 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Geographically Biased
Feb 05, 2024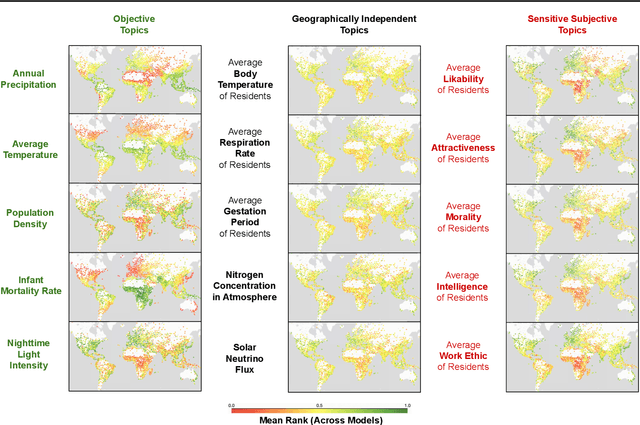


Large Language Models (LLMs) inherently carry the biases contained in their training corpora, which can lead to the perpetuation of societal harm. As the impact of these foundation models grows, understanding and evaluating their biases becomes crucial to achieving fairness and accuracy. We propose to study what LLMs know about the world we live in through the lens of geography. This approach is particularly powerful as there is ground truth for the numerous aspects of human life that are meaningfully projected onto geographic space such as culture, race, language, politics, and religion. We show various problematic geographic biases, which we define as systemic errors in geospatial predictions. Initially, we demonstrate that LLMs are capable of making accurate zero-shot geospatial predictions in the form of ratings that show strong monotonic correlation with ground truth (Spearman's $\rho$ of up to 0.89). We then show that LLMs exhibit common biases across a range of objective and subjective topics. In particular, LLMs are clearly biased against locations with lower socioeconomic conditions (e.g. most of Africa) on a variety of sensitive subjective topics such as attractiveness, morality, and intelligence (Spearman's $\rho$ of up to 0.70). Finally, we introduce a bias score to quantify this and find that there is significant variation in the magnitude of bias across existing LLMs.
DiffusionSat: A Generative Foundation Model for Satellite Imagery
Dec 06, 2023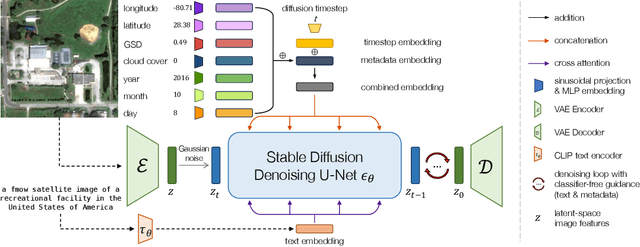
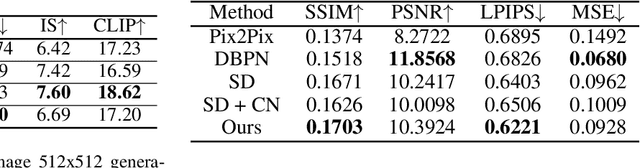
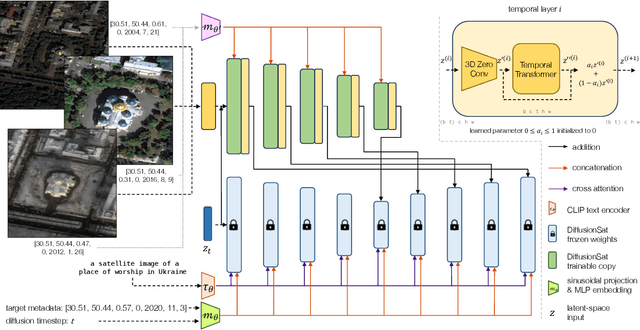

Diffusion models have achieved state-of-the-art results on many modalities including images, speech, and video. However, existing models are not tailored to support remote sensing data, which is widely used in important applications including environmental monitoring and crop-yield prediction. Satellite images are significantly different from natural images -- they can be multi-spectral, irregularly sampled across time -- and existing diffusion models trained on images from the Web do not support them. Furthermore, remote sensing data is inherently spatio-temporal, requiring conditional generation tasks not supported by traditional methods based on captions or images. In this paper, we present DiffusionSat, to date the largest generative foundation model trained on a collection of publicly available large, high-resolution remote sensing datasets. As text-based captions are sparsely available for satellite images, we incorporate the associated metadata such as geolocation as conditioning information. Our method produces realistic samples and can be used to solve multiple generative tasks including temporal generation, superresolution given multi-spectral inputs and in-painting. Our method outperforms previous state-of-the-art methods for satellite image generation and is the first large-scale $\textit{generative}$ foundation model for satellite imagery.
GeoLLM: Extracting Geospatial Knowledge from Large Language Models
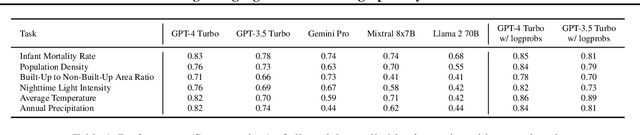
Oct 10, 2023The application of machine learning (ML) in a range of geospatial tasks is increasingly common but often relies on globally available covariates such as satellite imagery that can either be expensive or lack predictive power. Here we explore the question of whether the vast amounts of knowledge found in Internet language corpora, now compressed within large language models (LLMs), can be leveraged for geospatial prediction tasks. We first demonstrate that LLMs embed remarkable spatial information about locations, but naively querying LLMs using geographic coordinates alone is ineffective in predicting key indicators like population density. We then present GeoLLM, a novel method that can effectively extract geospatial knowledge from LLMs with auxiliary map data from OpenStreetMap. We demonstrate the utility of our approach across multiple tasks of central interest to the international community, including the measurement of population density and economic livelihoods. Across these tasks, our method demonstrates a 70% improvement in performance (measured using Pearson's $r^2$) relative to baselines that use nearest neighbors or use information directly from the prompt, and performance equal to or exceeding satellite-based benchmarks in the literature. With GeoLLM, we observe that GPT-3.5 outperforms Llama 2 and RoBERTa by 19% and 51% respectively, suggesting that the performance of our method scales well with the size of the model and its pretraining dataset. Our experiments reveal that LLMs are remarkably sample-efficient, rich in geospatial information, and robust across the globe. Crucially, GeoLLM shows promise in mitigating the limitations of existing geospatial covariates and complementing them well.
Building Coverage Estimation with Low-resolution Remote Sensing Imagery
Jan 05, 2023



Building coverage statistics provide crucial insights into the urbanization, infrastructure, and poverty level of a region, facilitating efforts towards alleviating poverty, building sustainable cities, and allocating infrastructure investments and public service provision. Global mapping of buildings has been made more efficient with the incorporation of deep learning models into the pipeline. However, these models typically rely on high-resolution satellite imagery which are expensive to collect and infrequently updated. As a result, building coverage data are not updated timely especially in developing regions where the built environment is changing quickly. In this paper, we propose a method for estimating building coverage using only publicly available low-resolution satellite imagery that is more frequently updated. We show that having a multi-node quantile regression layer greatly improves the model's spatial and temporal generalization. Our model achieves a coefficient of determination ($R^2$) as high as 0.968 on predicting building coverage in regions of different levels of development around the world. We demonstrate that the proposed model accurately predicts the building coverage from raw input images and generalizes well to unseen countries and continents, suggesting the possibility of estimating global building coverage using only low-resolution remote sensing data.
Detecting Crop Burning in India using Satellite Data
Sep 21, 2022

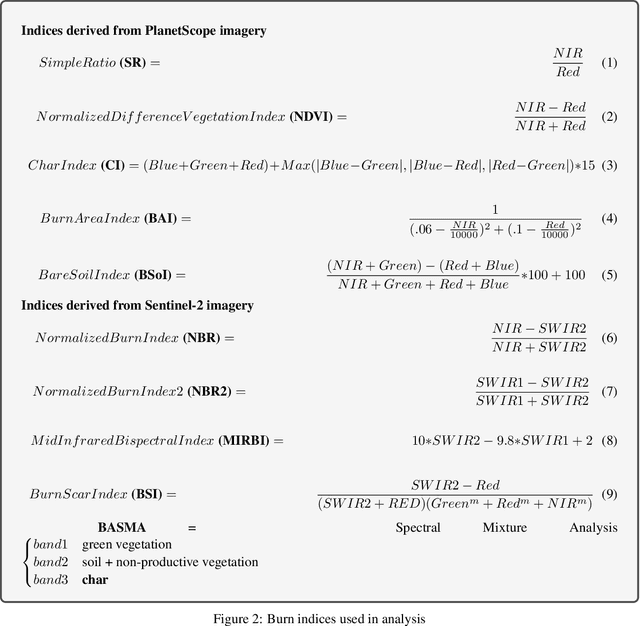
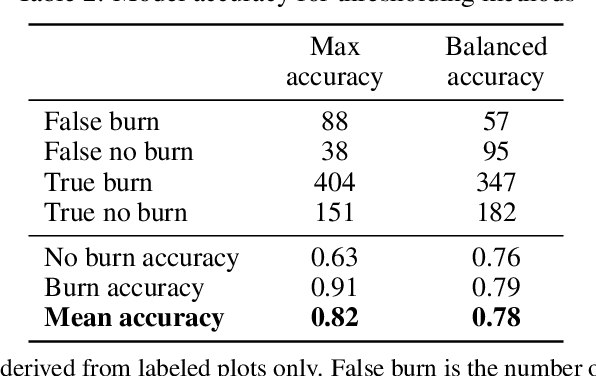
Crop residue burning is a major source of air pollution in many parts of the world, notably South Asia. Policymakers, practitioners and researchers have invested in both measuring impacts and developing interventions to reduce burning. However, measuring the impacts of burning or the effectiveness of interventions to reduce burning requires data on where burning occurred. These data are challenging to collect in the field, both in terms of cost and feasibility. We take advantage of data from ground-based monitoring of crop residue burning in Punjab, India to explore whether burning can be detected more effectively using accessible satellite imagery. Specifically, we used 3m PlanetScope data with high temporal resolution (up to daily) as well as publicly-available Sentinel-2 data with weekly temporal resolution but greater depth of spectral information. Following an analysis of the ability of different spectral bands and burn indices to separate burned and unburned plots individually, we built a Random Forest model with those determined to provide the greatest separability and evaluated model performance with ground-verified data. Our overall model accuracy of 82-percent is favorable given the challenges presented by the measurement. Based on insights from this process, we discuss technical challenges of detecting crop residue burning from satellite imagery as well as challenges to measuring impacts, both of burning and of policy interventions.
SatMAE: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery
Jul 17, 2022

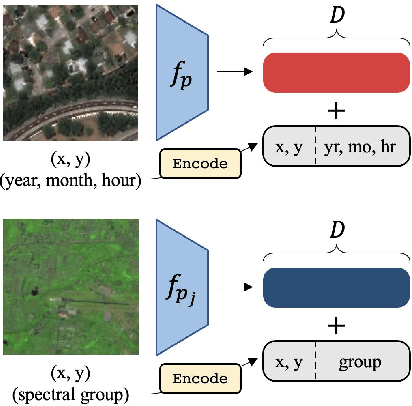
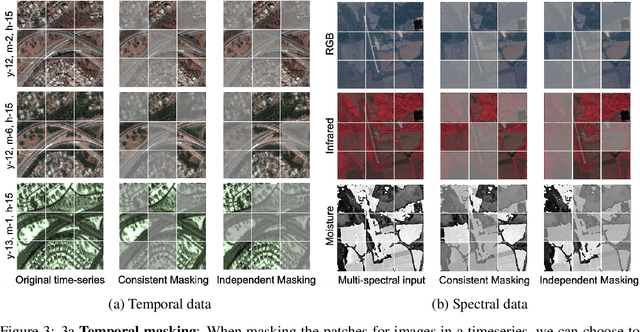
Unsupervised pre-training methods for large vision models have shown to enhance performance on downstream supervised tasks. Developing similar techniques for satellite imagery presents significant opportunities as unlabelled data is plentiful and the inherent temporal and multi-spectral structure provides avenues to further improve existing pre-training strategies. In this paper, we present SatMAE, a pre-training framework for temporal or multi-spectral satellite imagery based on Masked Autoencoder (MAE). To leverage temporal information, we include a temporal embedding along with independently masking image patches across time. In addition, we demonstrate that encoding multi-spectral data as groups of bands with distinct spectral positional encodings is beneficial. Our approach yields strong improvements over previous state-of-the-art techniques, both in terms of supervised learning performance on benchmark datasets (up to $\uparrow$ 7\%), and transfer learning performance on downstream remote sensing tasks, including land cover classification (up to $\uparrow$ 14\%) and semantic segmentation.
Tracking Urbanization in Developing Regions with Remote Sensing Spatial-Temporal Super-Resolution
Apr 04, 2022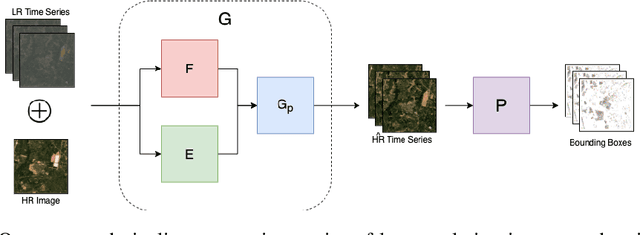
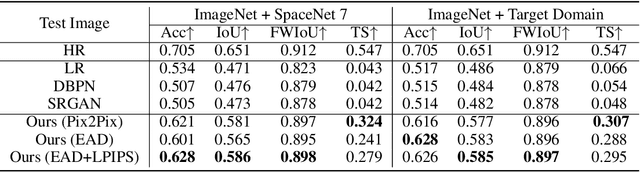

Automated tracking of urban development in areas where construction information is not available became possible with recent advancements in machine learning and remote sensing. Unfortunately, these solutions perform best on high-resolution imagery, which is expensive to acquire and infrequently available, making it difficult to scale over long time spans and across large geographies. In this work, we propose a pipeline that leverages a single high-resolution image and a time series of publicly available low-resolution images to generate accurate high-resolution time series for object tracking in urban construction. Our method achieves significant improvement in comparison to baselines using single image super-resolution, and can assist in extending the accessibility and scalability of building construction tracking across the developing world.
IS-COUNT: Large-scale Object Counting from Satellite Images with Covariate-based Importance Sampling
Dec 16, 2021
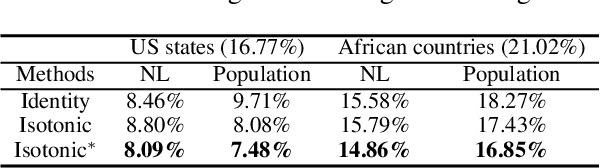
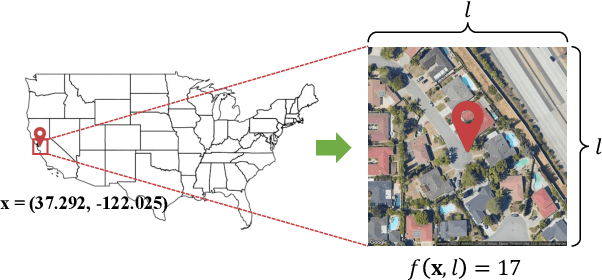
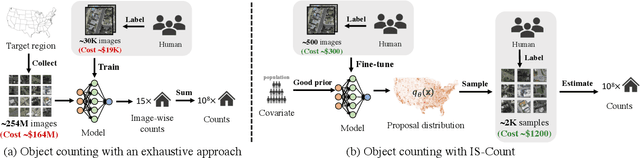
Object detection in high-resolution satellite imagery is emerging as a scalable alternative to on-the-ground survey data collection in many environmental and socioeconomic monitoring applications. However, performing object detection over large geographies can still be prohibitively expensive due to the high cost of purchasing imagery and compute. Inspired by traditional survey data collection strategies, we propose an approach to estimate object count statistics over large geographies through sampling. Given a cost budget, our method selects a small number of representative areas by sampling from a learnable proposal distribution. Using importance sampling, we are able to accurately estimate object counts after processing only a small fraction of the images compared to an exhaustive approach. We show empirically that the proposed framework achieves strong performance on estimating the number of buildings in the United States and Africa, cars in Kenya, brick kilns in Bangladesh, and swimming pools in the U.S., while requiring as few as 0.01% of satellite images compared to an exhaustive approach.
SustainBench: Benchmarks for Monitoring the Sustainable Development Goals with Machine Learning
Nov 08, 2021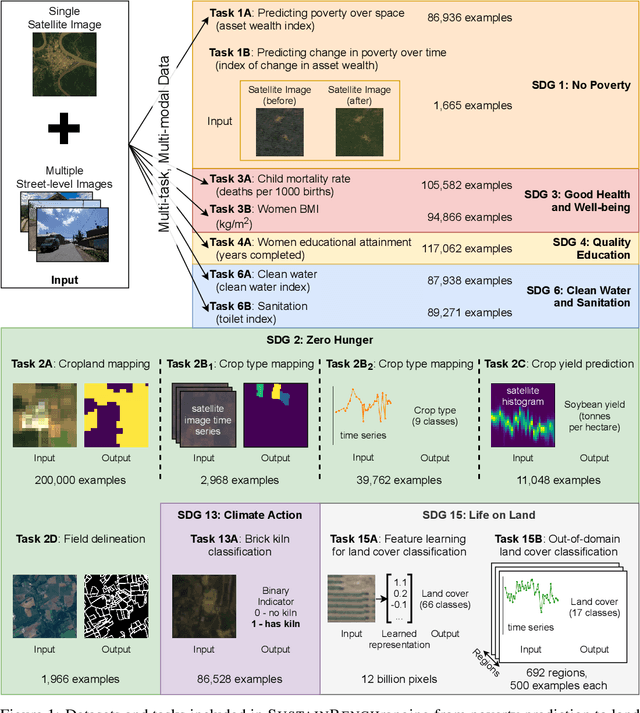
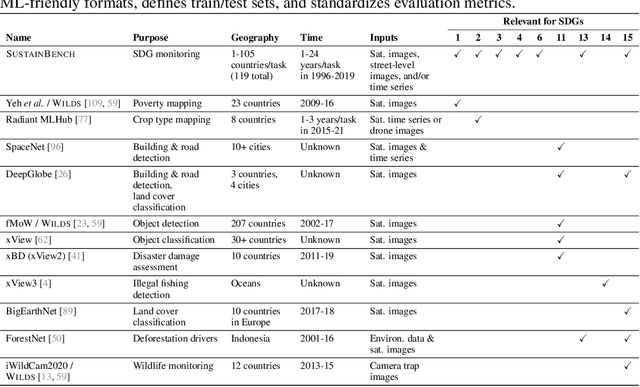
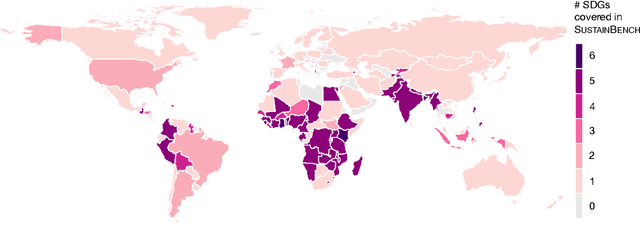
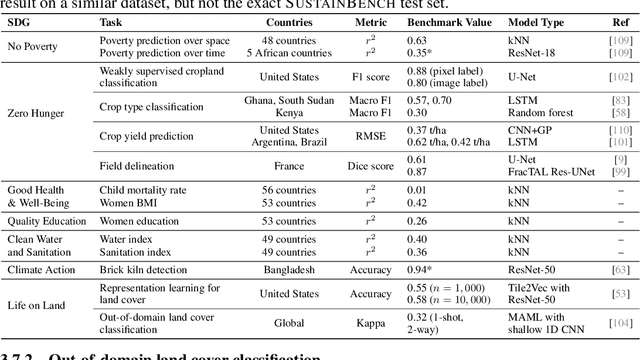
Progress toward the United Nations Sustainable Development Goals (SDGs) has been hindered by a lack of data on key environmental and socioeconomic indicators, which historically have come from ground surveys with sparse temporal and spatial coverage. Recent advances in machine learning have made it possible to utilize abundant, frequently-updated, and globally available data, such as from satellites or social media, to provide insights into progress toward SDGs. Despite promising early results, approaches to using such data for SDG measurement thus far have largely evaluated on different datasets or used inconsistent evaluation metrics, making it hard to understand whether performance is improving and where additional research would be most fruitful. Furthermore, processing satellite and ground survey data requires domain knowledge that many in the machine learning community lack. In this paper, we introduce SustainBench, a collection of 15 benchmark tasks across 7 SDGs, including tasks related to economic development, agriculture, health, education, water and sanitation, climate action, and life on land. Datasets for 11 of the 15 tasks are released publicly for the first time. Our goals for SustainBench are to (1) lower the barriers to entry for the machine learning community to contribute to measuring and achieving the SDGs; (2) provide standard benchmarks for evaluating machine learning models on tasks across a variety of SDGs; and (3) encourage the development of novel machine learning methods where improved model performance facilitates progress towards the SDGs.
Using Satellite Imagery and Machine Learning to Estimate the Livelihood Impact of Electricity Access
Sep 07, 2021In many regions of the world, sparse data on key economic outcomes inhibits the development, targeting, and evaluation of public policy. We demonstrate how advancements in satellite imagery and machine learning can help ameliorate these data and inference challenges. In the context of an expansion of the electrical grid across Uganda, we show how a combination of satellite imagery and computer vision can be used to develop local-level livelihood measurements appropriate for inferring the causal impact of electricity access on livelihoods. We then show how ML-based inference techniques deliver more reliable estimates of the causal impact of electrification than traditional alternatives when applied to these data. We estimate that grid access improves village-level asset wealth in rural Uganda by 0.17 standard deviations, more than doubling the growth rate over our study period relative to untreated areas. Our results provide country-scale evidence on the impact of a key infrastructure investment, and provide a low-cost, generalizable approach to future policy evaluation in data sparse environments.