 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
FormNetV2: Multimodal Graph Contrastive Learning for Form Document Information Extraction
May 04, 2023
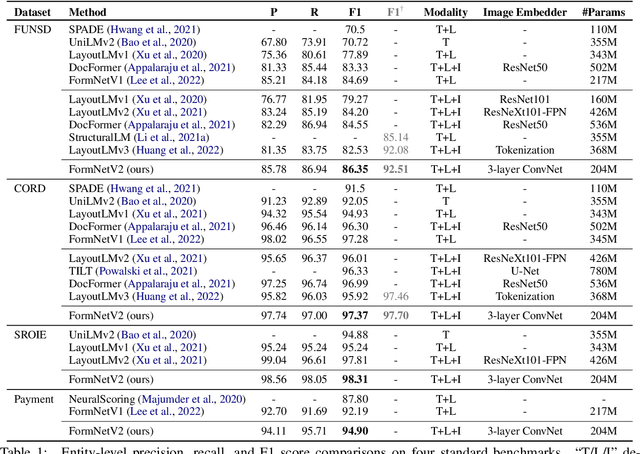
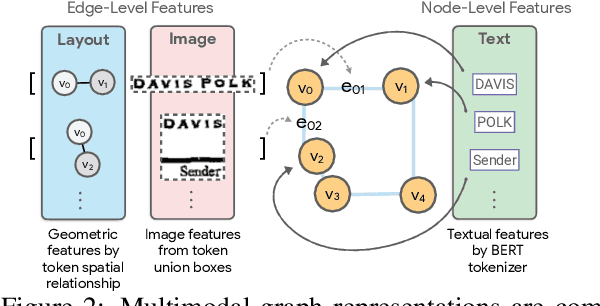
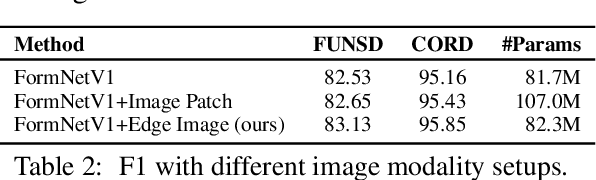
The recent advent of self-supervised pre-training techniques has led to a surge in the use of multimodal learning in form document understanding. However, existing approaches that extend the mask language modeling to other modalities require careful multi-task tuning, complex reconstruction target designs, or additional pre-training data. In FormNetV2, we introduce a centralized multimodal graph contrastive learning strategy to unify self-supervised pre-training for all modalities in one loss. The graph contrastive objective maximizes the agreement of multimodal representations, providing a natural interplay for all modalities without special customization. In addition, we extract image features within the bounding box that joins a pair of tokens connected by a graph edge, capturing more targeted visual cues without loading a sophisticated and separately pre-trained image embedder. FormNetV2 establishes new state-of-the-art performance on FUNSD, CORD, SROIE and Payment benchmarks with a more compact model size.
Text Reading Order in Uncontrolled Conditions by Sparse Graph Segmentation
May 04, 2023



Text reading order is a crucial aspect in the output of an OCR engine, with a large impact on downstream tasks. Its difficulty lies in the large variation of domain specific layout structures, and is further exacerbated by real-world image degradations such as perspective distortions. We propose a lightweight, scalable and generalizable approach to identify text reading order with a multi-modal, multi-task graph convolutional network (GCN) running on a sparse layout based graph. Predictions from the model provide hints of bidimensional relations among text lines and layout region structures, upon which a post-processing cluster-and-sort algorithm generates an ordered sequence of all the text lines. The model is language-agnostic and runs effectively across multi-language datasets that contain various types of images taken in uncontrolled conditions, and it is small enough to be deployed on virtually any platform including mobile devices.
FormNet: Structural Encoding beyond Sequential Modeling in Form Document Information Extraction
Mar 24, 2022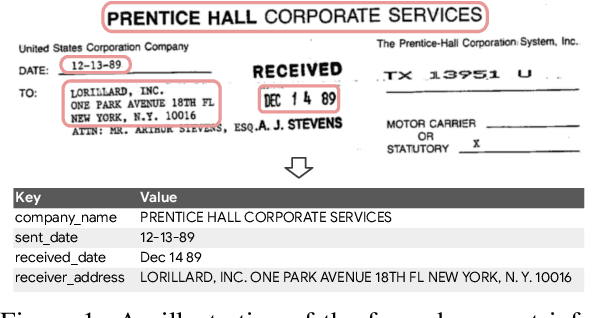
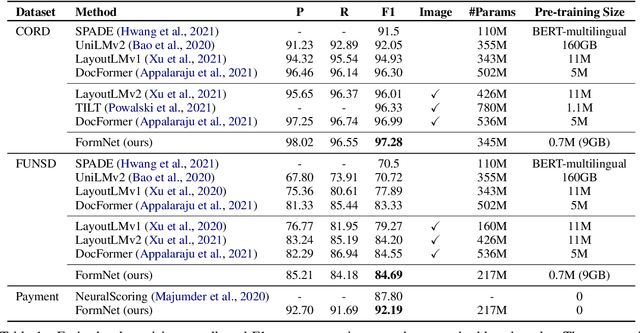
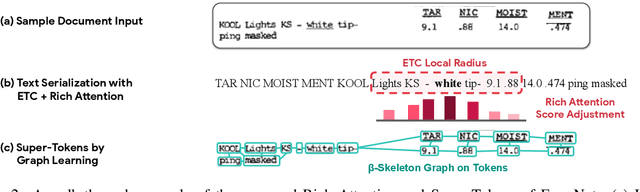
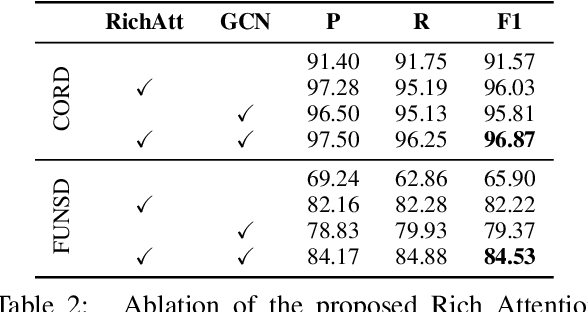
Sequence modeling has demonstrated state-of-the-art performance on natural language and document understanding tasks. However, it is challenging to correctly serialize tokens in form-like documents in practice due to their variety of layout patterns. We propose FormNet, a structure-aware sequence model to mitigate the suboptimal serialization of forms. First, we design Rich Attention that leverages the spatial relationship between tokens in a form for more precise attention score calculation. Second, we construct Super-Tokens for each word by embedding representations from their neighboring tokens through graph convolutions. FormNet therefore explicitly recovers local syntactic information that may have been lost during serialization. In experiments, FormNet outperforms existing methods with a more compact model size and less pre-training data, establishing new state-of-the-art performance on CORD, FUNSD and Payment benchmarks.
Unified Line and Paragraph Detection by Graph Convolutional Networks
Mar 17, 2022



We formulate the task of detecting lines and paragraphs in a document into a unified two-level clustering problem. Given a set of text detection boxes that roughly correspond to words, a text line is a cluster of boxes and a paragraph is a cluster of lines. These clusters form a two-level tree that represents a major part of the layout of a document. We use a graph convolutional network to predict the relations between text detection boxes and then build both levels of clusters from these predictions. Experimentally, we demonstrate that the unified approach can be highly efficient while still achieving state-of-the-art quality for detecting paragraphs in public benchmarks and real-world images.
ROPE: Reading Order Equivariant Positional Encoding for Graph-based Document Information Extraction
Jun 21, 2021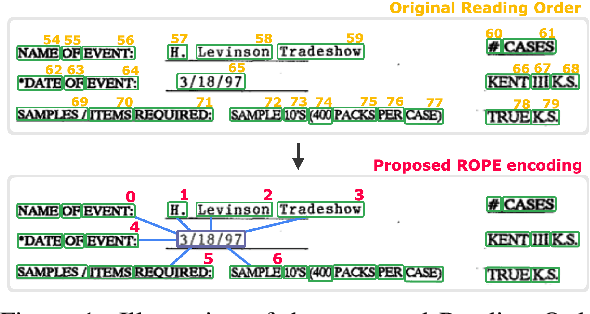
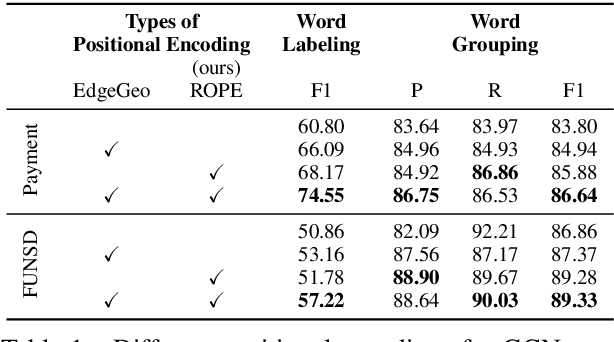
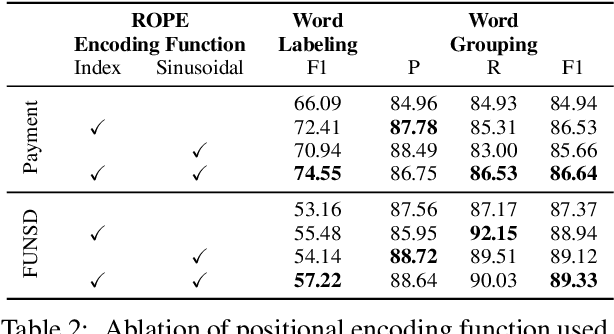
Natural reading orders of words are crucial for information extraction from form-like documents. Despite recent advances in Graph Convolutional Networks (GCNs) on modeling spatial layout patterns of documents, they have limited ability to capture reading orders of given word-level node representations in a graph. We propose Reading Order Equivariant Positional Encoding (ROPE), a new positional encoding technique designed to apprehend the sequential presentation of words in documents. ROPE generates unique reading order codes for neighboring words relative to the target word given a word-level graph connectivity. We study two fundamental document entity extraction tasks including word labeling and word grouping on the public FUNSD dataset and a large-scale payment dataset. We show that ROPE consistently improves existing GCNs with a margin up to 8.4% F1-score.
General-Purpose OCR Paragraph Identification by Graph Convolutional Neural Networks
Feb 01, 2021
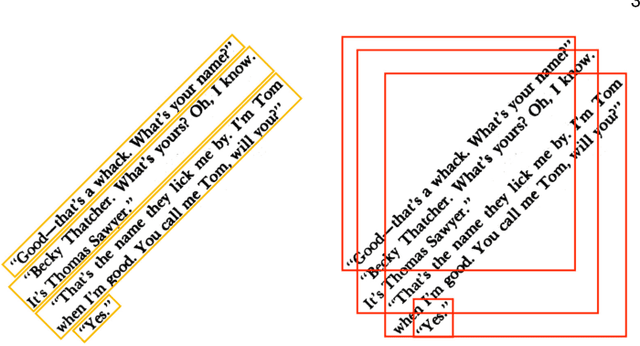
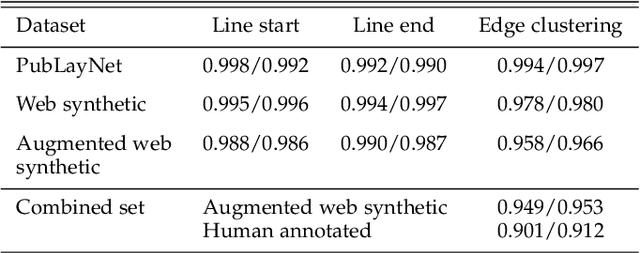
Paragraphs are an important class of document entities. We propose a new approach for paragraph identification by spatial graph convolutional neural networks (GCN) applied on OCR text boxes. Two steps, namely line splitting and line clustering, are performed to extract paragraphs from the lines in OCR results. Each step uses a beta-skeleton graph constructed from bounding boxes, where the graph edges provide efficient support for graph convolution operations. With only pure layout input features, the GCN model size is 3~4 orders of magnitude smaller compared to R-CNN based models, while achieving comparable or better accuracies on PubLayNet and other datasets. Furthermore, the GCN models show good generalization from synthetic training data to real-world images, and good adaptivity for variable document styles.