 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Trend Prediction via Continually-Aligned LLM Query Generation
Jan 24, 2026Trending news detection in low-traffic search environments faces a fundamental cold-start problem, where a lack of query volume prevents systems from identifying emerging or long-tail trends. Existing methods relying on keyword frequency or query spikes are inherently slow and ineffective in these sparse settings, lagging behind real-world shifts in attention. We introduce RTTP, a novel Real-Time Trending Prediction framework that generates search queries directly from news content instead of waiting for users to issue them. RTTP leverages a continual learning LLM (CL-LLM) that converts posts into search-style queries and scores them using engagement strength + creator authority, enabling early trend surfacing before search volume forms. To ensure adaptation without degrading reasoning, we propose Mix-Policy DPO, a new preference-based continual learning approach that combines on-policy stability with off-policy novelty to mitigate catastrophic forgetting during model upgrades. Deployed at production scale on Facebook and Meta AI products, RTTP delivers +91.4% improvement in tail-trend detection precision@500 and +19% query generation accuracy over industry baselines, while sustaining stable performance after multi-week online training. This work demonstrates that LLM-generated synthetic search signals, when aligned and continually updated, unlock timely trend understanding in low-traffic search environments.
E2Former-V2: On-the-Fly Equivariant Attention with Linear Activation Memory
Jan 23, 2026Equivariant Graph Neural Networks (EGNNs) have become a widely used approach for modeling 3D atomistic systems. However, mainstream architectures face critical scalability bottlenecks due to the explicit construction of geometric features or dense tensor products on \textit{every} edge. To overcome this, we introduce \textbf{E2Former-V2}, a scalable architecture that integrates algebraic sparsity with hardware-aware execution. We first propose \textbf{E}quivariant \textbf{A}xis-\textbf{A}ligned \textbf{S}parsification (EAAS). EAAS builds on Wigner-$6j$ convolution by exploiting an $\mathrm{SO}(3) \rightarrow \mathrm{SO}(2)$ change of basis to transform computationally expensive dense tensor contractions into efficient, sparse parity re-indexing operations. Building on this representation, we introduce \textbf{On-the-Fly Equivariant Attention}, a fully node-centric mechanism implemented via a custom fused Triton kernel. By eliminating materialized edge tensors and maximizing SRAM utilization, our kernel achieves a \textbf{20$\times$ improvement in TFLOPS} compared to standard implementations. Extensive experiments on the SPICE and OMol25 datasets demonstrate that E2Former-V2 maintains comparable predictive performance while notably accelerating inference. This work demonstrates that large equivariant transformers can be trained efficiently using widely accessible GPU platforms. The code is avalible at https://github.com/IQuestLab/UBio-MolFM/tree/e2formerv2.
Scalable Machine Learning Force Fields for Macromolecular Systems Through Long-Range Aware Message Passing
Jan 07, 2026Machine learning force fields (MLFFs) have revolutionized molecular simulations by providing quantum mechanical accuracy at the speed of molecular mechanical computations. However, a fundamental reliance of these models on fixed-cutoff architectures limits their applicability to macromolecular systems where long-range interactions dominate. We demonstrate that this locality constraint causes force prediction errors to scale monotonically with system size, revealing a critical architectural bottleneck. To overcome this, we establish the systematically designed MolLR25 ({Mol}ecules with {L}ong-{R}ange effect) benchmark up to 1200 atoms, generated using high-fidelity DFT, and introduce E2Former-LSR, an equivariant transformer that explicitly integrates long-range attention blocks. E2Former-LSR exhibits stable error scaling, achieves superior fidelity in capturing non-covalent decay, and maintains precision on complex protein conformations. Crucially, its efficient design provides up to 30% speedup compared to purely local models. This work validates the necessity of non-local architectures for generalizable MLFFs, enabling high-fidelity molecular dynamics for large-scale chemical and biological systems.
PhyGDPO: Physics-Aware Groupwise Direct Preference Optimization for Physically Consistent Text-to-Video Generation
Dec 31, 2025Recent advances in text-to-video (T2V) generation have achieved good visual quality, yet synthesizing videos that faithfully follow physical laws remains an open challenge. Existing methods mainly based on graphics or prompt extension struggle to generalize beyond simple simulated environments or learn implicit physical reasoning. The scarcity of training data with rich physics interactions and phenomena is also a problem. In this paper, we first introduce a Physics-Augmented video data construction Pipeline, PhyAugPipe, that leverages a vision-language model (VLM) with chain-of-thought reasoning to collect a large-scale training dataset, PhyVidGen-135K. Then we formulate a principled Physics-aware Groupwise Direct Preference Optimization, PhyGDPO, framework that builds upon the groupwise Plackett-Luce probabilistic model to capture holistic preferences beyond pairwise comparisons. In PhyGDPO, we design a Physics-Guided Rewarding (PGR) scheme that embeds VLM-based physics rewards to steer optimization toward physical consistency. We also propose a LoRA-Switch Reference (LoRA-SR) scheme that eliminates memory-heavy reference duplication for efficient training. Experiments show that our method significantly outperforms state-of-the-art open-source methods on PhyGenBench and VideoPhy2. Please check our project page at https://caiyuanhao1998.github.io/project/PhyGDPO for more video results. Our code, models, and data will be released at https://github.com/caiyuanhao1998/Open-PhyGDPO
Exploring MLLM-Diffusion Information Transfer with MetaCanvas
Dec 12, 2025Multimodal learning has rapidly advanced visual understanding, largely via multimodal large language models (MLLMs) that use powerful LLMs as cognitive cores. In visual generation, however, these powerful core models are typically reduced to global text encoders for diffusion models, leaving most of their reasoning and planning ability unused. This creates a gap: current multimodal LLMs can parse complex layouts, attributes, and knowledge-intensive scenes, yet struggle to generate images or videos with equally precise and structured control. We propose MetaCanvas, a lightweight framework that lets MLLMs reason and plan directly in spatial and spatiotemporal latent spaces and interface tightly with diffusion generators. We empirically implement MetaCanvas on three different diffusion backbones and evaluate it across six tasks, including text-to-image generation, text/image-to-video generation, image/video editing, and in-context video generation, each requiring precise layouts, robust attribute binding, and reasoning-intensive control. MetaCanvas consistently outperforms global-conditioning baselines, suggesting that treating MLLMs as latent-space planners is a promising direction for narrowing the gap between multimodal understanding and generation.
Classifier Language Models: Unifying Sparse Finetuning and Adaptive Tokenization for Specialized Classification Tasks
Aug 12, 2025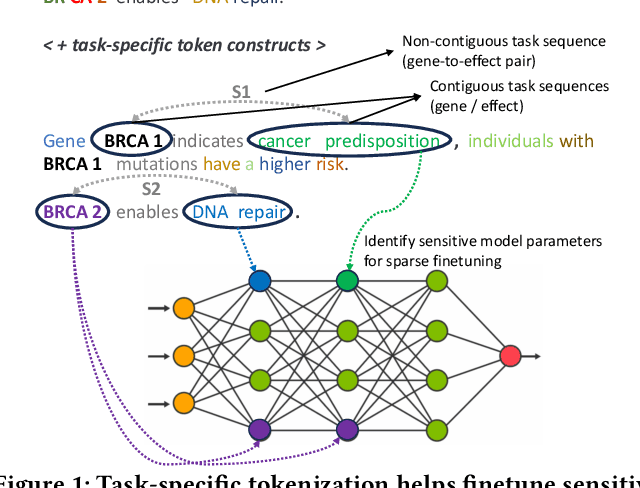



Semantic text classification requires the understanding of the contextual significance of specific tokens rather than surface-level patterns or keywords (as in rule-based or statistical text classification), making large language models (LLMs) well-suited for this task. However, semantic classification applications in industry, like customer intent detection or semantic role labeling, tend to be highly specialized. They require annotation by domain experts in contrast to general-purpose corpora for pretraining. Further, they typically require high inference throughputs which limits the model size from latency and cost perspectives. Thus, for a range of specialized classification tasks, the preferred solution is to develop customized classifiers by finetuning smaller language models (e.g., mini-encoders, small language models). In this work, we develop a token-driven sparse finetuning strategy to adapt small language models to specialized classification tasks. We identify and finetune a small sensitive subset of model parameters by leveraging task-specific token constructs in the finetuning dataset, while leaving most of the pretrained weights unchanged. Unlike adapter approaches such as low rank adaptation (LoRA), we do not introduce additional parameters to the model. Our approach identifies highly relevant semantic tokens (case study in the Appendix) and outperforms end-to-end finetuning, LoRA, layer selection, and prefix tuning on five diverse semantic classification tasks. We achieve greater stability and half the training costs vs. end-to-end finetuning.
\underline{E2}Former: A Linear-time \underline{E}fficient and \underline{E}quivariant Trans\underline{former} for Scalable Molecular Modeling
Jan 31, 2025



Equivariant Graph Neural Networks (EGNNs) have demonstrated significant success in modeling microscale systems, including those in chemistry, biology and materials science. However, EGNNs face substantial computational challenges due to the high cost of constructing edge features via spherical tensor products, making them impractical for large-scale systems. To address this limitation, we introduce E2Former, an equivariant and efficient transformer architecture that incorporates the Wigner $6j$ convolution (Wigner $6j$ Conv). By shifting the computational burden from edges to nodes, the Wigner $6j$ Conv reduces the complexity from $O(|\mathcal{E}|)$ to $ O(| \mathcal{V}|)$ while preserving both the model's expressive power and rotational equivariance. We show that this approach achieves a 7x-30x speedup compared to conventional $\mathrm{SO}(3)$ convolutions. Furthermore, our empirical results demonstrate that the derived E2Former mitigates the computational challenges of existing approaches without compromising the ability to capture detailed geometric information. This development could suggest a promising direction for scalable and efficient molecular modeling.
JailPO: A Novel Black-box Jailbreak Framework via Preference Optimization against Aligned LLMs
Dec 20, 2024Large Language Models (LLMs) aligned with human feedback have recently garnered significant attention. However, it remains vulnerable to jailbreak attacks, where adversaries manipulate prompts to induce harmful outputs. Exploring jailbreak attacks enables us to investigate the vulnerabilities of LLMs and further guides us in enhancing their security. Unfortunately, existing techniques mainly rely on handcrafted templates or generated-based optimization, posing challenges in scalability, efficiency and universality. To address these issues, we present JailPO, a novel black-box jailbreak framework to examine LLM alignment. For scalability and universality, JailPO meticulously trains attack models to automatically generate covert jailbreak prompts. Furthermore, we introduce a preference optimization-based attack method to enhance the jailbreak effectiveness, thereby improving efficiency. To analyze model vulnerabilities, we provide three flexible jailbreak patterns. Extensive experiments demonstrate that JailPO not only automates the attack process while maintaining effectiveness but also exhibits superior performance in efficiency, universality, and robustness against defenses compared to baselines. Additionally, our analysis of the three JailPO patterns reveals that attacks based on complex templates exhibit higher attack strength, whereas covert question transformations elicit riskier responses and are more likely to bypass defense mechanisms.
Domain Adaptation-based Edge Computing for Cross-Conditions Fault Diagnosis
Nov 15, 2024



Fault diagnosis technology supports the healthy operation of mechanical equipment. However, the variations conditions during the operation of mechanical equipment lead to significant disparities in data distribution, posing challenges to fault diagnosis. Furthermore, when deploying applications, traditional methods often encounter issues such as latency and data security. Therefore, conducting fault diagnosis and deploying application methods under cross-operating conditions holds significant value. This paper proposes a domain adaptation-based lightweight fault diagnosis framework for edge computing scenarios. Incorporating the local maximum mean discrepancy into knowledge transfer aligns the feature distributions of different domains in a high-dimensional feature space, to discover a common feature space across domains. The acquired fault diagnosis expertise from the cloud-model is transferred to the lightweight edge-model using adaptation knowledge transfer methods. While ensuring real-time diagnostic capabilities, accurate fault diagnosis is achieved across working conditions. We conducted validation experiments on the NVIDIA Jetson Xavier NX kit. In terms of diagnostic performance, the proposed method significantly improved diagnostic accuracy, with average increases of 34.44% and 17.33% compared to the comparison method, respectively. Regarding lightweight effectiveness, proposed method achieved an average inference speed increase of 80.47%. Additionally, compared to the cloud-model, the parameter count of the edge-model decreased by 96.37%, while the Flops decreased by 83.08%.
Large Language Model Enhanced Machine Learning Estimators for Classification
May 08, 2024Pre-trained large language models (LLM) have emerged as a powerful tool for simulating various scenarios and generating output given specific instructions and multimodal input. In this work, we analyze the specific use of LLM to enhance a classical supervised machine learning method for classification problems. We propose a few approaches to integrate LLM into a classical machine learning estimator to further enhance the prediction performance. We examine the performance of the proposed approaches through both standard supervised learning binary classification tasks, and a transfer learning task where the test data observe distribution changes compared to the training data. Numerical experiments using four publicly available datasets are conducted and suggest that using LLM to enhance classical machine learning estimators can provide significant improvement on prediction performance.