 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Coverage Estimation with Low-resolution Remote Sensing Imagery
Jan 05, 2023



Building coverage statistics provide crucial insights into the urbanization, infrastructure, and poverty level of a region, facilitating efforts towards alleviating poverty, building sustainable cities, and allocating infrastructure investments and public service provision. Global mapping of buildings has been made more efficient with the incorporation of deep learning models into the pipeline. However, these models typically rely on high-resolution satellite imagery which are expensive to collect and infrequently updated. As a result, building coverage data are not updated timely especially in developing regions where the built environment is changing quickly. In this paper, we propose a method for estimating building coverage using only publicly available low-resolution satellite imagery that is more frequently updated. We show that having a multi-node quantile regression layer greatly improves the model's spatial and temporal generalization. Our model achieves a coefficient of determination ($R^2$) as high as 0.968 on predicting building coverage in regions of different levels of development around the world. We demonstrate that the proposed model accurately predicts the building coverage from raw input images and generalizes well to unseen countries and continents, suggesting the possibility of estimating global building coverage using only low-resolution remote sensing data.
IS-COUNT: Large-scale Object Counting from Satellite Images with Covariate-based Importance Sampling
Dec 16, 2021
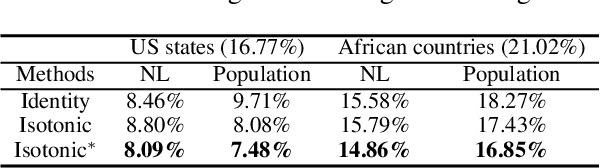
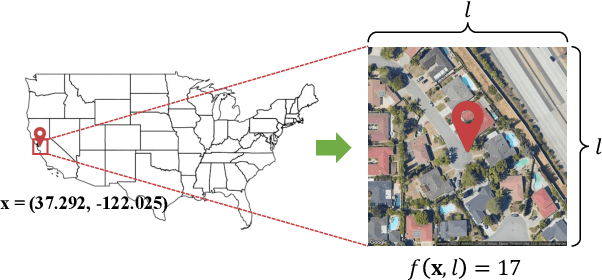
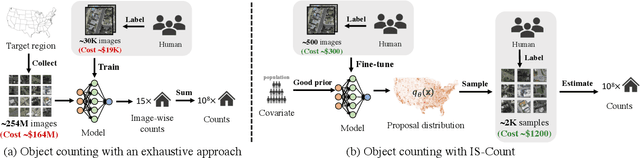
Object detection in high-resolution satellite imagery is emerging as a scalable alternative to on-the-ground survey data collection in many environmental and socioeconomic monitoring applications. However, performing object detection over large geographies can still be prohibitively expensive due to the high cost of purchasing imagery and compute. Inspired by traditional survey data collection strategies, we propose an approach to estimate object count statistics over large geographies through sampling. Given a cost budget, our method selects a small number of representative areas by sampling from a learnable proposal distribution. Using importance sampling, we are able to accurately estimate object counts after processing only a small fraction of the images compared to an exhaustive approach. We show empirically that the proposed framework achieves strong performance on estimating the number of buildings in the United States and Africa, cars in Kenya, brick kilns in Bangladesh, and swimming pools in the U.S., while requiring as few as 0.01% of satellite images compared to an exhaustive approach.
Metadata Shaping: Natural Language Annotations for the Tail
Oct 16, 2021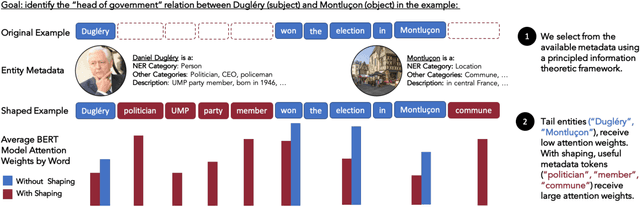

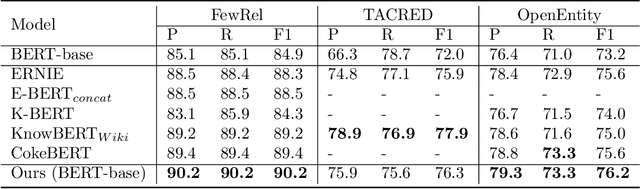
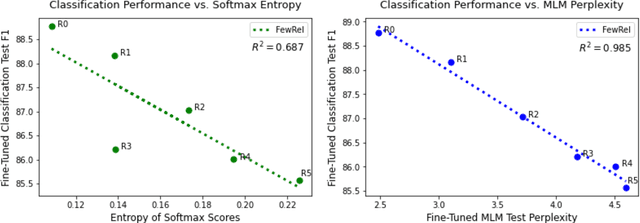
Language models (LMs) have made remarkable progress, but still struggle to generalize beyond the training data to rare linguistic patterns. Since rare entities and facts are prevalent in the queries users submit to popular applications such as search and personal assistant systems, improving the ability of LMs to reliably capture knowledge over rare entities is a pressing challenge studied in significant prior work. Noticing that existing approaches primarily modify the LM architecture or introduce auxiliary objectives to inject useful entity knowledge, we ask to what extent we could match the quality of these architectures using a base LM architecture, and only changing the data? We propose metadata shaping, a method in which readily available metadata, such as entity descriptions and categorical tags, are appended to examples based on information theoretic metrics. Intuitively, if metadata corresponding to popular entities overlap with metadata for rare entities, the LM may be able to better reason about the rare entities using patterns learned from similar popular entities. On standard entity-rich tasks (TACRED, FewRel, OpenEntity), with no changes to the LM whatsoever, metadata shaping exceeds the BERT-baseline by up to 5.3 F1 points, and achieves or competes with state-of-the-art results. We further show the improvements are up to 10x larger on examples containing tail versus popular entities.