSilo alleviates memory issues while still operating across resolution scales. Stacking RevSilos, we create RevBiFPN, a fully reversible bidirectional feature pyramid network. For classification, RevBiFPN is competitive with networks such as EfficientNet while using up to 19.8x lesser training memory. When fine-tuned on COCO, RevBiFPN provides up to a 2.5% boost in AP over HRNet using fewer MACs and a 2.4x reduction in training-time memory.
Tile2Vec: Unsupervised representation learning for spatially distributed data
May 30, 2018



Geospatial analysis lacks methods like the word vector representations and pre-trained networks that significantly boost performance across a wide range of natural language and computer vision tasks. To fill this gap, we introduce Tile2Vec, an unsupervised representation learning algorithm that extends the distributional hypothesis from natural language -- words appearing in similar contexts tend to have similar meanings -- to spatially distributed data. We demonstrate empirically that Tile2Vec learns semantically meaningful representations on three datasets. Our learned representations significantly improve performance in downstream classification tasks and, similar to word vectors, visual analogies can be obtained via simple arithmetic in the latent space.