 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring World Belief States in Dynamic Real-World Environments
Apr 13, 2026We investigate estimating a human's world belief state using a robot's observations in a dynamic, 3D, and partially observable environment. The methods are grounded in mental model theory, which posits that human decision making, contextual reasoning, situation awareness, and behavior planning draw from an internal simulation or world belief state. When in teams, the mental model also includes a team model of each teammate's beliefs and capabilities, enabling fluent teamwork without the need for constant and explicit communication. In this work we replicate a core component of the team model by inferring a teammate's belief state, or level one situation awareness, as a human-robot team navigates a household environment. We evaluate our methods in a realistic simulation, extend to a real-world robot platform, and demonstrate a downstream application of the belief state through an active assistance semantic reasoning task.
MoCHA: Denoising Caption Supervision for Motion-Text Retrieval
Mar 24, 2026Text-motion retrieval systems learn shared embedding spaces from motion-caption pairs via contrastive objectives. However, each caption is not a deterministic label but a sample from a distribution of valid descriptions: different annotators produce different text for the same motion, mixing motion-recoverable semantics (action type, body parts, directionality) with annotator-specific style and inferred context that cannot be determined from 3D joint coordinates alone. Standard contrastive training treats each caption as the single positive target, overlooking this distributional structure and inducing within-motion embedding variance that weakens alignment. We propose MoCHA, a text canonicalization framework that reduces this variance by projecting each caption onto its motion-recoverable content prior to encoding, producing tighter positive clusters and better-separated embeddings. Canonicalization is a general principle: even deterministic rule-based methods improve cross-dataset transfer, though learned canonicalizers provide substantially larger gains. We present two learned variants: an LLM-based approach (GPT-5.2) and a distilled FlanT5 model requiring no LLM at inference time. MoCHA operates as a preprocessing step compatible with any retrieval architecture. Applied to MoPa (MotionPatches), MoCHA sets a new state of the art on both HumanML3D (H) and KIT-ML (K): the LLM variant achieves 13.9% T2M R@1 on H (+3.1pp) and 24.3% on K (+10.3pp), while the LLM-free T5 variant achieves gains of +2.5pp and +8.1pp. Canonicalization reduces within-motion text-embedding variance by 11-19% and improves cross-dataset transfer substantially, with H to K improving by 94% and K to H by 52%, demonstrating that standardizing the language space yields more transferable motion-language representations.
AugLift: Boosting Generalization in Lifting-based 3D Human Pose Estimation
Aug 09, 2025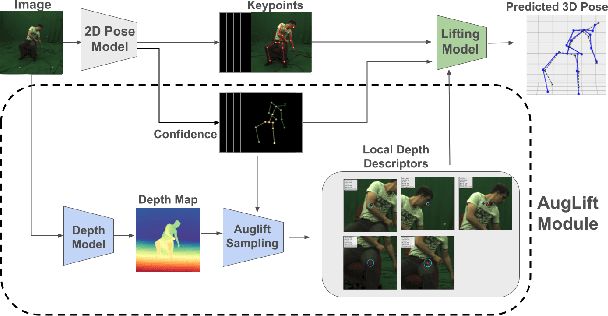
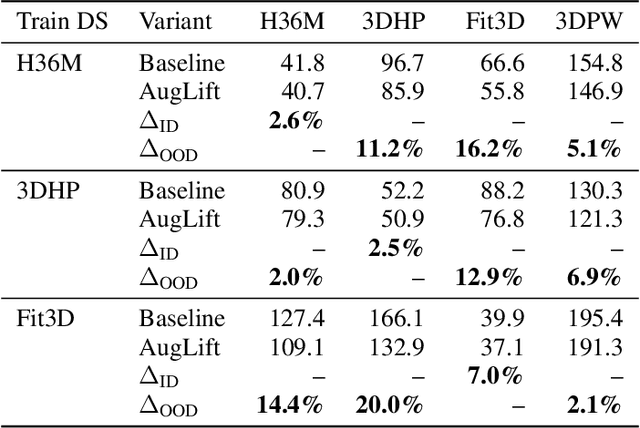
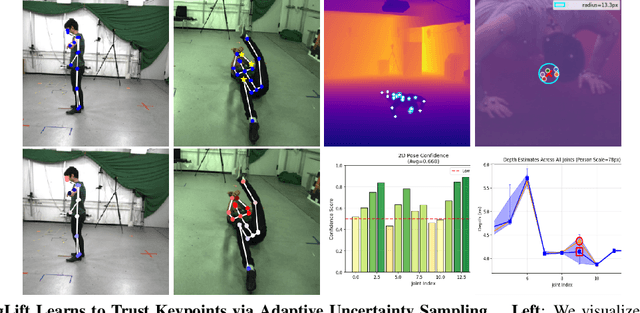
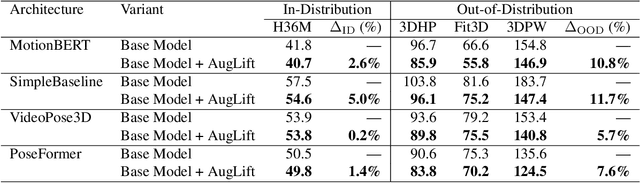
Lifting-based methods for 3D Human Pose Estimation (HPE), which predict 3D poses from detected 2D keypoints, often generalize poorly to new datasets and real-world settings. To address this, we propose \emph{AugLift}, a simple yet effective reformulation of the standard lifting pipeline that significantly improves generalization performance without requiring additional data collection or sensors. AugLift sparsely enriches the standard input -- the 2D keypoint coordinates $(x, y)$ -- by augmenting it with a keypoint detection confidence score $c$ and a corresponding depth estimate $d$. These additional signals are computed from the image using off-the-shelf, pre-trained models (e.g., for monocular depth estimation), thereby inheriting their strong generalization capabilities. Importantly, AugLift serves as a modular add-on and can be readily integrated into existing lifting architectures. Our extensive experiments across four datasets demonstrate that AugLift boosts cross-dataset performance on unseen datasets by an average of $10.1\%$, while also improving in-distribution performance by $4.0\%$. These gains are consistent across various lifting architectures, highlighting the robustness of our method. Our analysis suggests that these sparse, keypoint-aligned cues provide robust frame-level context, offering a practical way to significantly improve the generalization of any lifting-based pose estimation model. Code will be made publicly available.
Learning Complex Non-Rigid Image Edits from Multimodal Conditioning
Dec 13, 2024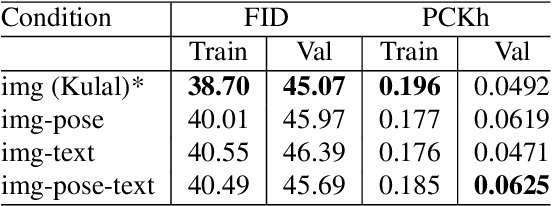


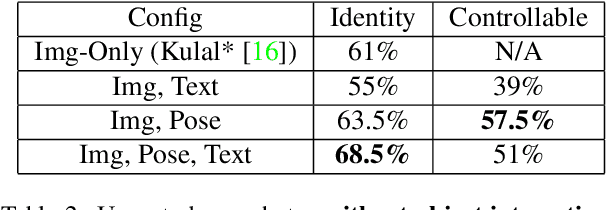
In this paper we focus on inserting a given human (specifically, a single image of a person) into a novel scene. Our method, which builds on top of Stable Diffusion, yields natural looking images while being highly controllable with text and pose. To accomplish this we need to train on pairs of images, the first a reference image with the person, the second a "target image" showing the same person (with a different pose and possibly in a different background). Additionally we require a text caption describing the new pose relative to that in the reference image. In this paper we present a novel dataset following this criteria, which we create using pairs of frames from human-centric and action-rich videos and employing a multimodal LLM to automatically summarize the difference in human pose for the text captions. We demonstrate that identity preservation is a more challenging task in scenes "in-the-wild", and especially scenes where there is an interaction between persons and objects. Combining the weak supervision from noisy captions, with robust 2D pose improves the quality of person-object interactions.
Text and Click inputs for unambiguous open vocabulary instance segmentation
Nov 24, 2023



Segmentation localizes objects in an image on a fine-grained per-pixel scale. Segmentation benefits by humans-in-the-loop to provide additional input of objects to segment using a combination of foreground or background clicks. Tasks include photoediting or novel dataset annotation, where human annotators leverage an existing segmentation model instead of drawing raw pixel level annotations. We propose a new segmentation process, Text + Click segmentation, where a model takes as input an image, a text phrase describing a class to segment, and a single foreground click specifying the instance to segment. Compared to previous approaches, we leverage open-vocabulary image-text models to support a wide-range of text prompts. Conditioning segmentations on text prompts improves the accuracy of segmentations on novel or unseen classes. We demonstrate that the combination of a single user-specified foreground click and a text prompt allows a model to better disambiguate overlapping or co-occurring semantic categories, such as "tie", "suit", and "person". We study these results across common segmentation datasets such as refCOCO, COCO, VOC, and OpenImages. Source code available here.