 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
Robust Out-of-Order Retrieval for Grid-Based Storage at Maximum Capacity
Jan 27, 2026This paper proposes a framework for improving the operational efficiency of automated storage systems under uncertainty. It considers a 2D grid-based storage for uniform-sized loads (e.g., containers, pallets, or totes), which are moved by a robot (or other manipulator) along a collision-free path in the grid. The loads are labeled (i.e., unique) and must be stored in a given sequence, and later be retrieved in a different sequence -- an operational pattern that arises in logistics applications, such as last-mile distribution centers and shipyards. The objective is to minimize the load relocations to ensure efficient retrieval. A previous result guarantees a zero-relocation solution for known storage and retrieval sequences, even for storage at full capacity, provided that the side of the grid through which loads are stored/retrieved is at least 3 cells wide. However, in practice, the retrieval sequence can change after the storage phase. To address such uncertainty, this work investigates \emph{$k$-bounded perturbations} during retrieval, under which any two loads may depart out of order if they are originally at most $k$ positions apart. We prove that a $Θ(k)$ grid width is necessary and sufficient for eliminating relocations at maximum capacity. We also provide an efficient solver for computing a storage arrangement that is robust to such perturbations. To address the higher-uncertainty case where perturbations exceed $k$, a strategy is introduced to effectively minimize relocations. Extensive experiments show that, for $k$ up to half the grid width, the proposed storage-retrieval framework essentially eliminates relocations. For $k$ values up to the full grid width, relocations are reduced by $50\%+$.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Modular and Adaptive Conformal Prediction for Sequential Models via Residual Decomposition
Oct 06, 2025Conformal prediction offers finite-sample coverage guarantees under minimal assumptions. However, existing methods treat the entire modeling process as a black box, overlooking opportunities to exploit modular structure. We introduce a conformal prediction framework for two-stage sequential models, where an upstream predictor generates intermediate representations for a downstream model. By decomposing the overall prediction residual into stage-specific components, our method enables practitioners to attribute uncertainty to specific pipeline stages. We develop a risk-controlled parameter selection procedure using family-wise error rate (FWER) control to calibrate stage-wise scaling parameters, and propose an adaptive extension for non-stationary settings that preserves long-run coverage guarantees. Experiments on synthetic distribution shifts, as well as real-world supply chain and stock market data, demonstrate that our approach maintains coverage under conditions that degrade standard conformal methods, while providing interpretable stage-wise uncertainty attribution. This framework offers diagnostic advantages and robust coverage that standard conformal methods lack.
DECO: Life-Cycle Management of Enterprise-Grade Chatbots
Dec 08, 2024



Software engineers frequently grapple with the challenge of accessing disparate documentation and telemetry data, including Troubleshooting Guides (TSGs), incident reports, code repositories, and various internal tools developed by multiple stakeholders. While on-call duties are inevitable, incident resolution becomes even more daunting due to the obscurity of legacy sources and the pressures of strict time constraints. To enhance the efficiency of on-call engineers (OCEs) and streamline their daily workflows, we introduced DECO -- a comprehensive framework for developing, deploying, and managing enterprise-grade chatbots tailored to improve productivity in engineering routines. This paper details the design and implementation of the DECO framework, emphasizing its innovative NL2SearchQuery functionality and a hierarchical planner. These features support efficient and customized retrieval-augmented-generation (RAG) algorithms that not only extract relevant information from diverse sources but also select the most pertinent toolkits in response to user queries. This enables the addressing of complex technical questions and provides seamless, automated access to internal resources. Additionally, DECO incorporates a robust mechanism for converting unstructured incident logs into user-friendly, structured guides, effectively bridging the documentation gap. Feedback from users underscores DECO's pivotal role in simplifying complex engineering tasks, accelerating incident resolution, and bolstering organizational productivity. Since its launch in September 2023, DECO has demonstrated its effectiveness through extensive engagement, with tens of thousands of interactions from hundreds of active users across multiple organizations within the company.
Benchmarking LLM Code Generation for Audio Programming with Visual Dataflow Languages
Sep 01, 2024



Node-based programming languages are increasingly popular in media arts coding domains. These languages are designed to be accessible to users with limited coding experience, allowing them to achieve creative output without an extensive programming background. Using LLM-based code generation to further lower the barrier to creative output is an exciting opportunity. However, the best strategy for code generation for visual node-based programming languages is still an open question. In particular, such languages have multiple levels of representation in text, each of which may be used for code generation. In this work, we explore the performance of LLM code generation in audio programming tasks in visual programming languages at multiple levels of representation. We explore code generation through metaprogramming code representations for these languages (i.e., coding the language using a different high-level text-based programming language), as well as through direct node generation with JSON. We evaluate code generated in this way for two visual languages for audio programming on a benchmark set of coding problems. We measure both correctness and complexity of the generated code. We find that metaprogramming results in more semantically correct generated code, given that the code is well-formed (i.e., is syntactically correct and runs). We also find that prompting for richer metaprogramming using randomness and loops led to more complex code.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Tracking Urbanization in Developing Regions with Remote Sensing Spatial-Temporal Super-Resolution
Apr 04, 2022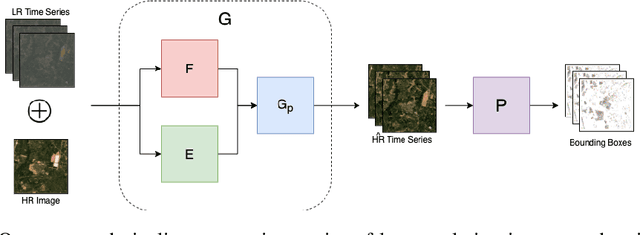
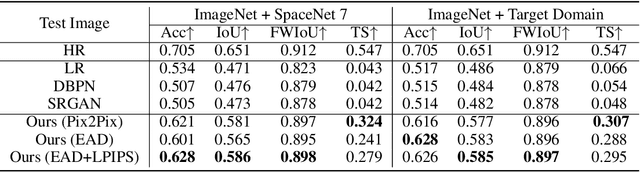

Automated tracking of urban development in areas where construction information is not available became possible with recent advancements in machine learning and remote sensing. Unfortunately, these solutions perform best on high-resolution imagery, which is expensive to acquire and infrequently available, making it difficult to scale over long time spans and across large geographies. In this work, we propose a pipeline that leverages a single high-resolution image and a time series of publicly available low-resolution images to generate accurate high-resolution time series for object tracking in urban construction. Our method achieves significant improvement in comparison to baselines using single image super-resolution, and can assist in extending the accessibility and scalability of building construction tracking across the developing world.
Boosting Supervised Learning Performance with Co-training
Nov 18, 2021
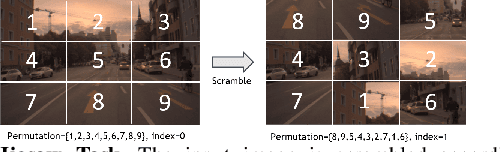


Deep learning perception models require a massive amount of labeled training data to achieve good performance. While unlabeled data is easy to acquire, the cost of labeling is prohibitive and could create a tremendous burden on companies or individuals. Recently, self-supervision has emerged as an alternative to leveraging unlabeled data. In this paper, we propose a new light-weight self-supervised learning framework that could boost supervised learning performance with minimum additional computation cost. Here, we introduce a simple and flexible multi-task co-training framework that integrates a self-supervised task into any supervised task. Our approach exploits pretext tasks to incur minimum compute and parameter overheads and minimal disruption to existing training pipelines. We demonstrate the effectiveness of our framework by using two self-supervised tasks, object detection and panoptic segmentation, on different perception models. Our results show that both self-supervised tasks can improve the accuracy of the supervised task and, at the same time, demonstrates strong domain adaption capability when used with additional unlabeled data.