 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring World Belief States in Dynamic Real-World Environments
Apr 13, 2026We investigate estimating a human's world belief state using a robot's observations in a dynamic, 3D, and partially observable environment. The methods are grounded in mental model theory, which posits that human decision making, contextual reasoning, situation awareness, and behavior planning draw from an internal simulation or world belief state. When in teams, the mental model also includes a team model of each teammate's beliefs and capabilities, enabling fluent teamwork without the need for constant and explicit communication. In this work we replicate a core component of the team model by inferring a teammate's belief state, or level one situation awareness, as a human-robot team navigates a household environment. We evaluate our methods in a realistic simulation, extend to a real-world robot platform, and demonstrate a downstream application of the belief state through an active assistance semantic reasoning task.
IPPO Learns the Game, Not the Team: A Study on Generalization in Heterogeneous Agent Teams
Dec 09, 2025

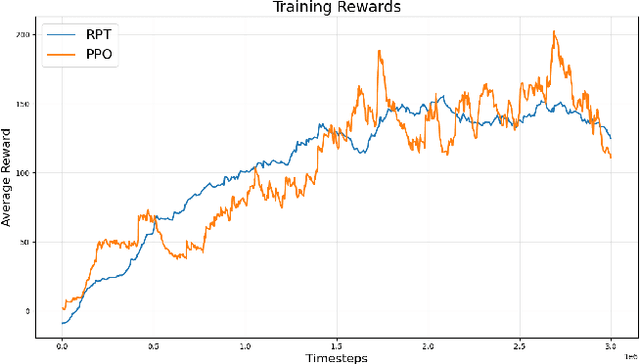

Multi-Agent Reinforcement Learning (MARL) is commonly deployed in settings where agents are trained via self-play with homogeneous teammates, often using parameter sharing and a single policy architecture. This opens the question: to what extent do self-play PPO agents learn general coordination strategies grounded in the underlying game, compared to overfitting to their training partners' behaviors? This paper investigates the question using the Heterogeneous Multi-Agent Challenge (HeMAC) environment, which features distinct Observer and Drone agents with complementary capabilities. We introduce Rotating Policy Training (RPT), an approach that rotates heterogeneous teammate policies of different learning algorithms during training, to expose the agent to a broader range of partner strategies. When playing alongside a withheld teammate policy (DDQN), we find that RPT achieves similar performance to a standard self-play baseline, IPPO, where all agents were trained sharing a single PPO policy. This result indicates that in this heterogeneous multi-agent setting, the IPPO baseline generalizes to novel teammate algorithms despite not experiencing teammate diversity during training. This shows that a simple IPPO baseline may possess the level of generalization to novel teammates that a diverse training regimen was designed to achieve.
Model Cards for AI Teammates: Comparing Human-AI Team Familiarization Methods for High-Stakes Environments
May 19, 2025We compare three methods of familiarizing a human with an artificial intelligence (AI) teammate ("agent") prior to operation in a collaborative, fast-paced intelligence, surveillance, and reconnaissance (ISR) environment. In a between-subjects user study (n=60), participants either read documentation about the agent, trained alongside the agent prior to the mission, or were given no familiarization. Results showed that the most valuable information about the agent included details of its decision-making algorithms and its relative strengths and weaknesses compared to the human. This information allowed the familiarization groups to form sophisticated team strategies more quickly than the control group. Documentation-based familiarization led to the fastest adoption of these strategies, but also biased participants towards risk-averse behavior that prevented high scores. Participants familiarized through direct interaction were able to infer much of the same information through observation, and were more willing to take risks and experiment with different control modes, but reported weaker understanding of the agent's internal processes. Significant differences were seen between individual participants' risk tolerance and methods of AI interaction, which should be considered when designing human-AI control interfaces. Based on our findings, we recommend a human-AI team familiarization method that combines AI documentation, structured in-situ training, and exploratory interaction.
Learning Complex Non-Rigid Image Edits from Multimodal Conditioning
Dec 13, 2024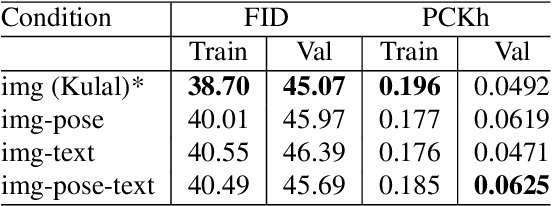


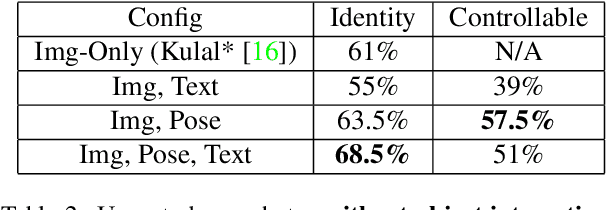
In this paper we focus on inserting a given human (specifically, a single image of a person) into a novel scene. Our method, which builds on top of Stable Diffusion, yields natural looking images while being highly controllable with text and pose. To accomplish this we need to train on pairs of images, the first a reference image with the person, the second a "target image" showing the same person (with a different pose and possibly in a different background). Additionally we require a text caption describing the new pose relative to that in the reference image. In this paper we present a novel dataset following this criteria, which we create using pairs of frames from human-centric and action-rich videos and employing a multimodal LLM to automatically summarize the difference in human pose for the text captions. We demonstrate that identity preservation is a more challenging task in scenes "in-the-wild", and especially scenes where there is an interaction between persons and objects. Combining the weak supervision from noisy captions, with robust 2D pose improves the quality of person-object interactions.
Inferring Belief States in Partially-Observable Human-Robot Teams
Mar 18, 2024



We investigate the real-time estimation of human situation awareness using observations from a robot teammate with limited visibility. In human factors and human-autonomy teaming, it is recognized that individuals navigate their environments using an internal mental simulation, or mental model. The mental model informs cognitive processes including situation awareness, contextual reasoning, and task planning. In teaming domains, the mental model includes a team model of each teammate's beliefs and capabilities, enabling fluent teamwork without the need for explicit communication. However, little work has applied team models to human-robot teaming. We compare the performance of two current methods at estimating user situation awareness over varying visibility conditions. Our results indicate that the methods are largely resilient to low-visibility conditions in our domain, however opportunities exist to improve their overall performance.
The Effects of Robot Motion on Comfort Dynamics of Novice Users in Close-Proximity Human-Robot Interaction
Aug 02, 2023Effective and fluent close-proximity human-robot interaction requires understanding how humans get habituated to robots and how robot motion affects human comfort. While prior work has identified humans' preferences over robot motion characteristics and studied their influence on comfort, we are yet to understand how novice first-time robot users get habituated to robots and how robot motion impacts the dynamics of comfort over repeated interactions. To take the first step towards such understanding, we carry out a user study to investigate the connections between robot motion and user comfort and habituation. Specifically, we study the influence of workspace overlap, end-effector speed, and robot motion legibility on overall comfort and its evolution over repeated interactions. Our analyses reveal that workspace overlap, in contrast to speed and legibility, has a significant impact on users' perceived comfort and habituation. In particular, lower workspace overlap leads to users reporting significantly higher overall comfort, lower variations in comfort, and fewer fluctuations in comfort levels during habituation.
Constrained Reinforcement Learning for Dexterous Manipulation
Jan 24, 2023Existing learning approaches to dexterous manipulation use demonstrations or interactions with the environment to train black-box neural networks that provide little control over how the robot learns the skills or how it would perform post training. These approaches pose significant challenges when implemented on physical platforms given that, during initial stages of training, the robot's behavior could be erratic and potentially harmful to its own hardware, the environment, or any humans in the vicinity. A potential way to address these limitations is to add constraints during learning that restrict and guide the robot's behavior during training as well as roll outs. Inspired by the success of constrained approaches in other domains, we investigate the effects of adding position-based constraints to a 24-DOF robot hand learning to perform object relocation using Constrained Policy Optimization. We find that a simple geometric constraint can ensure the robot learns to move towards the object sooner than without constraints. Further, training with this constraint requires a similar number of samples as its unconstrained counterpart to master the skill. These findings shed light on how simple constraints can help robots achieve sensible and safe behavior quickly and ease concerns surrounding hardware deployment. We also investigate the effects of the strictness of these constraints and report findings that provide insights into how different degrees of strictness affect learning outcomes. Our code is available at https://github.com/GT-STAR-Lab/constrained-rl-dexterous-manipulation.
Evaluating the Effectiveness of Corrective Demonstrations and a Low-Cost Sensor for Dexterous Manipulation
Apr 15, 2022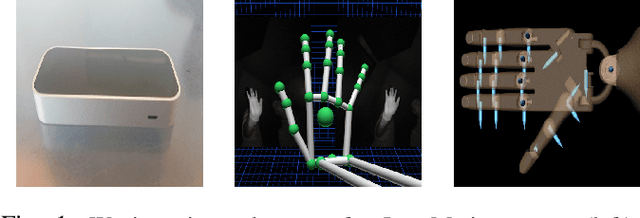


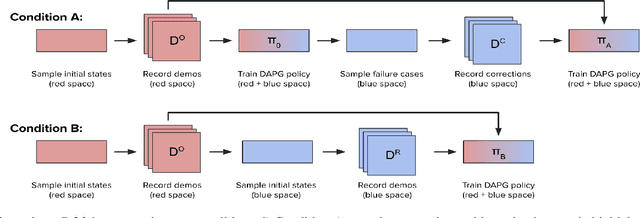
Imitation learning is a promising approach to help robots acquire dexterous manipulation capabilities without the need for a carefully-designed reward or a significant computational effort. However, existing imitation learning approaches require sophisticated data collection infrastructure and struggle to generalize beyond the training distribution. One way to address this limitation is to gather additional data that better represents the full operating conditions. In this work, we investigate characteristics of such additional demonstrations and their impact on performance. Specifically, we study the effects of corrective and randomly-sampled additional demonstrations on learning a policy that guides a five-fingered robot hand through a pick-and-place task. Our results suggest that corrective demonstrations considerably outperform randomly-sampled demonstrations, when the proportion of additional demonstrations sampled from the full task distribution is larger than the number of original demonstrations sampled from a restrictive training distribution. Conversely, when the number of original demonstrations are higher than that of additional demonstrations, we find no significant differences between corrective and randomly-sampled additional demonstrations. These results provide insights into the inherent trade-off between the effort required to collect corrective demonstrations and their relative benefits over randomly-sampled demonstrations. Additionally, we show that inexpensive vision-based sensors, such as LeapMotion, can be used to dramatically reduce the cost of providing demonstrations for dexterous manipulation tasks. Our code is available at https://github.com/GT-STAR-Lab/corrective-demos-dexterous-manipulation.