 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCHA: Denoising Caption Supervision for Motion-Text Retrieval
Mar 24, 2026Text-motion retrieval systems learn shared embedding spaces from motion-caption pairs via contrastive objectives. However, each caption is not a deterministic label but a sample from a distribution of valid descriptions: different annotators produce different text for the same motion, mixing motion-recoverable semantics (action type, body parts, directionality) with annotator-specific style and inferred context that cannot be determined from 3D joint coordinates alone. Standard contrastive training treats each caption as the single positive target, overlooking this distributional structure and inducing within-motion embedding variance that weakens alignment. We propose MoCHA, a text canonicalization framework that reduces this variance by projecting each caption onto its motion-recoverable content prior to encoding, producing tighter positive clusters and better-separated embeddings. Canonicalization is a general principle: even deterministic rule-based methods improve cross-dataset transfer, though learned canonicalizers provide substantially larger gains. We present two learned variants: an LLM-based approach (GPT-5.2) and a distilled FlanT5 model requiring no LLM at inference time. MoCHA operates as a preprocessing step compatible with any retrieval architecture. Applied to MoPa (MotionPatches), MoCHA sets a new state of the art on both HumanML3D (H) and KIT-ML (K): the LLM variant achieves 13.9% T2M R@1 on H (+3.1pp) and 24.3% on K (+10.3pp), while the LLM-free T5 variant achieves gains of +2.5pp and +8.1pp. Canonicalization reduces within-motion text-embedding variance by 11-19% and improves cross-dataset transfer substantially, with H to K improving by 94% and K to H by 52%, demonstrating that standardizing the language space yields more transferable motion-language representations.
AugLift: Boosting Generalization in Lifting-based 3D Human Pose Estimation
Aug 09, 2025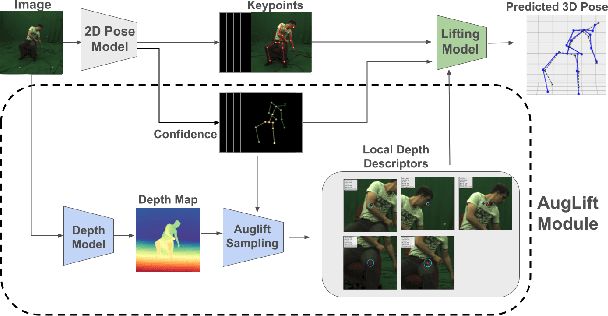
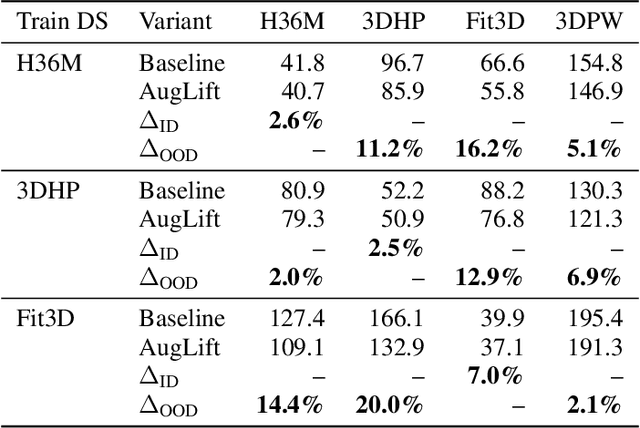
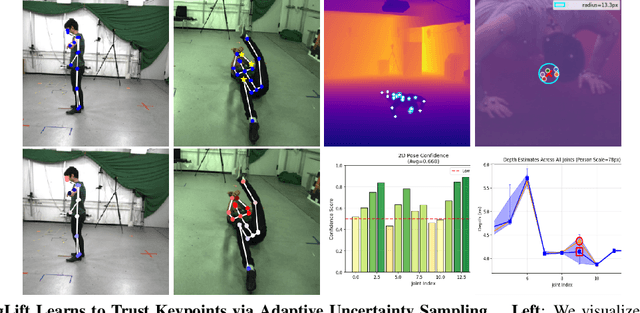
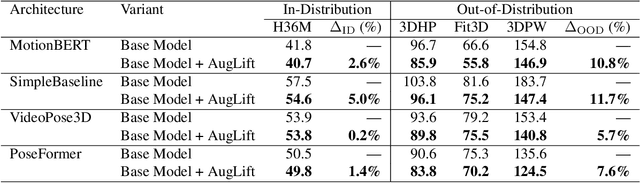
Lifting-based methods for 3D Human Pose Estimation (HPE), which predict 3D poses from detected 2D keypoints, often generalize poorly to new datasets and real-world settings. To address this, we propose \emph{AugLift}, a simple yet effective reformulation of the standard lifting pipeline that significantly improves generalization performance without requiring additional data collection or sensors. AugLift sparsely enriches the standard input -- the 2D keypoint coordinates $(x, y)$ -- by augmenting it with a keypoint detection confidence score $c$ and a corresponding depth estimate $d$. These additional signals are computed from the image using off-the-shelf, pre-trained models (e.g., for monocular depth estimation), thereby inheriting their strong generalization capabilities. Importantly, AugLift serves as a modular add-on and can be readily integrated into existing lifting architectures. Our extensive experiments across four datasets demonstrate that AugLift boosts cross-dataset performance on unseen datasets by an average of $10.1\%$, while also improving in-distribution performance by $4.0\%$. These gains are consistent across various lifting architectures, highlighting the robustness of our method. Our analysis suggests that these sparse, keypoint-aligned cues provide robust frame-level context, offering a practical way to significantly improve the generalization of any lifting-based pose estimation model. Code will be made publicly available.
HierSum: A Global and Local Attention Mechanism for Video Summarization
Apr 25, 2025
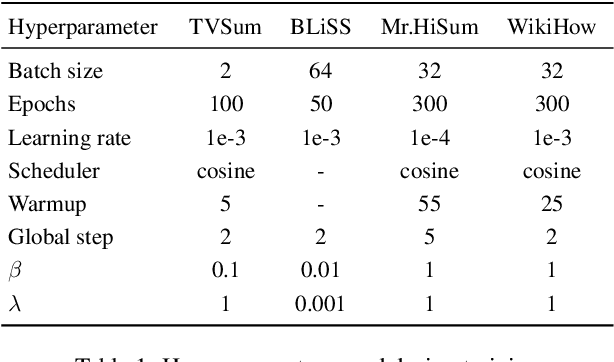
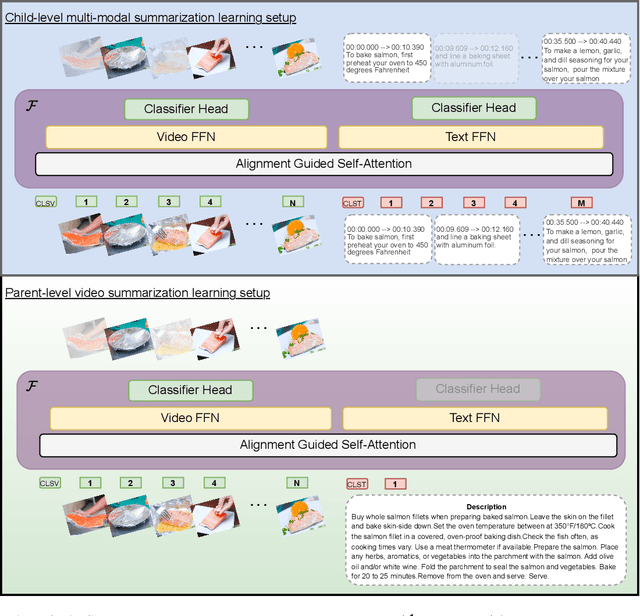
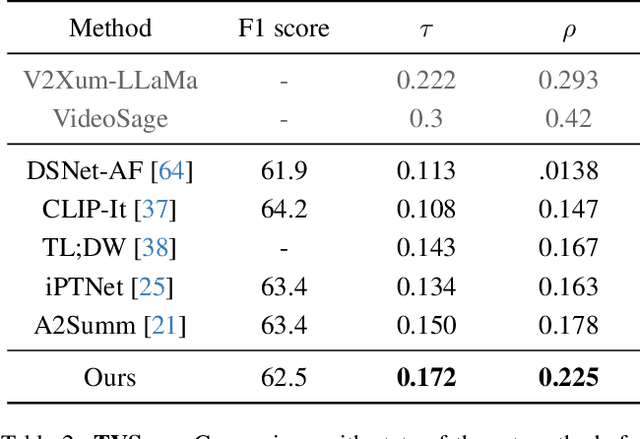
Video summarization creates an abridged version (i.e., a summary) that provides a quick overview of the video while retaining pertinent information. In this work, we focus on summarizing instructional videos and propose a method for breaking down a video into meaningful segments, each corresponding to essential steps in the video. We propose \textbf{HierSum}, a hierarchical approach that integrates fine-grained local cues from subtitles with global contextual information provided by video-level instructions. Our approach utilizes the ``most replayed" statistic as a supervisory signal to identify critical segments, thereby improving the effectiveness of the summary. We evaluate on benchmark datasets such as TVSum, BLiSS, Mr.HiSum, and the WikiHow test set, and show that HierSum consistently outperforms existing methods in key metrics such as F1-score and rank correlation. We also curate a new multi-modal dataset using WikiHow and EHow videos and associated articles containing step-by-step instructions. Through extensive ablation studies, we demonstrate that training on this dataset significantly enhances summarization on the target datasets.
Leveraging Procedural Knowledge and Task Hierarchies for Efficient Instructional Video Pre-training
Feb 24, 2025Instructional videos provide a convenient modality to learn new tasks (ex. cooking a recipe, or assembling furniture). A viewer will want to find a corresponding video that reflects both the overall task they are interested in as well as contains the relevant steps they need to carry out the task. To perform this, an instructional video model should be capable of inferring both the tasks and the steps that occur in an input video. Doing this efficiently and in a generalizable fashion is key when compute or relevant video topics used to train this model are limited. To address these requirements we explicitly mine task hierarchies and the procedural steps associated with instructional videos. We use this prior knowledge to pre-train our model, $\texttt{Pivot}$, for step and task prediction. During pre-training, we also provide video augmentation and early stopping strategies to optimally identify which model to use for downstream tasks. We test this pre-trained model on task recognition, step recognition, and step prediction tasks on two downstream datasets. When pre-training data and compute are limited, we outperform previous baselines along these tasks. Therefore, leveraging prior task and step structures enables efficient training of $\texttt{Pivot}$ for instructional video recommendation.
MALT Diffusion: Memory-Augmented Latent Transformers for Any-Length Video Generation
Feb 18, 2025Diffusion models are successful for synthesizing high-quality videos but are limited to generating short clips (e.g., 2-10 seconds). Synthesizing sustained footage (e.g. over minutes) still remains an open research question. In this paper, we propose MALT Diffusion (using Memory-Augmented Latent Transformers), a new diffusion model specialized for long video generation. MALT Diffusion (or just MALT) handles long videos by subdividing them into short segments and doing segment-level autoregressive generation. To achieve this, we first propose recurrent attention layers that encode multiple segments into a compact memory latent vector; by maintaining this memory vector over time, MALT is able to condition on it and continuously generate new footage based on a long temporal context. We also present several training techniques that enable the model to generate frames over a long horizon with consistent quality and minimal degradation. We validate the effectiveness of MALT through experiments on long video benchmarks. We first perform extensive analysis of MALT in long-contextual understanding capability and stability using popular long video benchmarks. For example, MALT achieves an FVD score of 220.4 on 128-frame video generation on UCF-101, outperforming the previous state-of-the-art of 648.4. Finally, we explore MALT's capabilities in a text-to-video generation setting and show that it can produce long videos compared with recent techniques for long text-to-video generation.
Calibrated Multi-Preference Optimization for Aligning Diffusion Models
Feb 04, 2025



Aligning text-to-image (T2I) diffusion models with preference optimization is valuable for human-annotated datasets, but the heavy cost of manual data collection limits scalability. Using reward models offers an alternative, however, current preference optimization methods fall short in exploiting the rich information, as they only consider pairwise preference distribution. Furthermore, they lack generalization to multi-preference scenarios and struggle to handle inconsistencies between rewards. To address this, we present Calibrated Preference Optimization (CaPO), a novel method to align T2I diffusion models by incorporating the general preference from multiple reward models without human annotated data. The core of our approach involves a reward calibration method to approximate the general preference by computing the expected win-rate against the samples generated by the pretrained models. Additionally, we propose a frontier-based pair selection method that effectively manages the multi-preference distribution by selecting pairs from Pareto frontiers. Finally, we use regression loss to fine-tune diffusion models to match the difference between calibrated rewards of a selected pair. Experimental results show that CaPO consistently outperforms prior methods, such as Direct Preference Optimization (DPO), in both single and multi-reward settings validated by evaluation on T2I benchmarks, including GenEval and T2I-Compbench.
Learning Complex Non-Rigid Image Edits from Multimodal Conditioning
Dec 13, 2024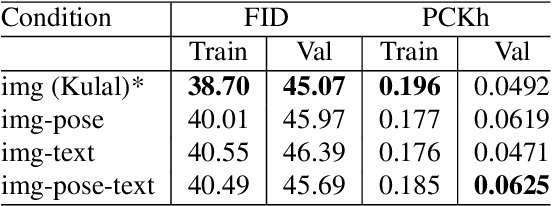


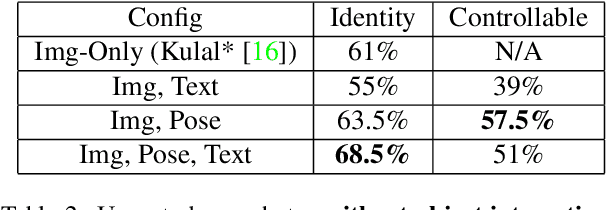
In this paper we focus on inserting a given human (specifically, a single image of a person) into a novel scene. Our method, which builds on top of Stable Diffusion, yields natural looking images while being highly controllable with text and pose. To accomplish this we need to train on pairs of images, the first a reference image with the person, the second a "target image" showing the same person (with a different pose and possibly in a different background). Additionally we require a text caption describing the new pose relative to that in the reference image. In this paper we present a novel dataset following this criteria, which we create using pairs of frames from human-centric and action-rich videos and employing a multimodal LLM to automatically summarize the difference in human pose for the text captions. We demonstrate that identity preservation is a more challenging task in scenes "in-the-wild", and especially scenes where there is an interaction between persons and objects. Combining the weak supervision from noisy captions, with robust 2D pose improves the quality of person-object interactions.
AfriMed-QA: A Pan-African, Multi-Specialty, Medical Question-Answering Benchmark Dataset
Nov 23, 2024

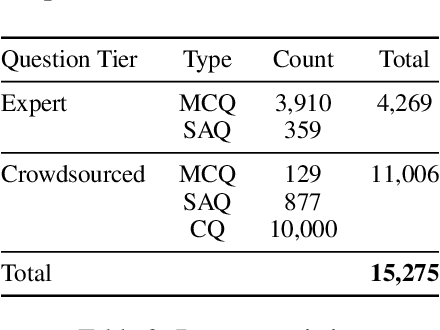

Recent advancements in large language model(LLM) performance on medical multiple choice question (MCQ) benchmarks have stimulated interest from healthcare providers and patients globally. Particularly in low-and middle-income countries (LMICs) facing acute physician shortages and lack of specialists, LLMs offer a potentially scalable pathway to enhance healthcare access and reduce costs. However, their effectiveness in the Global South, especially across the African continent, remains to be established. In this work, we introduce AfriMed-QA, the first large scale Pan-African English multi-specialty medical Question-Answering (QA) dataset, 15,000 questions (open and closed-ended) sourced from over 60 medical schools across 16 countries, covering 32 medical specialties. We further evaluate 30 LLMs across multiple axes including correctness and demographic bias. Our findings show significant performance variation across specialties and geographies, MCQ performance clearly lags USMLE (MedQA). We find that biomedical LLMs underperform general models and smaller edge-friendly LLMs struggle to achieve a passing score. Interestingly, human evaluations show a consistent consumer preference for LLM answers and explanations when compared with clinician answers.
Exploring Efficient Foundational Multi-modal Models for Video Summarization
Oct 09, 2024Foundational models are able to generate text outputs given prompt instructions and text, audio, or image inputs. Recently these models have been combined to perform tasks on video, such as video summarization. Such video foundation models perform pre-training by aligning outputs from each modality-specific model into the same embedding space. Then the embeddings from each model are used within a language model, which is fine-tuned on a desired instruction set. Aligning each modality during pre-training is computationally expensive and prevents rapid testing of different base modality models. During fine-tuning, evaluation is carried out within in-domain videos where it is hard to understand the generalizability and data efficiency of these methods. To alleviate these issues we propose a plug-and-play video language model. It directly uses the texts generated from each input modality into the language model, avoiding pre-training alignment overhead. Instead of fine-tuning we leverage few-shot instruction adaptation strategies. We compare the performance versus the computational costs for our plug-and-play style method and baseline tuning methods. Finally, we explore the generalizability of each method during domain shift and present insights on what data is useful when training data is limited. Through this analysis, we present practical insights on how to leverage multi-modal foundational models for effective results given realistic compute and data limitations.
Mamba Fusion: Learning Actions Through Questioning
Sep 17, 2024



Video Language Models (VLMs) are crucial for generalizing across diverse tasks and using language cues to enhance learning. While transformer-based architectures have been the de facto in vision-language training, they face challenges like quadratic computational complexity, high GPU memory usage, and difficulty with long-term dependencies. To address these limitations, we introduce MambaVL, a novel model that leverages recent advancements in selective state space modality fusion to efficiently capture long-range dependencies and learn joint representations for vision and language data. MambaVL utilizes a shared state transition matrix across both modalities, allowing the model to capture information about actions from multiple perspectives within the scene. Furthermore, we propose a question-answering task that helps guide the model toward relevant cues. These questions provide critical information about actions, objects, and environmental context, leading to enhanced performance. As a result, MambaVL achieves state-of-the-art performance in action recognition on the Epic-Kitchens-100 dataset and outperforms baseline methods in action anticipation.