 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransmission Neural Networks: Inhibitory and Excitatory Connections
Apr 05, 2026This paper extends the Transmission Neural Network model proposed by Gao and Caines in [1]-[3] to incorporate inhibitory connections and neurotransmitter populations. The extended network model contains binary neuronal states, transmission dynamics, and inhibitory and excitatory connections. Under technical assumptions, we establish the characterization of the firing probabilities of neurons, and show that such a characterization considering inhibitions can be equivalently represented by a neural network where each neuron has a continuous state of dimension 2. Moreover, we incorporated neurotransmitter populations into the modeling and establish the limit network model when the number of neurotransmitters at all synaptic connections go to infinity. Finally, sufficient conditions for stability and contraction properties of the limit network model are established.
SGL: Structure Guidance Learning for Camera Localization
Apr 12, 2023



Camera localization is a classical computer vision task that serves various Artificial Intelligence and Robotics applications. With the rapid developments of Deep Neural Networks (DNNs), end-to-end visual localization methods are prosperous in recent years. In this work, we focus on the scene coordinate prediction ones and propose a network architecture named as Structure Guidance Learning (SGL) which utilizes the receptive branch and the structure branch to extract both high-level and low-level features to estimate the 3D coordinates. We design a confidence strategy to refine and filter the predicted 3D observations, which enables us to estimate the camera poses by employing the Perspective-n-Point (PnP) with RANSAC. In the training part, we design the Bundle Adjustment trainer to help the network fit the scenes better. Comparisons with some state-of-the-art (SOTA) methods and sufficient ablation experiments confirm the validity of our proposed architecture.
IH-ViT: Vision Transformer-based Integrated Circuit Appear-ance Defect Detection
Feb 09, 2023

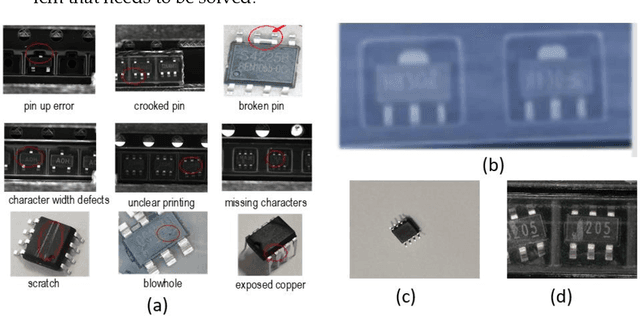

For the problems of low recognition rate and slow recognition speed of traditional detection methods in IC appearance defect detection, we propose an IC appearance defect detection algo-rithm IH-ViT. Our proposed model takes advantage of the respective strengths of CNN and ViT to acquire image features from both local and global aspects, and finally fuses the two features for decision making to determine the class of defects, thus obtaining better accuracy of IC defect recognition. To address the problem that IC appearance defects are mainly reflected in the dif-ferences in details, which are difficult to identify by traditional algorithms, we improved the tra-ditional ViT by performing an additional convolution operation inside the batch. For the problem of information imbalance of samples due to diverse sources of data sets, we adopt a dual-channel image segmentation technique to further improve the accuracy of IC appearance defects. Finally, after testing, our proposed hybrid IH-ViT model achieved 72.51% accuracy, which is 2.8% and 6.06% higher than ResNet50 and ViT models alone. The proposed algorithm can quickly and accurately detect the defect status of IC appearance and effectively improve the productivity of IC packaging and testing companies.
A Real-Time Fusion Framework for Long-term Visual Localization
Oct 18, 2022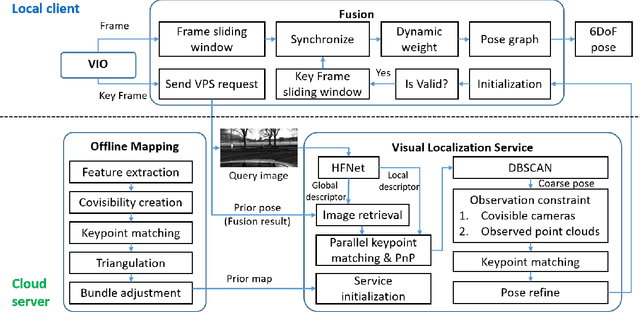
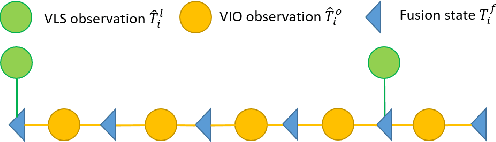
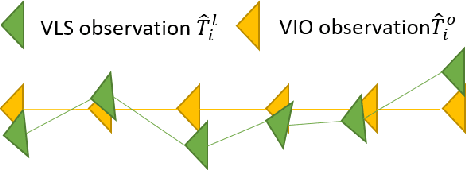
Visual localization is a fundamental task that regresses the 6 Degree Of Freedom (6DoF) poses with image features in order to serve the high precision localization requests in many robotics applications. Degenerate conditions like motion blur, illumination changes and environment variations place great challenges in this task. Fusion with additional information, such as sequential information and Inertial Measurement Unit (IMU) inputs, would greatly assist such problems. In this paper, we present an efficient client-server visual localization architecture that fuses global and local pose estimations to realize promising precision and efficiency. We include additional geometry hints in mapping and global pose regressing modules to improve the measurement quality. A loosely coupled fusion policy is adopted to leverage the computation complexity and accuracy. We conduct the evaluations on two typical open-source benchmarks, 4Seasons and OpenLORIS. Quantitative results prove that our framework has competitive performance with respect to other state-of-the-art visual localization solutions.
Fixed-Point Centrality for Networks
Sep 15, 2022This paper proposes a family of network centralities called fixed-point centralities. This centrality family is defined via the fixed point of permutation equivariant mappings related to the underlying network. Such a centrality notion is immediately extended to define fixed-point centralities for infinite graphs characterized by graphons. Variation bounds of such centralities with respect to the variations of the underlying graphs and graphons under mild assumptions are established. Fixed-point centralities connect with a variety of different models on networks including graph neural networks, static and dynamic games on networks, and Markov decision processes.
Transmission Neural Networks: From Virus Spread Models to Neural Networks
Aug 07, 2022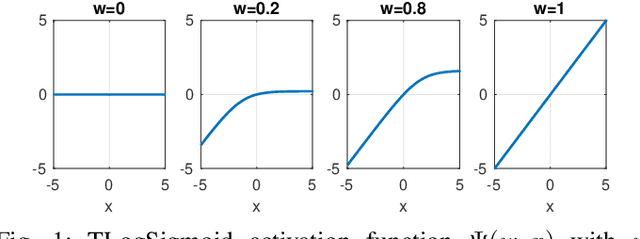
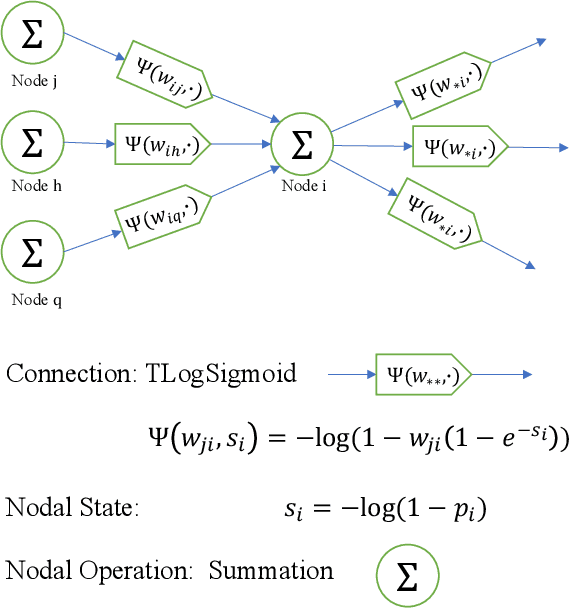
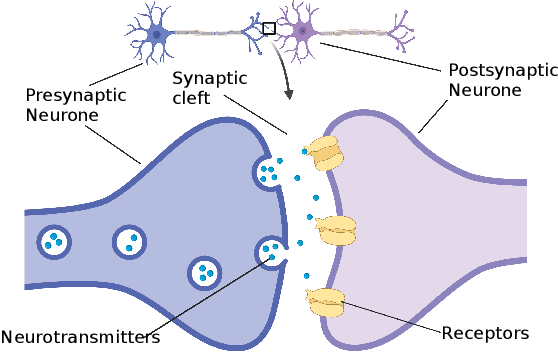
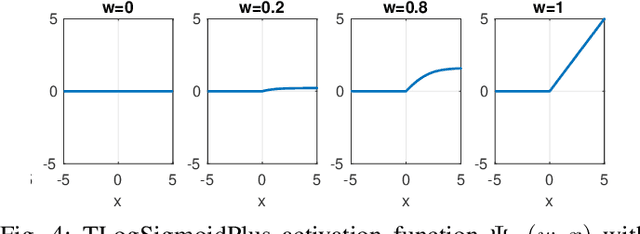
This work connects models for virus spread on networks with their equivalent neural network representations. Based on this connection, we propose a new neural network architecture, called Transmission Neural Networks (TransNNs) where activation functions are primarily associated with links and are allowed to have different activation levels. Furthermore, this connection leads to the discovery and the derivation of three new activation functions with tunable or trainable parameters. Moreover, we prove that TransNNs with a single hidden layer and a fixed non-zero bias term are universal function approximators. Finally, we present new fundamental derivations of continuous time epidemic network models based on TransNNs.
Pose Refinement with Joint Optimization of Visual Points and Lines
Oct 08, 2021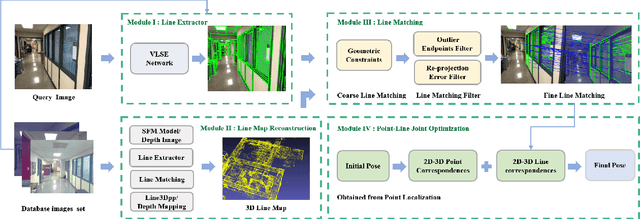
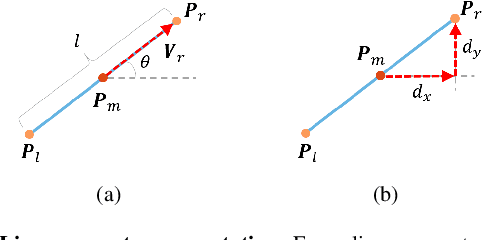
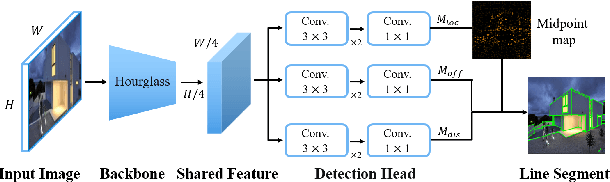
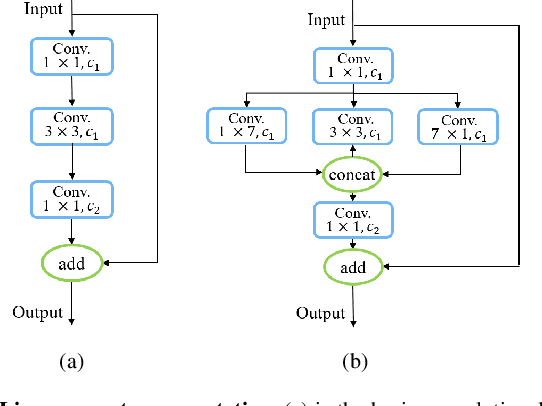
High-precision camera re-localization technology in a pre-established 3D environment map is the basis for many tasks, such as Augmented Reality, Robotics and Autonomous Driving. The point-based visual re-localization approaches are well-developed in recent decades, but are insufficient in some feature-less cases. In this paper, we propose a point-line joint optimization method for pose refinement with the help of the innovatively designed line extracting CNN named VLSE, and the line matching and pose optimization approach. We adopt a novel line representation and customize a hybrid convolutional block based on the Stacked Hourglass network, to detect accurate and stable line features on images. Then we apply a coarse-to-fine strategy to obtain precise 2D-3D line correspondences based on the geometric constraint. A following point-line joint cost function is constructed to optimize the camera pose with the initial coarse pose. Sufficient experiments are conducted on open datasets, i.e, line extractor on Wireframe and YorkUrban, localization performance on Aachen Day-Night v1.1 and InLoc, to confirm the effectiveness of our point-line joint pose optimization method.
Retrieval and Localization with Observation Constraints
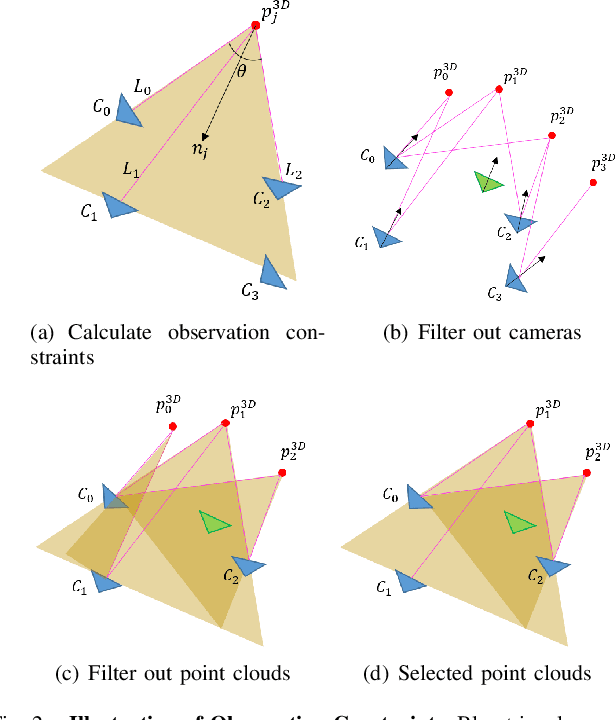
Aug 19, 2021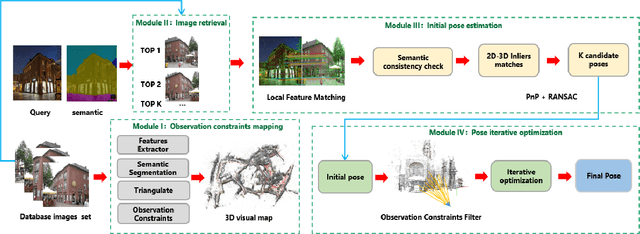
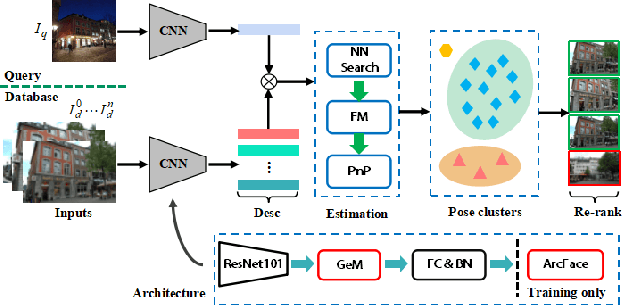

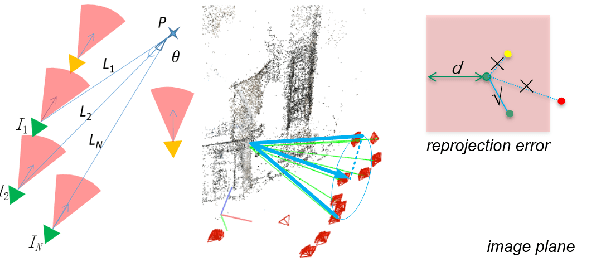
Accurate visual re-localization is very critical to many artificial intelligence applications, such as augmented reality, virtual reality, robotics and autonomous driving. To accomplish this task, we propose an integrated visual re-localization method called RLOCS by combining image retrieval, semantic consistency and geometry verification to achieve accurate estimations. The localization pipeline is designed as a coarse-to-fine paradigm. In the retrieval part, we cascade the architecture of ResNet101-GeM-ArcFace and employ DBSCAN followed by spatial verification to obtain a better initial coarse pose. We design a module called observation constraints, which combines geometry information and semantic consistency for filtering outliers. Comprehensive experiments are conducted on open datasets, including retrieval on R-Oxford5k and R-Paris6k, semantic segmentation on Cityscapes, localization on Aachen Day-Night and InLoc. By creatively modifying separate modules in the total pipeline, our method achieves many performance improvements on the challenging localization benchmarks.
Self-semi-supervised Learning to Learn from NoisyLabeled Data
Nov 03, 2020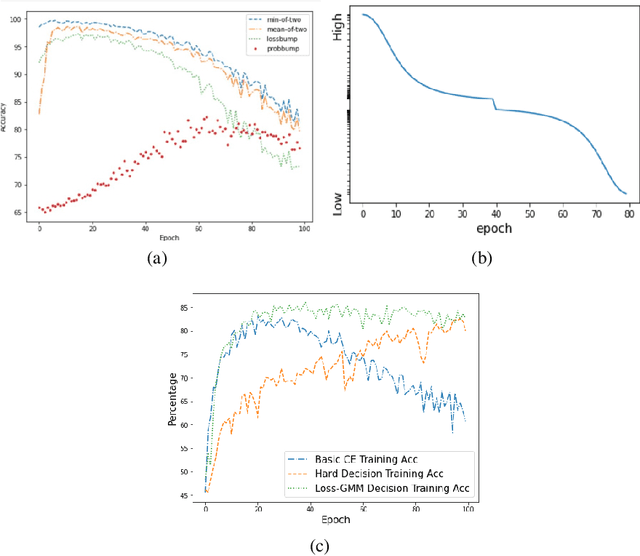
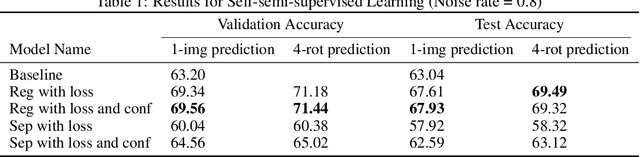
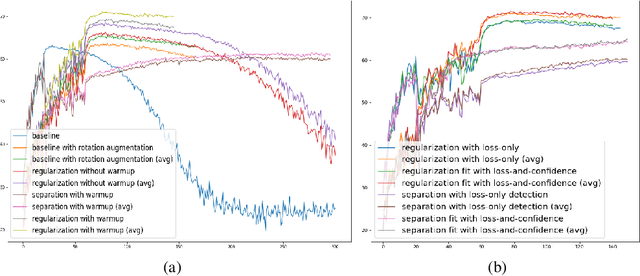
The remarkable success of today's deep neural networks highly depends on a massive number of correctly labeled data. However, it is rather costly to obtain high-quality human-labeled data, leading to the active research area of training models robust to noisy labels. To achieve this goal, on the one hand, many papers have been dedicated to differentiating noisy labels from clean ones to increase the generalization of DNN. On the other hand, the increasingly prevalent methods of self-semi-supervised learning have been proven to benefit the tasks when labels are incomplete. By 'semi' we regard the wrongly labeled data detected as un-labeled data; by 'self' we choose a self-supervised technique to conduct semi-supervised learning. In this project, we designed methods to more accurately differentiate clean and noisy labels and borrowed the wisdom of self-semi-supervised learning to train noisy labeled data.
Visual Localization Using Semantic Segmentation and Depth Prediction
May 25, 2020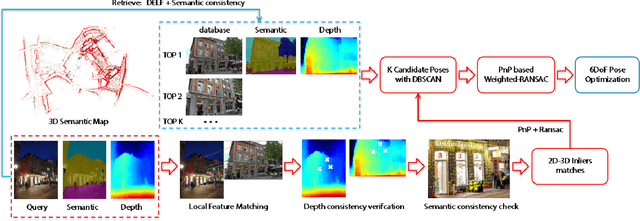

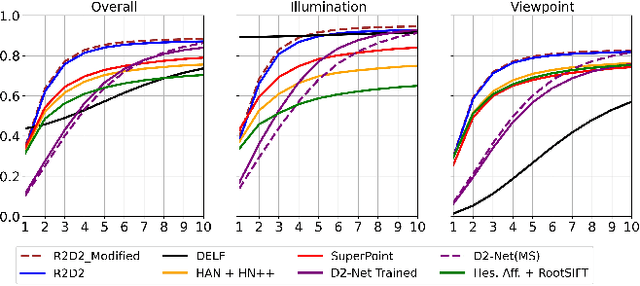

In this paper, we propose a monocular visual localization pipeline leveraging semantic and depth cues. We apply semantic consistency evaluation to rank the image retrieval results and a practical clustering technique to reject estimation outliers. In addition, we demonstrate a substantial performance boost achieved with a combination of multiple feature extractors. Furthermore, by using depth prediction with a deep neural network, we show that a significant amount of falsely matched keypoints are identified and eliminated. The proposed pipeline outperforms most of the existing approaches at the Long-Term Visual Localization benchmark 2020.