 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMALT Diffusion: Memory-Augmented Latent Transformers for Any-Length Video Generation
Feb 18, 2025Diffusion models are successful for synthesizing high-quality videos but are limited to generating short clips (e.g., 2-10 seconds). Synthesizing sustained footage (e.g. over minutes) still remains an open research question. In this paper, we propose MALT Diffusion (using Memory-Augmented Latent Transformers), a new diffusion model specialized for long video generation. MALT Diffusion (or just MALT) handles long videos by subdividing them into short segments and doing segment-level autoregressive generation. To achieve this, we first propose recurrent attention layers that encode multiple segments into a compact memory latent vector; by maintaining this memory vector over time, MALT is able to condition on it and continuously generate new footage based on a long temporal context. We also present several training techniques that enable the model to generate frames over a long horizon with consistent quality and minimal degradation. We validate the effectiveness of MALT through experiments on long video benchmarks. We first perform extensive analysis of MALT in long-contextual understanding capability and stability using popular long video benchmarks. For example, MALT achieves an FVD score of 220.4 on 128-frame video generation on UCF-101, outperforming the previous state-of-the-art of 648.4. Finally, we explore MALT's capabilities in a text-to-video generation setting and show that it can produce long videos compared with recent techniques for long text-to-video generation.
Learning Complex Non-Rigid Image Edits from Multimodal Conditioning
Dec 13, 2024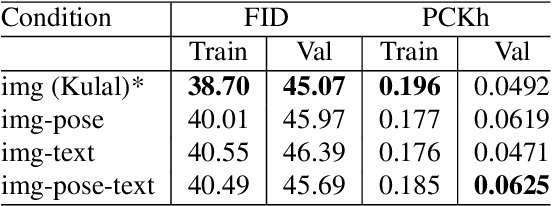


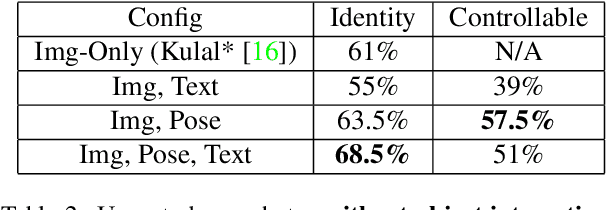
In this paper we focus on inserting a given human (specifically, a single image of a person) into a novel scene. Our method, which builds on top of Stable Diffusion, yields natural looking images while being highly controllable with text and pose. To accomplish this we need to train on pairs of images, the first a reference image with the person, the second a "target image" showing the same person (with a different pose and possibly in a different background). Additionally we require a text caption describing the new pose relative to that in the reference image. In this paper we present a novel dataset following this criteria, which we create using pairs of frames from human-centric and action-rich videos and employing a multimodal LLM to automatically summarize the difference in human pose for the text captions. We demonstrate that identity preservation is a more challenging task in scenes "in-the-wild", and especially scenes where there is an interaction between persons and objects. Combining the weak supervision from noisy captions, with robust 2D pose improves the quality of person-object interactions.
Principles of Visual Tokens for Efficient Video Understanding
Nov 20, 2024



Video understanding has made huge strides in recent years, relying largely on the power of the transformer architecture. As this architecture is notoriously expensive and video is highly redundant, research into improving efficiency has become particularly relevant. This has led to many creative solutions, including token merging and token selection. While most methods succeed in reducing the cost of the model and maintaining accuracy, an interesting pattern arises: most methods do not outperform the random sampling baseline. In this paper we take a closer look at this phenomenon and make several observations. First, we develop an oracle for the value of tokens which exposes a clear Pareto distribution where most tokens have remarkably low value, and just a few carry most of the perceptual information. Second, we analyze why this oracle is extremely hard to learn, as it does not consistently coincide with visual cues. Third, we observe that easy videos need fewer tokens to maintain accuracy. We build on these and further insights to propose a lightweight video model we call LITE that can select a small number of tokens effectively, outperforming state-of-the-art and existing baselines across datasets (Kinetics400 and Something-Something-V2) in the challenging trade-off of computation (GFLOPs) vs accuracy.
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Oct 09, 2024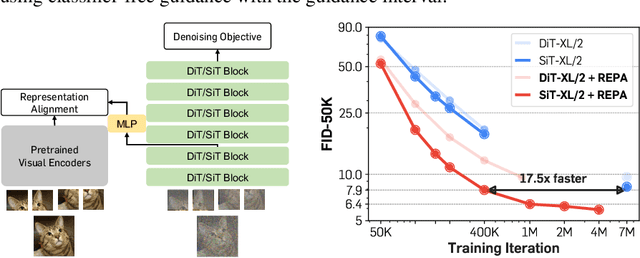

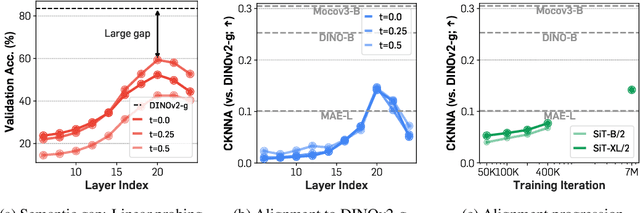
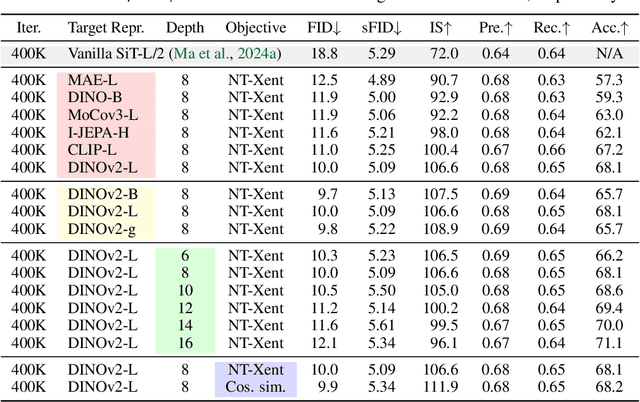
Recent studies have shown that the denoising process in (generative) diffusion models can induce meaningful (discriminative) representations inside the model, though the quality of these representations still lags behind those learned through recent self-supervised learning methods. We argue that one main bottleneck in training large-scale diffusion models for generation lies in effectively learning these representations. Moreover, training can be made easier by incorporating high-quality external visual representations, rather than relying solely on the diffusion models to learn them independently. We study this by introducing a straightforward regularization called REPresentation Alignment (REPA), which aligns the projections of noisy input hidden states in denoising networks with clean image representations obtained from external, pretrained visual encoders. The results are striking: our simple strategy yields significant improvements in both training efficiency and generation quality when applied to popular diffusion and flow-based transformers, such as DiTs and SiTs. For instance, our method can speed up SiT training by over 17.5$\times$, matching the performance (without classifier-free guidance) of a SiT-XL model trained for 7M steps in less than 400K steps. In terms of final generation quality, our approach achieves state-of-the-art results of FID=1.42 using classifier-free guidance with the guidance interval.
Tree-D Fusion: Simulation-Ready Tree Dataset from Single Images with Diffusion Priors
Jul 14, 2024We introduce Tree D-fusion, featuring the first collection of 600,000 environmentally aware, 3D simulation-ready tree models generated through Diffusion priors. Each reconstructed 3D tree model corresponds to an image from Google's Auto Arborist Dataset, comprising street view images and associated genus labels of trees across North America. Our method distills the scores of two tree-adapted diffusion models by utilizing text prompts to specify a tree genus, thus facilitating shape reconstruction. This process involves reconstructing a 3D tree envelope filled with point markers, which are subsequently utilized to estimate the tree's branching structure using the space colonization algorithm conditioned on a specified genus.
Learning Hierarchical Semantic Classification by Grounding on Consistent Image Segmentations
Jun 17, 2024



Hierarchical semantic classification requires the prediction of a taxonomy tree instead of a single flat level of the tree, where both accuracies at individual levels and consistency across levels matter. We can train classifiers for individual levels, which has accuracy but not consistency, or we can train only the finest level classification and infer higher levels, which has consistency but not accuracy. Our key insight is that hierarchical recognition should not be treated as multi-task classification, as each level is essentially a different task and they would have to compromise with each other, but be grounded on image segmentations that are consistent across semantic granularities. Consistency can in fact improve accuracy. We build upon recent work on learning hierarchical segmentation for flat-level recognition, and extend it to hierarchical recognition. It naturally captures the intuition that fine-grained recognition requires fine image segmentation whereas coarse-grained recognition requires coarse segmentation; they can all be integrated into one recognition model that drives fine-to-coarse internal visual parsing.Additionally, we introduce a Tree-path KL Divergence loss to enforce consistent accurate predictions across levels. Our extensive experimentation and analysis demonstrate our significant gains on predicting an accurate and consistent taxonomy tree.
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dec 21, 2023



We present VideoPoet, a language model capable of synthesizing high-quality video, with matching audio, from a large variety of conditioning signals. VideoPoet employs a decoder-only transformer architecture that processes multimodal inputs -- including images, videos, text, and audio. The training protocol follows that of Large Language Models (LLMs), consisting of two stages: pretraining and task-specific adaptation. During pretraining, VideoPoet incorporates a mixture of multimodal generative objectives within an autoregressive Transformer framework. The pretrained LLM serves as a foundation that can be adapted for a range of video generation tasks. We present empirical results demonstrating the model's state-of-the-art capabilities in zero-shot video generation, specifically highlighting VideoPoet's ability to generate high-fidelity motions. Project page: http://sites.research.google/videopoet/
Text and Click inputs for unambiguous open vocabulary instance segmentation
Nov 24, 2023



Segmentation localizes objects in an image on a fine-grained per-pixel scale. Segmentation benefits by humans-in-the-loop to provide additional input of objects to segment using a combination of foreground or background clicks. Tasks include photoediting or novel dataset annotation, where human annotators leverage an existing segmentation model instead of drawing raw pixel level annotations. We propose a new segmentation process, Text + Click segmentation, where a model takes as input an image, a text phrase describing a class to segment, and a single foreground click specifying the instance to segment. Compared to previous approaches, we leverage open-vocabulary image-text models to support a wide-range of text prompts. Conditioning segmentations on text prompts improves the accuracy of segmentations on novel or unseen classes. We demonstrate that the combination of a single user-specified foreground click and a text prompt allows a model to better disambiguate overlapping or co-occurring semantic categories, such as "tie", "suit", and "person". We study these results across common segmentation datasets such as refCOCO, COCO, VOC, and OpenImages. Source code available here.
Optimizing ViViT Training: Time and Memory Reduction for Action Recognition
Jun 07, 2023



In this paper, we address the challenges posed by the substantial training time and memory consumption associated with video transformers, focusing on the ViViT (Video Vision Transformer) model, in particular the Factorised Encoder version, as our baseline for action recognition tasks. The factorised encoder variant follows the late-fusion approach that is adopted by many state of the art approaches. Despite standing out for its favorable speed/accuracy tradeoffs among the different variants of ViViT, its considerable training time and memory requirements still pose a significant barrier to entry. Our method is designed to lower this barrier and is based on the idea of freezing the spatial transformer during training. This leads to a low accuracy model if naively done. But we show that by (1) appropriately initializing the temporal transformer (a module responsible for processing temporal information) (2) introducing a compact adapter model connecting frozen spatial representations ((a module that selectively focuses on regions of the input image) to the temporal transformer, we can enjoy the benefits of freezing the spatial transformer without sacrificing accuracy. Through extensive experimentation over 6 benchmarks, we demonstrate that our proposed training strategy significantly reduces training costs (by $\sim 50\%$) and memory consumption while maintaining or slightly improving performance by up to 1.79\% compared to the baseline model. Our approach additionally unlocks the capability to utilize larger image transformer models as our spatial transformer and access more frames with the same memory consumption.
DaTaSeg: Taming a Universal Multi-Dataset Multi-Task Segmentation Model
Jun 02, 2023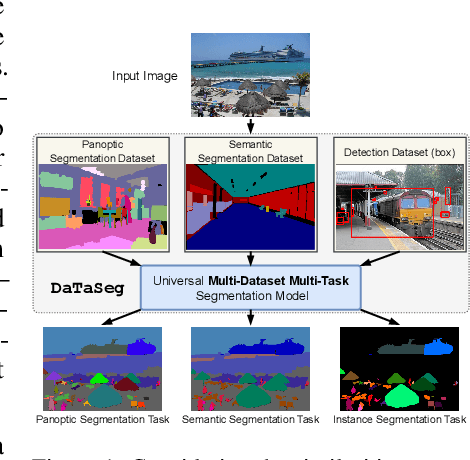
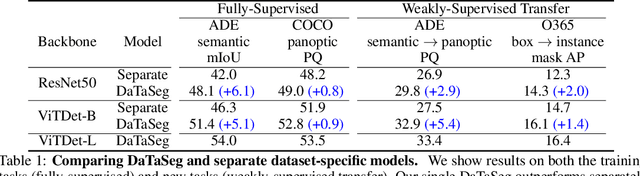
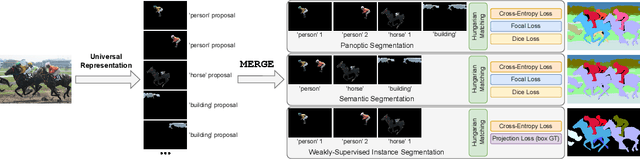
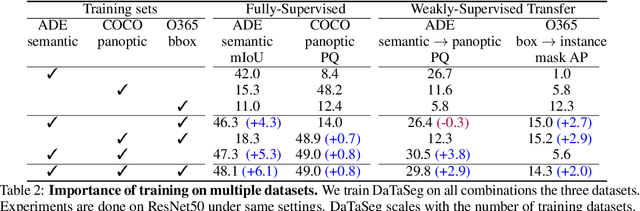
Observing the close relationship among panoptic, semantic and instance segmentation tasks, we propose to train a universal multi-dataset multi-task segmentation model: DaTaSeg.We use a shared representation (mask proposals with class predictions) for all tasks. To tackle task discrepancy, we adopt different merge operations and post-processing for different tasks. We also leverage weak-supervision, allowing our segmentation model to benefit from cheaper bounding box annotations. To share knowledge across datasets, we use text embeddings from the same semantic embedding space as classifiers and share all network parameters among datasets. We train DaTaSeg on ADE semantic, COCO panoptic, and Objects365 detection datasets. DaTaSeg improves performance on all datasets, especially small-scale datasets, achieving 54.0 mIoU on ADE semantic and 53.5 PQ on COCO panoptic. DaTaSeg also enables weakly-supervised knowledge transfer on ADE panoptic and Objects365 instance segmentation. Experiments show DaTaSeg scales with the number of training datasets and enables open-vocabulary segmentation through direct transfer. In addition, we annotate an Objects365 instance segmentation set of 1,000 images and will release it as a public benchmark.