 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023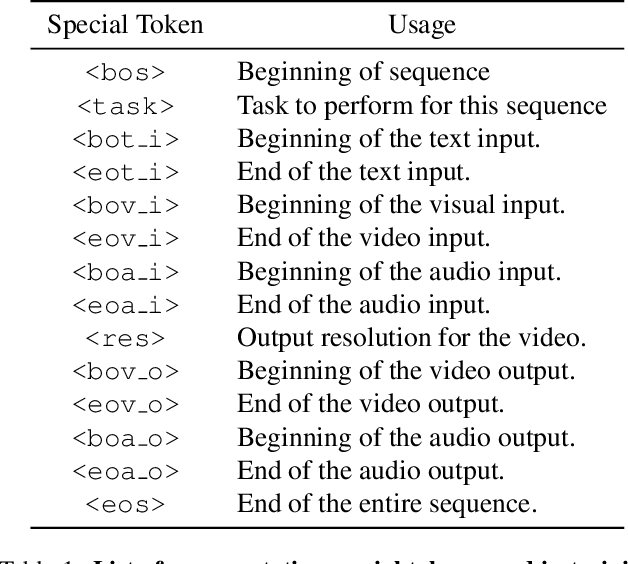



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
Diversity and Diffusion: Observations on Synthetic Image Distributions with Stable Diffusion
Oct 31, 2023Recent progress in text-to-image (TTI) systems, such as StableDiffusion, Imagen, and DALL-E 2, have made it possible to create realistic images with simple text prompts. It is tempting to use these systems to eliminate the manual task of obtaining natural images for training a new machine learning classifier. However, in all of the experiments performed to date, classifiers trained solely with synthetic images perform poorly at inference, despite the images used for training appearing realistic. Examining this apparent incongruity in detail gives insight into the limitations of the underlying image generation processes. Through the lens of diversity in image creation vs.accuracy of what is created, we dissect the differences in semantic mismatches in what is modeled in synthetic vs. natural images. This will elucidate the roles of the image-languag emodel, CLIP, and the image generation model, diffusion. We find four issues that limit the usefulness of TTI systems for this task: ambiguity, adherence to prompt, lack of diversity, and inability to represent the underlying concept. We further present surprising insights into the geometry of CLIP embeddings.