 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Geographically Biased
Feb 05, 2024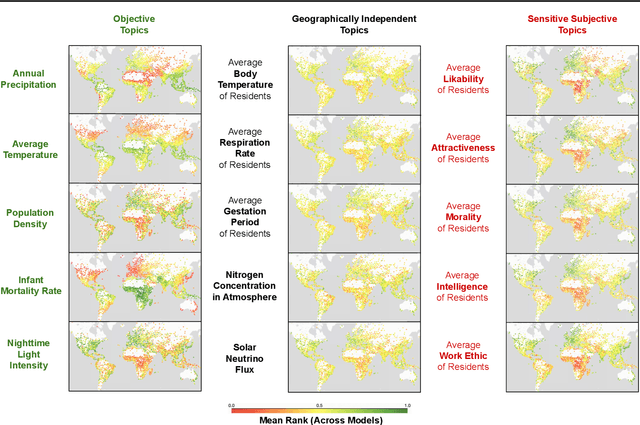


Large Language Models (LLMs) inherently carry the biases contained in their training corpora, which can lead to the perpetuation of societal harm. As the impact of these foundation models grows, understanding and evaluating their biases becomes crucial to achieving fairness and accuracy. We propose to study what LLMs know about the world we live in through the lens of geography. This approach is particularly powerful as there is ground truth for the numerous aspects of human life that are meaningfully projected onto geographic space such as culture, race, language, politics, and religion. We show various problematic geographic biases, which we define as systemic errors in geospatial predictions. Initially, we demonstrate that LLMs are capable of making accurate zero-shot geospatial predictions in the form of ratings that show strong monotonic correlation with ground truth (Spearman's $\rho$ of up to 0.89). We then show that LLMs exhibit common biases across a range of objective and subjective topics. In particular, LLMs are clearly biased against locations with lower socioeconomic conditions (e.g. most of Africa) on a variety of sensitive subjective topics such as attractiveness, morality, and intelligence (Spearman's $\rho$ of up to 0.70). Finally, we introduce a bias score to quantify this and find that there is significant variation in the magnitude of bias across existing LLMs.
DiffusionSat: A Generative Foundation Model for Satellite Imagery
Dec 06, 2023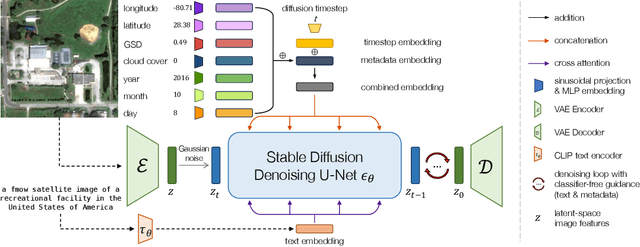
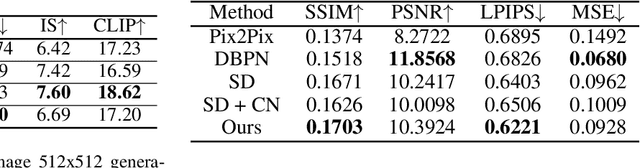
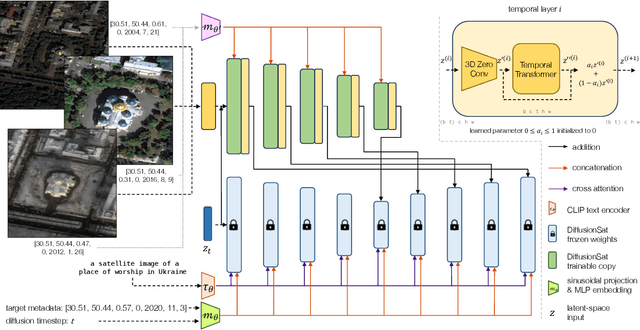

Diffusion models have achieved state-of-the-art results on many modalities including images, speech, and video. However, existing models are not tailored to support remote sensing data, which is widely used in important applications including environmental monitoring and crop-yield prediction. Satellite images are significantly different from natural images -- they can be multi-spectral, irregularly sampled across time -- and existing diffusion models trained on images from the Web do not support them. Furthermore, remote sensing data is inherently spatio-temporal, requiring conditional generation tasks not supported by traditional methods based on captions or images. In this paper, we present DiffusionSat, to date the largest generative foundation model trained on a collection of publicly available large, high-resolution remote sensing datasets. As text-based captions are sparsely available for satellite images, we incorporate the associated metadata such as geolocation as conditioning information. Our method produces realistic samples and can be used to solve multiple generative tasks including temporal generation, superresolution given multi-spectral inputs and in-painting. Our method outperforms previous state-of-the-art methods for satellite image generation and is the first large-scale $\textit{generative}$ foundation model for satellite imagery.
GeoLLM: Extracting Geospatial Knowledge from Large Language Models
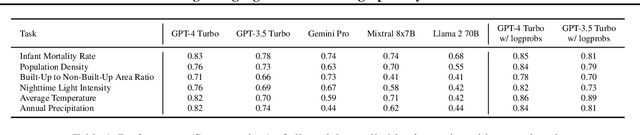
Oct 10, 2023The application of machine learning (ML) in a range of geospatial tasks is increasingly common but often relies on globally available covariates such as satellite imagery that can either be expensive or lack predictive power. Here we explore the question of whether the vast amounts of knowledge found in Internet language corpora, now compressed within large language models (LLMs), can be leveraged for geospatial prediction tasks. We first demonstrate that LLMs embed remarkable spatial information about locations, but naively querying LLMs using geographic coordinates alone is ineffective in predicting key indicators like population density. We then present GeoLLM, a novel method that can effectively extract geospatial knowledge from LLMs with auxiliary map data from OpenStreetMap. We demonstrate the utility of our approach across multiple tasks of central interest to the international community, including the measurement of population density and economic livelihoods. Across these tasks, our method demonstrates a 70% improvement in performance (measured using Pearson's $r^2$) relative to baselines that use nearest neighbors or use information directly from the prompt, and performance equal to or exceeding satellite-based benchmarks in the literature. With GeoLLM, we observe that GPT-3.5 outperforms Llama 2 and RoBERTa by 19% and 51% respectively, suggesting that the performance of our method scales well with the size of the model and its pretraining dataset. Our experiments reveal that LLMs are remarkably sample-efficient, rich in geospatial information, and robust across the globe. Crucially, GeoLLM shows promise in mitigating the limitations of existing geospatial covariates and complementing them well.
HarvestNet: A Dataset for Detecting Smallholder Farming Activity Using Harvest Piles and Remote Sensing
Aug 23, 2023
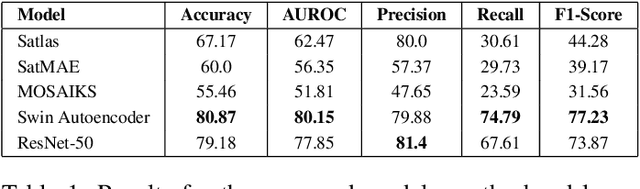


Small farms contribute to a large share of the productive land in developing countries. In regions such as sub-Saharan Africa, where 80% of farms are small (under 2 ha in size), the task of mapping smallholder cropland is an important part of tracking sustainability measures such as crop productivity. However, the visually diverse and nuanced appearance of small farms has limited the effectiveness of traditional approaches to cropland mapping. Here we introduce a new approach based on the detection of harvest piles characteristic of many smallholder systems throughout the world. We present HarvestNet, a dataset for mapping the presence of farms in the Ethiopian regions of Tigray and Amhara during 2020-2023, collected using expert knowledge and satellite images, totaling 7k hand-labeled images and 2k ground collected labels. We also benchmark a set of baselines including SOTA models in remote sensing with our best models having around 80% classification performance on hand labelled data and 90%, 98% accuracy on ground truth data for Tigray, Amhara respectively. We also perform a visual comparison with a widely used pre-existing coverage map and show that our model detects an extra 56,621 hectares of cropland in Tigray. We conclude that remote sensing of harvest piles can contribute to more timely and accurate cropland assessments in food insecure region.
Building Coverage Estimation with Low-resolution Remote Sensing Imagery
Jan 05, 2023



Building coverage statistics provide crucial insights into the urbanization, infrastructure, and poverty level of a region, facilitating efforts towards alleviating poverty, building sustainable cities, and allocating infrastructure investments and public service provision. Global mapping of buildings has been made more efficient with the incorporation of deep learning models into the pipeline. However, these models typically rely on high-resolution satellite imagery which are expensive to collect and infrequently updated. As a result, building coverage data are not updated timely especially in developing regions where the built environment is changing quickly. In this paper, we propose a method for estimating building coverage using only publicly available low-resolution satellite imagery that is more frequently updated. We show that having a multi-node quantile regression layer greatly improves the model's spatial and temporal generalization. Our model achieves a coefficient of determination ($R^2$) as high as 0.968 on predicting building coverage in regions of different levels of development around the world. We demonstrate that the proposed model accurately predicts the building coverage from raw input images and generalizes well to unseen countries and continents, suggesting the possibility of estimating global building coverage using only low-resolution remote sensing data.
IS-COUNT: Large-scale Object Counting from Satellite Images with Covariate-based Importance Sampling
Dec 16, 2021
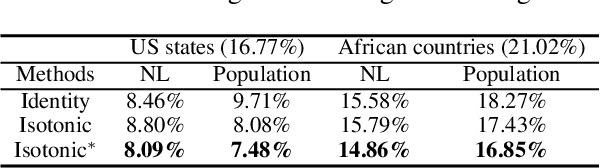
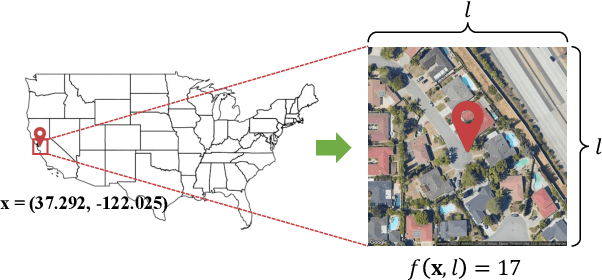
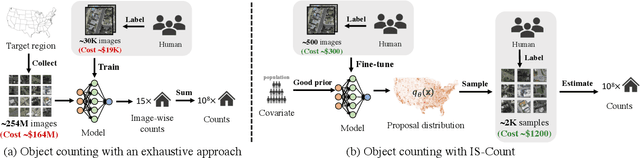
Object detection in high-resolution satellite imagery is emerging as a scalable alternative to on-the-ground survey data collection in many environmental and socioeconomic monitoring applications. However, performing object detection over large geographies can still be prohibitively expensive due to the high cost of purchasing imagery and compute. Inspired by traditional survey data collection strategies, we propose an approach to estimate object count statistics over large geographies through sampling. Given a cost budget, our method selects a small number of representative areas by sampling from a learnable proposal distribution. Using importance sampling, we are able to accurately estimate object counts after processing only a small fraction of the images compared to an exhaustive approach. We show empirically that the proposed framework achieves strong performance on estimating the number of buildings in the United States and Africa, cars in Kenya, brick kilns in Bangladesh, and swimming pools in the U.S., while requiring as few as 0.01% of satellite images compared to an exhaustive approach.
Geography-Aware Self-Supervised Learning
Dec 02, 2020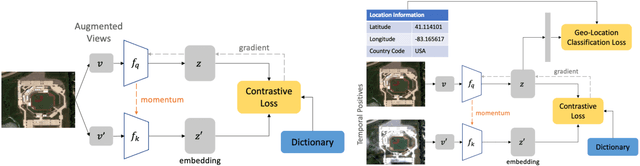
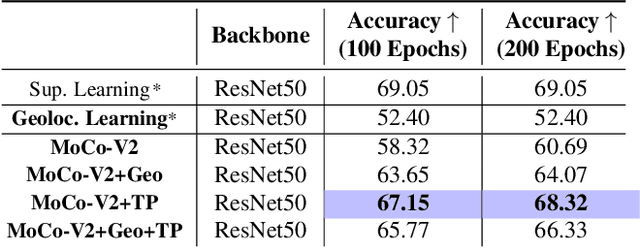

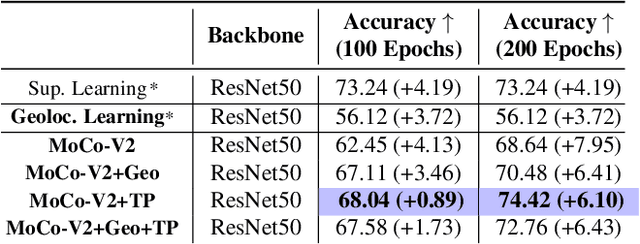
Contrastive learning methods have significantly narrowed the gap between supervised and unsupervised learning on computer vision tasks. In this paper, we explore their application to remote sensing, where unlabeled data is often abundant but labeled data is scarce. We first show that due to their different characteristics, a non-trivial gap persists between contrastive and supervised learning on standard benchmarks. To close the gap, we propose novel training methods that exploit the spatiotemporal structure of remote sensing data. We leverage spatially aligned images over time to construct temporal positive pairs in contrastive learning and geo-location to design pre-text tasks. Our experiments show that our proposed method closes the gap between contrastive and supervised learning on image classification, object detection and semantic segmentation for remote sensing and other geo-tagged image datasets.
Predicting Livelihood Indicators from Crowdsourced Street Level Images
Jun 27, 2020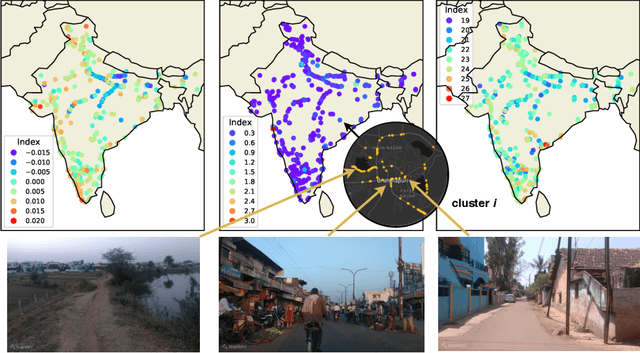
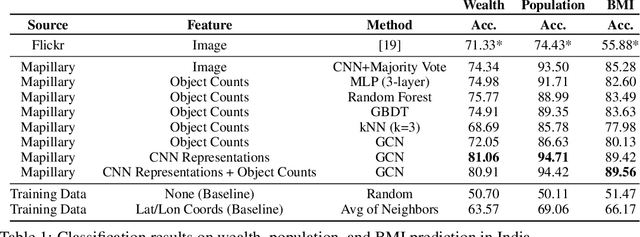
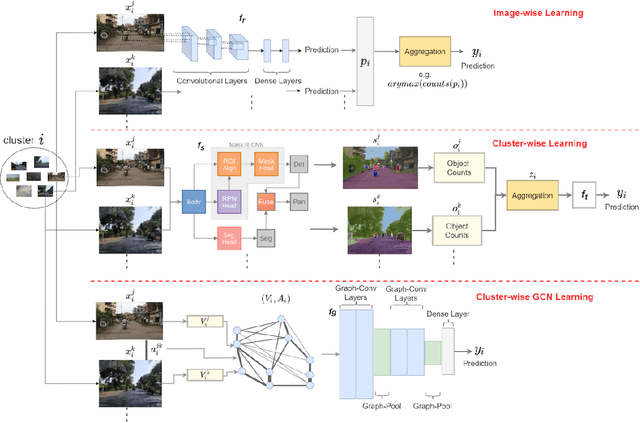
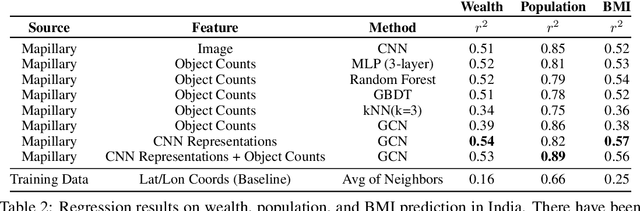
Major decisions from governments and other large organizations rely on measurements of the populace's well-being, but making such measurements at a broad scale is expensive and thus infrequent in much of the developing world. We propose an inexpensive, scalable, and interpretable approach to predict key livelihood indicators from public crowd-sourced street-level imagery. Such imagery can be cheaply collected and more frequently updated compared to traditional surveying methods, while containing plausibly relevant information for a range of livelihood indicators. We propose two approaches to learn from the street-level imagery. First method creates multihousehold cluster representations by detecting informative objects and the second method uses a graph-based approach that leverages the inherent structure between images. By visualizing what features are important to a model and how they are used, we can help end-user organizations understand the models and offer an alternate approach for index estimation that uses cheaply obtained roadway features. By comparing our results against ground data collected in nationally-representative household surveys, we show our approach can be used to accurately predict indicators of poverty, population, and health across India.
Efficient Poverty Mapping using Deep Reinforcement Learning
Jun 07, 2020


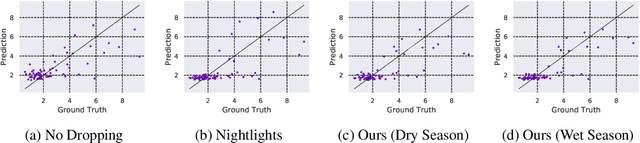
The combination of high-resolution satellite imagery and machine learning have proven useful in many sustainability-related tasks, including poverty prediction, infrastructure measurement, and forest monitoring. However, the accuracy afforded by high-resolution imagery comes at a cost, as such imagery is extremely expensive to purchase at scale. This creates a substantial hurdle to the efficient scaling and widespread adoption of high-resolution-based approaches. To reduce acquisition costs while maintaining accuracy, we propose a reinforcement learning approach in which free low-resolution imagery is used to dynamically identify where to acquire costly high-resolution images, prior to performing a deep learning task on the high-resolution images. We apply this approach to the task of poverty prediction in Uganda, building on an earlier approach that used object detection to count objects and use these counts to predict poverty. Our approach exceeds previous performance benchmarks on this task while using 80% fewer high-resolution images. Our approach could have application in many sustainability domains that require high-resolution imagery.
Meta-Learning for Few-Shot Land Cover Classification
Apr 28, 2020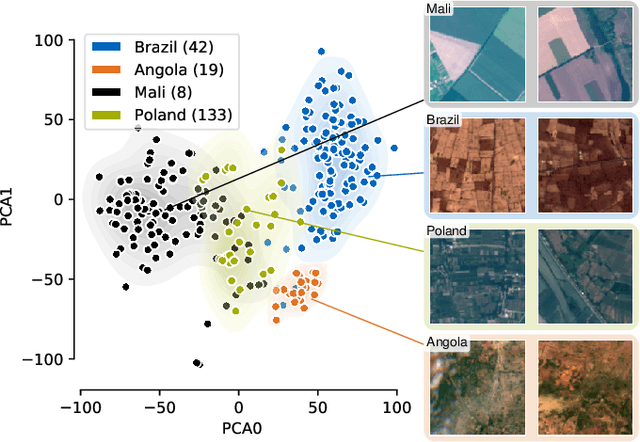
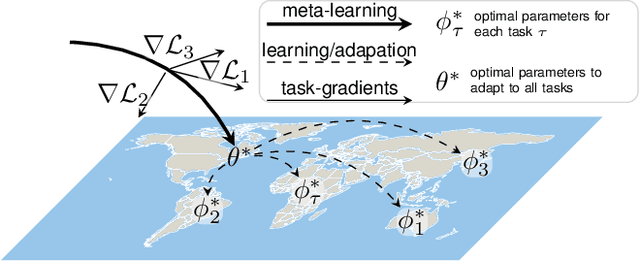
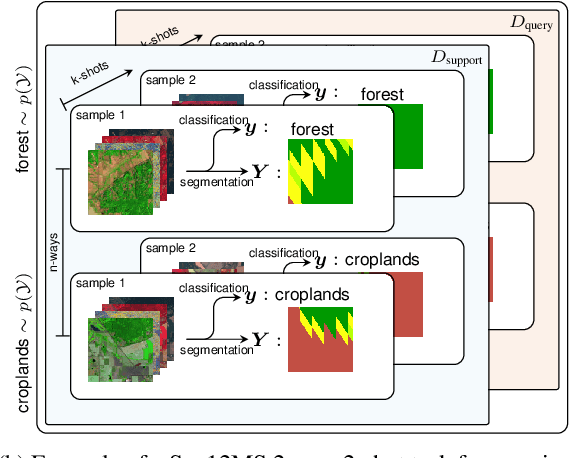
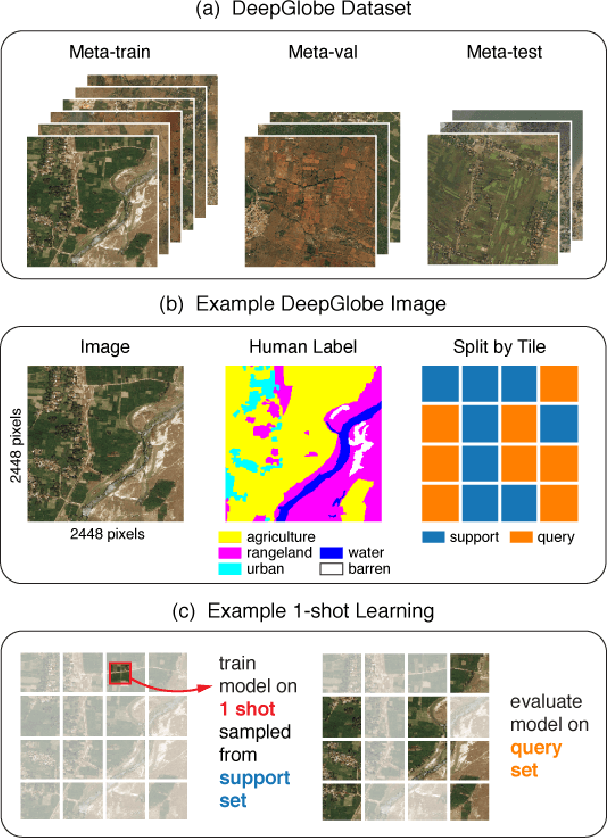
The representations of the Earth's surface vary from one geographic region to another. For instance, the appearance of urban areas differs between continents, and seasonality influences the appearance of vegetation. To capture the diversity within a single category, like as urban or vegetation, requires a large model capacity and, consequently, large datasets. In this work, we propose a different perspective and view this diversity as an inductive transfer learning problem where few data samples from one region allow a model to adapt to an unseen region. We evaluate the model-agnostic meta-learning (MAML) algorithm on classification and segmentation tasks using globally and regionally distributed datasets. We find that few-shot model adaptation outperforms pre-training with regular gradient descent and fine-tuning on (1) the Sen12MS dataset and (2) DeepGlobe data when the source domain and target domain differ. This indicates that model optimization with meta-learning may benefit tasks in the Earth sciences whose data show a high degree of diversity from region to region, while traditional gradient-based supervised learning remains suitable in the absence of a feature or label shift.