 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Prompting for Multi-Concept Video Customization by Autoregressive Generation
May 22, 2024We present a method for multi-concept customization of pretrained text-to-video (T2V) models. Intuitively, the multi-concept customized video can be derived from the (non-linear) intersection of the video manifolds of the individual concepts, which is not straightforward to find. We hypothesize that sequential and controlled walking towards the intersection of the video manifolds, directed by text prompting, leads to the solution. To do so, we generate the various concepts and their corresponding interactions, sequentially, in an autoregressive manner. Our method can generate videos of multiple custom concepts (subjects, action and background) such as a teddy bear running towards a brown teapot, a dog playing violin and a teddy bear swimming in the ocean. We quantitatively evaluate our method using videoCLIP and DINO scores, in addition to human evaluation. Videos for results presented in this paper can be found at https://github.com/divyakraman/MultiConceptVideo2024.
Robust Disaster Assessment from Aerial Imagery Using Text-to-Image Synthetic Data
May 22, 2024We present a simple and efficient method to leverage emerging text-to-image generative models in creating large-scale synthetic supervision for the task of damage assessment from aerial images. While significant recent advances have resulted in improved techniques for damage assessment using aerial or satellite imagery, they still suffer from poor robustness to domains where manual labeled data is unavailable, directly impacting post-disaster humanitarian assistance in such under-resourced geographies. Our contribution towards improving domain robustness in this scenario is two-fold. Firstly, we leverage the text-guided mask-based image editing capabilities of generative models and build an efficient and easily scalable pipeline to generate thousands of post-disaster images from low-resource domains. Secondly, we propose a simple two-stage training approach to train robust models while using manual supervision from different source domains along with the generated synthetic target domain data. We validate the strength of our proposed framework under cross-geography domain transfer setting from xBD and SKAI images in both single-source and multi-source settings, achieving significant improvements over a source-only baseline in each case.
DreamFlow: High-Quality Text-to-3D Generation by Approximating Probability Flow
Mar 22, 2024Recent progress in text-to-3D generation has been achieved through the utilization of score distillation methods: they make use of the pre-trained text-to-image (T2I) diffusion models by distilling via the diffusion model training objective. However, such an approach inevitably results in the use of random timesteps at each update, which increases the variance of the gradient and ultimately prolongs the optimization process. In this paper, we propose to enhance the text-to-3D optimization by leveraging the T2I diffusion prior in the generative sampling process with a predetermined timestep schedule. To this end, we interpret text-to3D optimization as a multi-view image-to-image translation problem, and propose a solution by approximating the probability flow. By leveraging the proposed novel optimization algorithm, we design DreamFlow, a practical three-stage coarseto-fine text-to-3D optimization framework that enables fast generation of highquality and high-resolution (i.e., 1024x1024) 3D contents. For example, we demonstrate that DreamFlow is 5 times faster than the existing state-of-the-art text-to-3D method, while producing more photorealistic 3D contents. Visit our project page (https://kyungmnlee.github.io/dreamflow.github.io/) for visualizations.
Direct Consistency Optimization for Compositional Text-to-Image Personalization
Feb 19, 2024Text-to-image (T2I) diffusion models, when fine-tuned on a few personal images, are able to generate visuals with a high degree of consistency. However, they still lack in synthesizing images of different scenarios or styles that are possible in the original pretrained models. To address this, we propose to fine-tune the T2I model by maximizing consistency to reference images, while penalizing the deviation from the pretrained model. We devise a novel training objective for T2I diffusion models that minimally fine-tunes the pretrained model to achieve consistency. Our method, dubbed \emph{Direct Consistency Optimization}, is as simple as regular diffusion loss, while significantly enhancing the compositionality of personalized T2I models. Also, our approach induces a new sampling method that controls the tradeoff between image fidelity and prompt fidelity. Lastly, we emphasize the necessity of using a comprehensive caption for reference images to further enhance the image-text alignment. We show the efficacy of the proposed method on the T2I personalization for subject, style, or both. In particular, our method results in a superior Pareto frontier to the baselines. Generated examples and codes are in our project page( https://dco-t2i.github.io/).
Unsupervised LLM Adaptation for Question Answering
Feb 16, 2024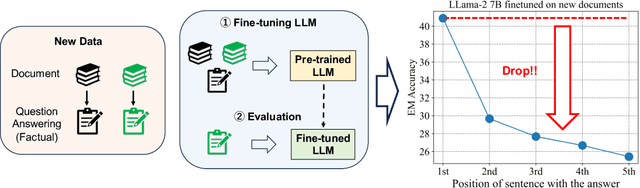

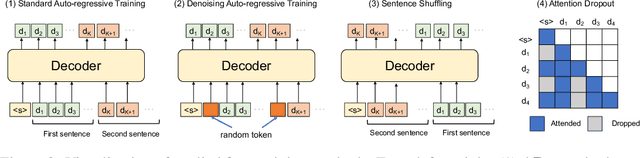
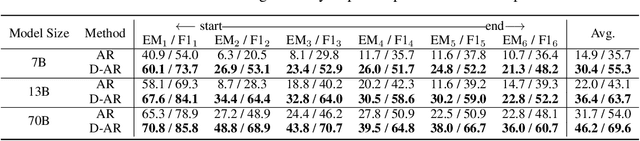
Large language models (LLM) learn diverse knowledge present in the large-scale training dataset via self-supervised training. Followed by instruction-tuning, LLM acquires the ability to return correct information for diverse questions. However, adapting these pre-trained LLMs to new target domains, such as different organizations or periods, for the question-answering (QA) task incurs a substantial annotation cost. To tackle this challenge, we propose a novel task, unsupervised LLM adaptation for question answering. In this task, we leverage a pre-trained LLM, a publicly available QA dataset (source data), and unlabeled documents from the target domain. Our goal is to learn LLM that can answer questions about the target domain. We introduce one synthetic and two real datasets to evaluate models fine-tuned on the source and target data, and reveal intriguing insights; (i) fine-tuned models exhibit the ability to provide correct answers for questions about the target domain even though they do not see any questions about the information described in the unlabeled documents, but (ii) they have difficulties in accessing information located in the middle or at the end of documents, and (iii) this challenge can be partially mitigated by replacing input tokens with random ones during adaptation.
Instruct-Imagen: Image Generation with Multi-modal Instruction
Jan 03, 2024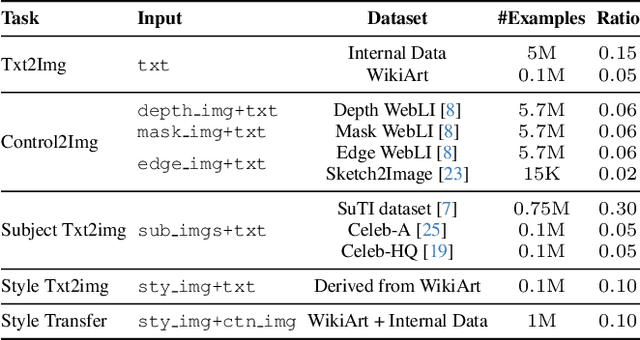

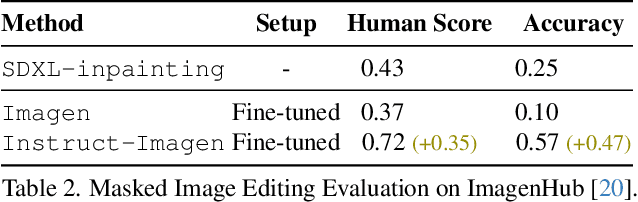
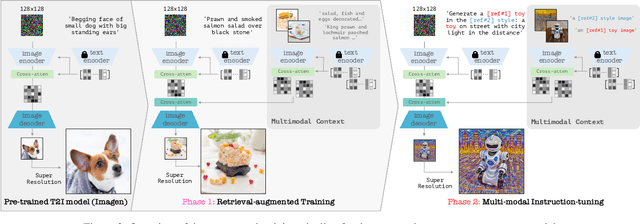
This paper presents instruct-imagen, a model that tackles heterogeneous image generation tasks and generalizes across unseen tasks. We introduce *multi-modal instruction* for image generation, a task representation articulating a range of generation intents with precision. It uses natural language to amalgamate disparate modalities (e.g., text, edge, style, subject, etc.), such that abundant generation intents can be standardized in a uniform format. We then build instruct-imagen by fine-tuning a pre-trained text-to-image diffusion model with a two-stage framework. First, we adapt the model using the retrieval-augmented training, to enhance model's capabilities to ground its generation on external multimodal context. Subsequently, we fine-tune the adapted model on diverse image generation tasks that requires vision-language understanding (e.g., subject-driven generation, etc.), each paired with a multi-modal instruction encapsulating the task's essence. Human evaluation on various image generation datasets reveals that instruct-imagen matches or surpasses prior task-specific models in-domain and demonstrates promising generalization to unseen and more complex tasks.
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023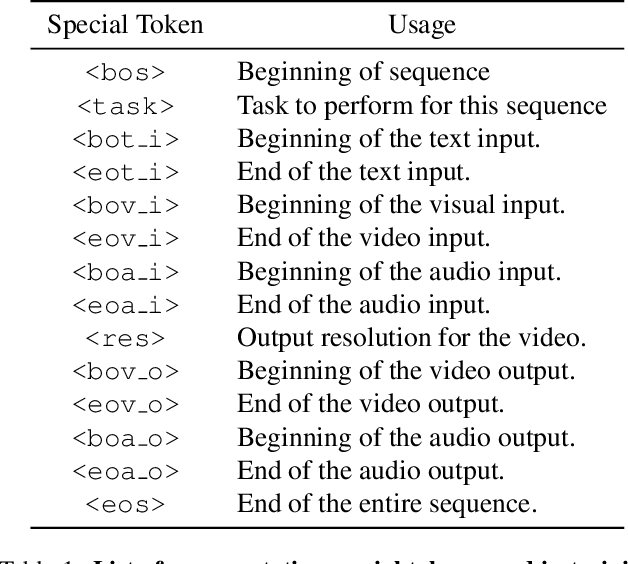



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
Photorealistic Video Generation with Diffusion Models
Dec 11, 2023We present W.A.L.T, a transformer-based approach for photorealistic video generation via diffusion modeling. Our approach has two key design decisions. First, we use a causal encoder to jointly compress images and videos within a unified latent space, enabling training and generation across modalities. Second, for memory and training efficiency, we use a window attention architecture tailored for joint spatial and spatiotemporal generative modeling. Taken together these design decisions enable us to achieve state-of-the-art performance on established video (UCF-101 and Kinetics-600) and image (ImageNet) generation benchmarks without using classifier free guidance. Finally, we also train a cascade of three models for the task of text-to-video generation consisting of a base latent video diffusion model, and two video super-resolution diffusion models to generate videos of $512 \times 896$ resolution at $8$ frames per second.
Improve Supervised Representation Learning with Masked Image Modeling
Dec 01, 2023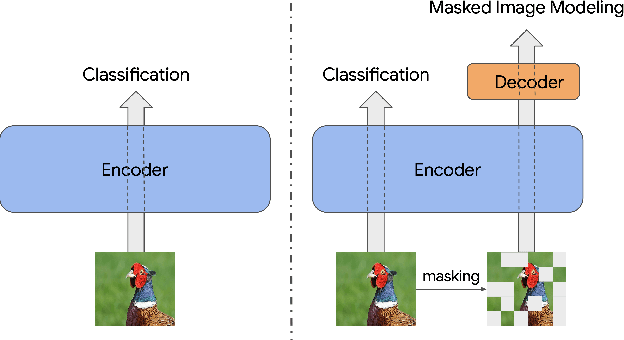
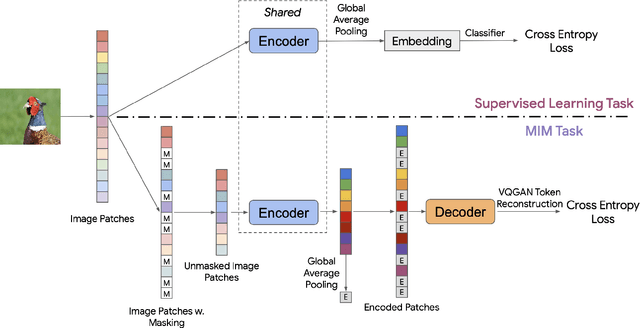
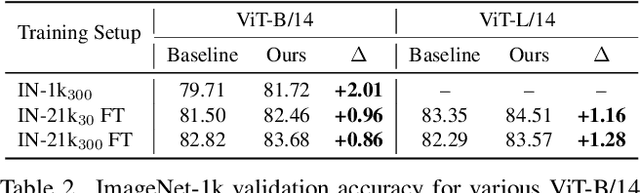
Training visual embeddings with labeled data supervision has been the de facto setup for representation learning in computer vision. Inspired by recent success of adopting masked image modeling (MIM) in self-supervised representation learning, we propose a simple yet effective setup that can easily integrate MIM into existing supervised training paradigms. In our design, in addition to the original classification task applied to a vision transformer image encoder, we add a shallow transformer-based decoder on top of the encoder and introduce an MIM task which tries to reconstruct image tokens based on masked image inputs. We show with minimal change in architecture and no overhead in inference that this setup is able to improve the quality of the learned representations for downstream tasks such as classification, image retrieval, and semantic segmentation. We conduct a comprehensive study and evaluation of our setup on public benchmarks. On ImageNet-1k, our ViT-B/14 model achieves 81.72% validation accuracy, 2.01% higher than the baseline model. On K-Nearest-Neighbor image retrieval evaluation with ImageNet-1k, the same model outperforms the baseline by 1.32%. We also show that this setup can be easily scaled to larger models and datasets. Code and checkpoints will be released.
Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation
Oct 09, 2023While Large Language Models (LLMs) are the dominant models for generative tasks in language, they do not perform as well as diffusion models on image and video generation. To effectively use LLMs for visual generation, one crucial component is the visual tokenizer that maps pixel-space inputs to discrete tokens appropriate for LLM learning. In this paper, we introduce MAGVIT-v2, a video tokenizer designed to generate concise and expressive tokens for both videos and images using a common token vocabulary. Equipped with this new tokenizer, we show that LLMs outperform diffusion models on standard image and video generation benchmarks including ImageNet and Kinetics. In addition, we demonstrate that our tokenizer surpasses the previously top-performing video tokenizer on two more tasks: (1) video compression comparable to the next-generation video codec (VCC) according to human evaluations, and (2) learning effective representations for action recognition tasks.