 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugLift: Boosting Generalization in Lifting-based 3D Human Pose Estimation
Aug 09, 2025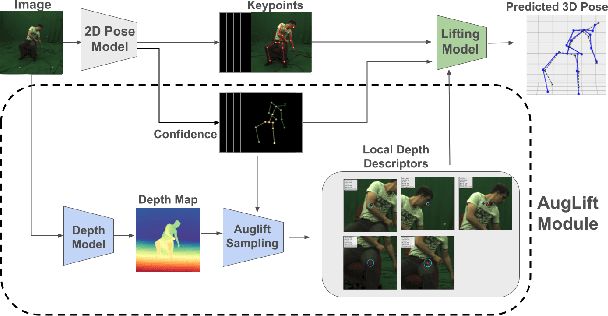
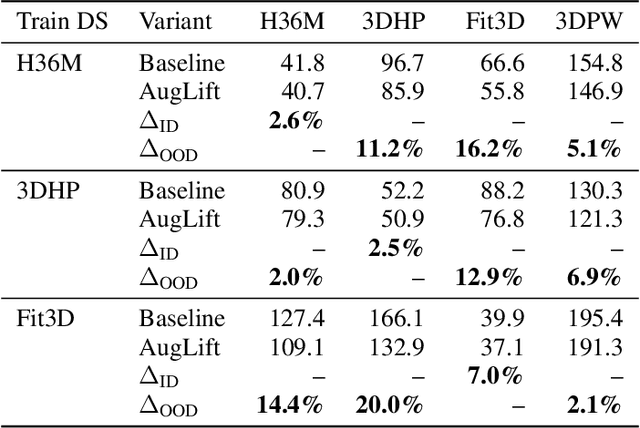
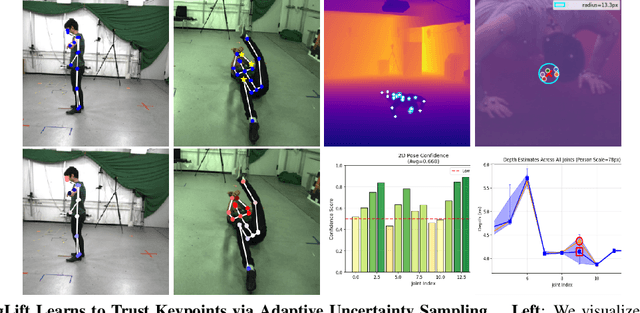
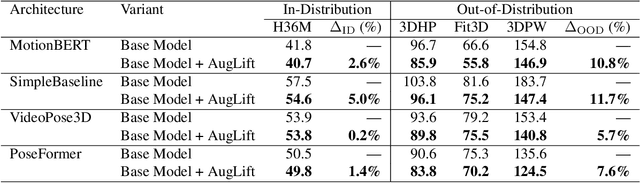
Lifting-based methods for 3D Human Pose Estimation (HPE), which predict 3D poses from detected 2D keypoints, often generalize poorly to new datasets and real-world settings. To address this, we propose \emph{AugLift}, a simple yet effective reformulation of the standard lifting pipeline that significantly improves generalization performance without requiring additional data collection or sensors. AugLift sparsely enriches the standard input -- the 2D keypoint coordinates $(x, y)$ -- by augmenting it with a keypoint detection confidence score $c$ and a corresponding depth estimate $d$. These additional signals are computed from the image using off-the-shelf, pre-trained models (e.g., for monocular depth estimation), thereby inheriting their strong generalization capabilities. Importantly, AugLift serves as a modular add-on and can be readily integrated into existing lifting architectures. Our extensive experiments across four datasets demonstrate that AugLift boosts cross-dataset performance on unseen datasets by an average of $10.1\%$, while also improving in-distribution performance by $4.0\%$. These gains are consistent across various lifting architectures, highlighting the robustness of our method. Our analysis suggests that these sparse, keypoint-aligned cues provide robust frame-level context, offering a practical way to significantly improve the generalization of any lifting-based pose estimation model. Code will be made publicly available.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
MaskMatch: Boosting Semi-Supervised Learning Through Mask Autoencoder-Driven Feature Learning
May 10, 2024



Conventional methods in semi-supervised learning (SSL) often face challenges related to limited data utilization, mainly due to their reliance on threshold-based techniques for selecting high-confidence unlabeled data during training. Various efforts (e.g., FreeMatch) have been made to enhance data utilization by tweaking the thresholds, yet none have managed to use 100% of the available data. To overcome this limitation and improve SSL performance, we introduce \algo, a novel algorithm that fully utilizes unlabeled data to boost semi-supervised learning. \algo integrates a self-supervised learning strategy, i.e., Masked Autoencoder (MAE), that uses all available data to enforce the visual representation learning. This enables the SSL algorithm to leverage all available data, including samples typically filtered out by traditional methods. In addition, we propose a synthetic data training approach to further increase data utilization and improve generalization. These innovations lead \algo to achieve state-of-the-art results on challenging datasets. For instance, on CIFAR-100 with 2 labels per class, STL-10 with 4 labels per class, and Euro-SAT with 2 labels per class, \algo achieves low error rates of 18.71%, 9.47%, and 3.07%, respectively. The code will be made publicly available.