 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Is Not All You Need: Multimodal Prompting Helps LLMs Understand Humor
Dec 01, 2024
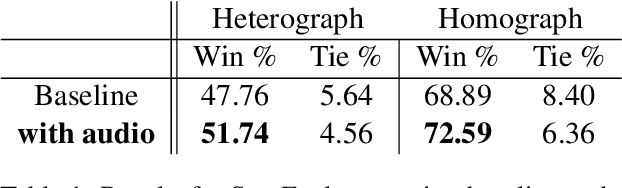

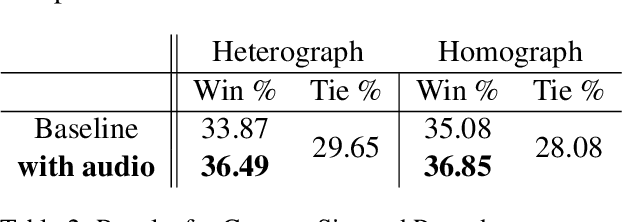
While Large Language Models (LLMs) have demonstrated impressive natural language understanding capabilities across various text-based tasks, understanding humor has remained a persistent challenge. Humor is frequently multimodal, relying on phonetic ambiguity, rhythm and timing to convey meaning. In this study, we explore a simple multimodal prompting approach to humor understanding and explanation. We present an LLM with both the text and the spoken form of a joke, generated using an off-the-shelf text-to-speech (TTS) system. Using multimodal cues improves the explanations of humor compared to textual prompts across all tested datasets.
Making Images from Images: Interleaving Denoising and Transformation
Nov 24, 2024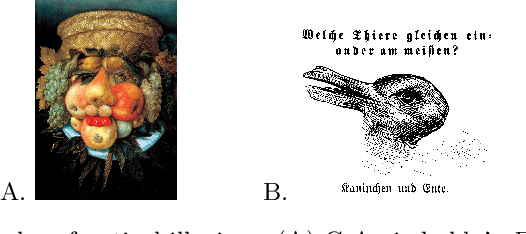

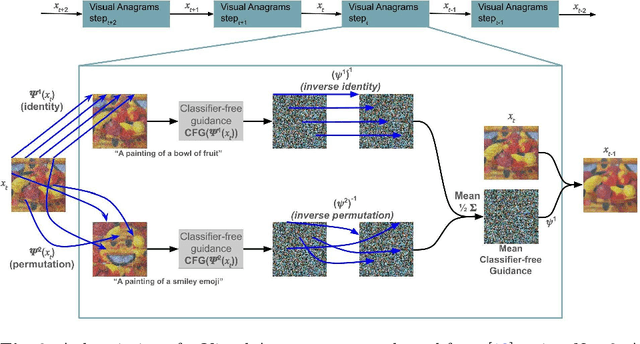

Simply by rearranging the regions of an image, we can create a new image of any subject matter. The definition of regions is user definable, ranging from regularly and irregularly-shaped blocks, concentric rings, or even individual pixels. Our method extends and improves recent work in the generation of optical illusions by simultaneously learning not only the content of the images, but also the parameterized transformations required to transform the desired images into each other. By learning the image transforms, we allow any source image to be pre-specified; any existing image (e.g. the Mona Lisa) can be transformed to a novel subject. We formulate this process as a constrained optimization problem and address it through interleaving the steps of image diffusion with an energy minimization step. Unlike previous methods, increasing the number of regions actually makes the problem easier and improves results. We demonstrate our approach in both pixel and latent spaces. Creative extensions, such as using infinite copies of the source image and employing multiple source images, are also given.