 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Images from Images: Interleaving Denoising and Transformation
Nov 24, 2024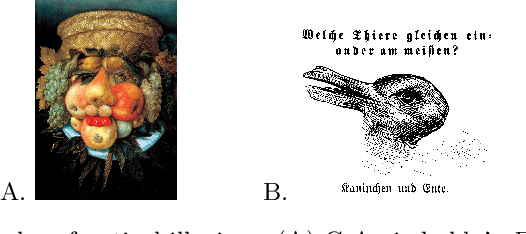

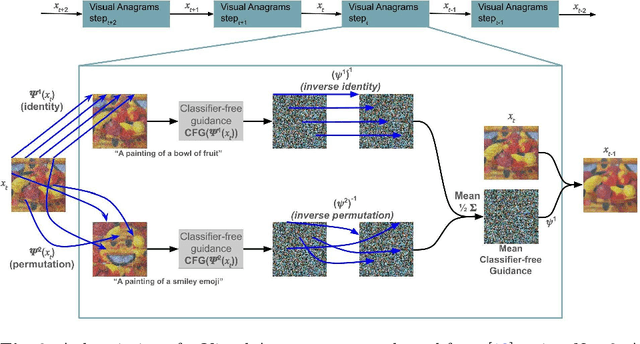

Simply by rearranging the regions of an image, we can create a new image of any subject matter. The definition of regions is user definable, ranging from regularly and irregularly-shaped blocks, concentric rings, or even individual pixels. Our method extends and improves recent work in the generation of optical illusions by simultaneously learning not only the content of the images, but also the parameterized transformations required to transform the desired images into each other. By learning the image transforms, we allow any source image to be pre-specified; any existing image (e.g. the Mona Lisa) can be transformed to a novel subject. We formulate this process as a constrained optimization problem and address it through interleaving the steps of image diffusion with an energy minimization step. Unlike previous methods, increasing the number of regions actually makes the problem easier and improves results. We demonstrate our approach in both pixel and latent spaces. Creative extensions, such as using infinite copies of the source image and employing multiple source images, are also given.
Diversity and Diffusion: Observations on Synthetic Image Distributions with Stable Diffusion
Oct 31, 2023Recent progress in text-to-image (TTI) systems, such as StableDiffusion, Imagen, and DALL-E 2, have made it possible to create realistic images with simple text prompts. It is tempting to use these systems to eliminate the manual task of obtaining natural images for training a new machine learning classifier. However, in all of the experiments performed to date, classifiers trained solely with synthetic images perform poorly at inference, despite the images used for training appearing realistic. Examining this apparent incongruity in detail gives insight into the limitations of the underlying image generation processes. Through the lens of diversity in image creation vs.accuracy of what is created, we dissect the differences in semantic mismatches in what is modeled in synthetic vs. natural images. This will elucidate the roles of the image-languag emodel, CLIP, and the image generation model, diffusion. We find four issues that limit the usefulness of TTI systems for this task: ambiguity, adherence to prompt, lack of diversity, and inability to represent the underlying concept. We further present surprising insights into the geometry of CLIP embeddings.
Table-Based Neural Units: Fully Quantizing Networks for Multiply-Free Inference
Jun 11, 2019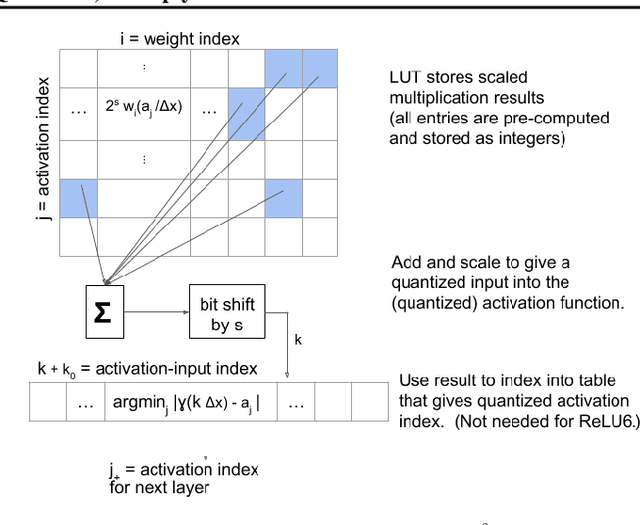
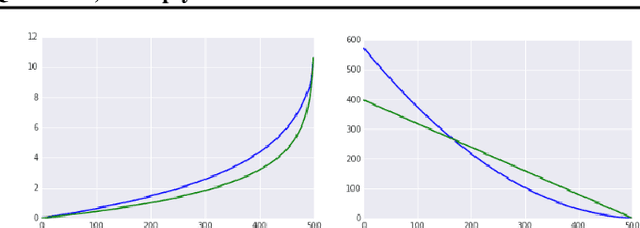
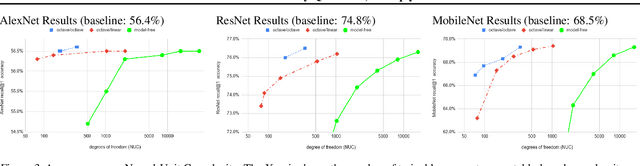
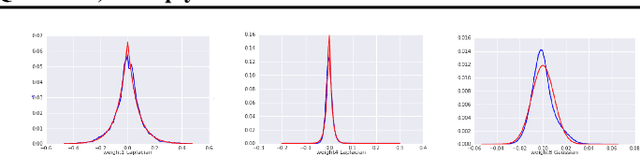
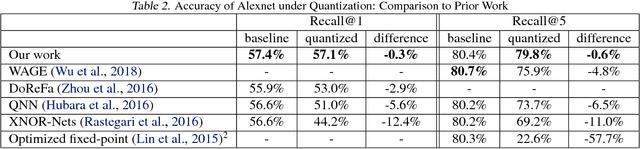
In this work, we propose to quantize all parts of standard classification networks and replace the activation-weight--multiply step with a simple table-based lookup. This approach results in networks that are free of floating-point operations and free of multiplications, suitable for direct FPGA and ASIC implementations. It also provides us with two simple measures of per-layer and network-wide compactness as well as insight into the distribution characteristics of activationoutput and weight values. We run controlled studies across different quantization schemes, both fixed and adaptive and, within the set of adaptive approaches, both parametric and model-free. We implement our approach to quantization with minimal, localized changes to the training process, allowing us to benefit from advances in training continuous-valued network architectures. We apply our approach successfully to AlexNet, ResNet, and MobileNet. We show results that are within 1.6% of the reported, non-quantized performance on MobileNet using only 40 entries in our table. This performance gap narrows to zero when we allow tables with 320 entries. Our results give the best accuracies among multiply-free networks.
No Multiplication? No Floating Point? No Problem! Training Networks for Efficient Inference
Sep 28, 2018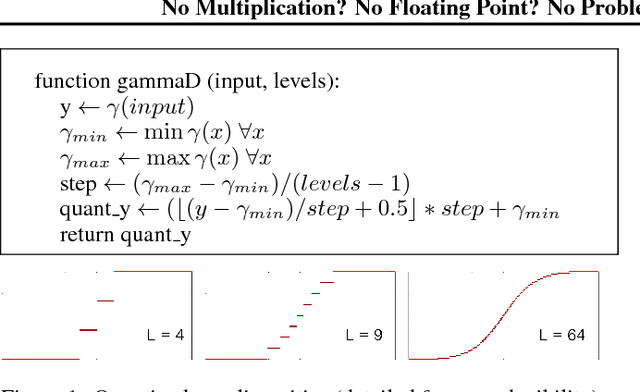
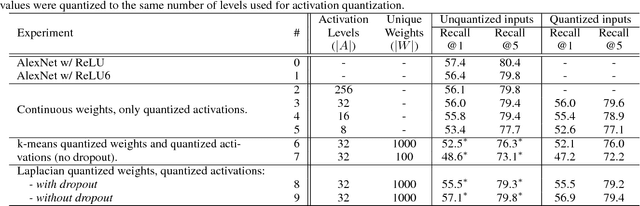
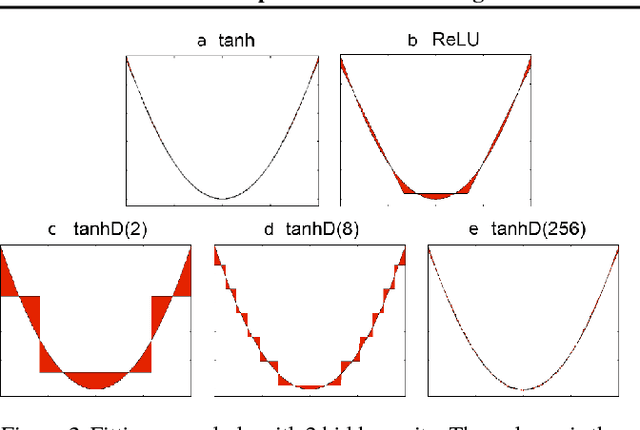
For successful deployment of deep neural networks on highly--resource-constrained devices (hearing aids, earbuds, wearables), we must simplify the types of operations and the memory/power resources used during inference. Completely avoiding inference-time floating-point operations is one of the simplest ways to design networks for these highly-constrained environments. By discretizing both our in-network non-linearities and our network weights, we can move to simple, compact networks without floating point operations, without multiplications, and avoid all non-linear function computations. Our approach allows us to explore the spectrum of possible networks, ranging from fully continuous versions down to networks with bi-level weights and activations. Our results show that discretization can be done without loss of performance and that we can train a network that will successfully operate without floating-point, without multiplication, and with less RAM on both regression tasks (auto encoding) and multi-class classification tasks (ImageNet). The memory needed to deploy our discretized networks is less than one third of the equivalent architecture that does use floating-point operations.
Representing Images in 200 Bytes: Compression via Triangulation
Sep 20, 2018

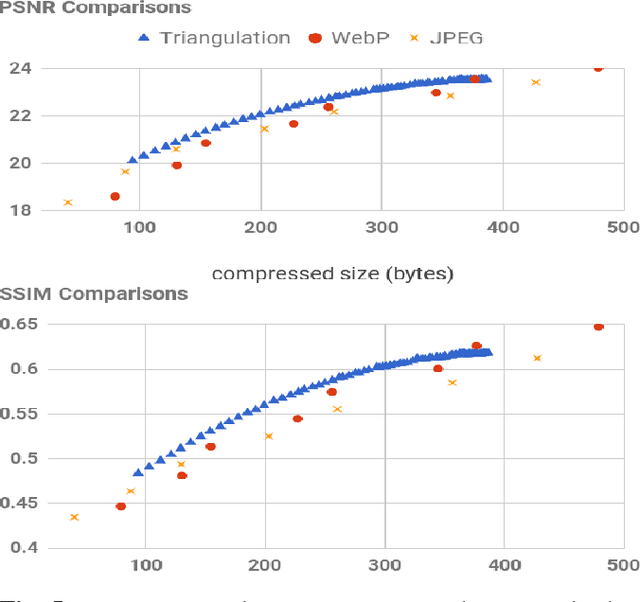
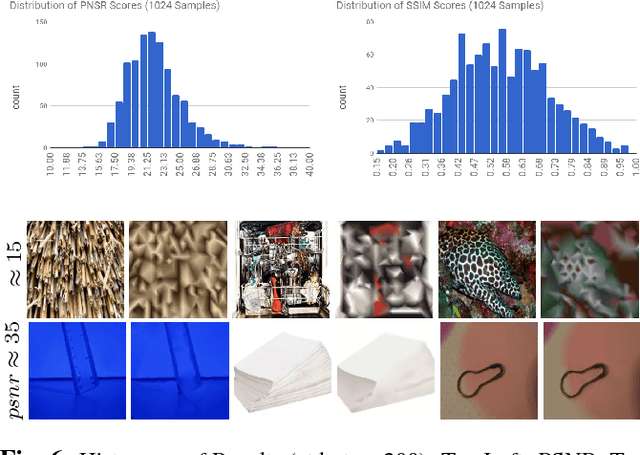
A rapidly increasing portion of internet traffic is dominated by requests from mobile devices with limited and metered bandwidth constraints. To satisfy these requests, it has become standard practice for websites to transmit small and extremely compressed image previews as part of the initial page load process to improve responsiveness. Increasing thumbnail compression beyond the capabilities of existing codecs is therefore an active research direction. In this work, we concentrate on extreme compression rates, where the size of the image is typically 200 bytes or less. First, we propose a novel approach for image compression that, unlike commonly used methods, does not rely on block-based statistics. We use an approach based on an adaptive triangulation of the target image, devoting more triangles to high entropy regions of the image. Second, we present a novel algorithm for encoding the triangles. The results show favorable statistics, in terms of PSNR and SSIM, over both the JPEG and the WebP standards.