 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCropper: Vision-Language Model for Image Cropping through In-Context Learning
Aug 14, 2024



The goal of image cropping is to identify visually appealing crops within an image. Conventional methods rely on specialized architectures trained on specific datasets, which struggle to be adapted to new requirements. Recent breakthroughs in large vision-language models (VLMs) have enabled visual in-context learning without explicit training. However, effective strategies for vision downstream tasks with VLMs remain largely unclear and underexplored. In this paper, we propose an effective approach to leverage VLMs for better image cropping. First, we propose an efficient prompt retrieval mechanism for image cropping to automate the selection of in-context examples. Second, we introduce an iterative refinement strategy to iteratively enhance the predicted crops. The proposed framework, named Cropper, is applicable to a wide range of cropping tasks, including free-form cropping, subject-aware cropping, and aspect ratio-aware cropping. Extensive experiments and a user study demonstrate that Cropper significantly outperforms state-of-the-art methods across several benchmarks.
Floors are Flat: Leveraging Semantics for Real-Time Surface Normal Prediction
Jun 16, 2019
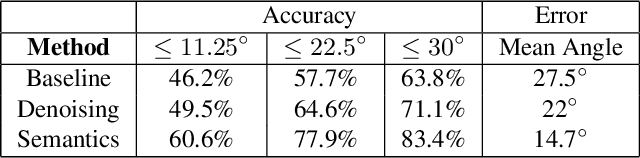

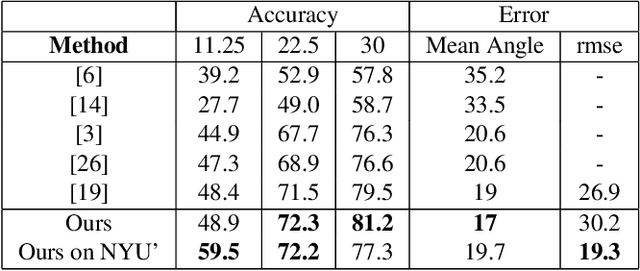
We propose 4 insights that help to significantly improve the performance of deep learning models that predict surface normals and semantic labels from a single RGB image. These insights are: (1) denoise the "ground truth" surface normals in the training set to ensure consistency with the semantic labels; (2) concurrently train on a mix of real and synthetic data, instead of pretraining on synthetic and finetuning on real; (3) jointly predict normals and semantics using a shared model, but only backpropagate errors on pixels that have valid training labels; (4) slim down the model and use grayscale instead of color inputs. Despite the simplicity of these steps, we demonstrate consistently improved results on several datasets, using a model that runs at 12 fps on a standard mobile phone.
Object category learning and retrieval with weak supervision
Jul 23, 2018

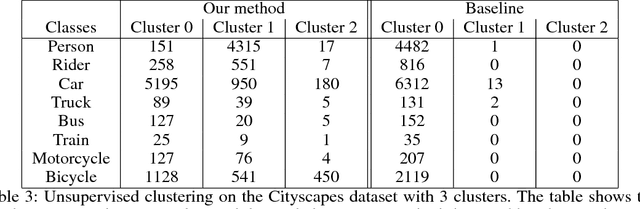
We consider the problem of retrieving objects from image data and learning to classify them into meaningful semantic categories with minimal supervision. To that end, we propose a fully differentiable unsupervised deep clustering approach to learn semantic classes in an end-to-end fashion without individual class labeling using only unlabeled object proposals. The key contributions of our work are 1) a kmeans clustering objective where the clusters are learned as parameters of the network and are represented as memory units, and 2) simultaneously building a feature representation, or embedding, while learning to cluster it. This approach shows promising results on two popular computer vision datasets: on CIFAR10 for clustering objects, and on the more complex and challenging Cityscapes dataset for semantically discovering classes which visually correspond to cars, people, and bicycles. Currently, the only supervision provided is segmentation objectness masks, but this method can be extended to use an unsupervised objectness-based object generation mechanism which will make the approach completely unsupervised.
Efficient Hierarchical Graph-Based Segmentation of RGBD Videos
Jan 26, 2018
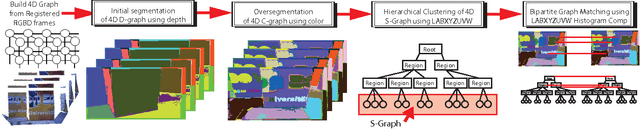

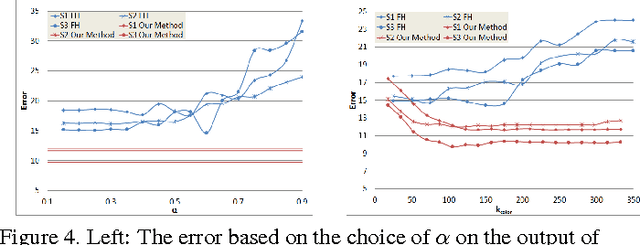
We present an efficient and scalable algorithm for segmenting 3D RGBD point clouds by combining depth, color, and temporal information using a multistage, hierarchical graph-based approach. Our algorithm processes a moving window over several point clouds to group similar regions over a graph, resulting in an initial over-segmentation. These regions are then merged to yield a dendrogram using agglomerative clustering via a minimum spanning tree algorithm. Bipartite graph matching at a given level of the hierarchical tree yields the final segmentation of the point clouds by maintaining region identities over arbitrarily long periods of time. We show that a multistage segmentation with depth then color yields better results than a linear combination of depth and color. Due to its incremental processing, our algorithm can process videos of any length and in a streaming pipeline. The algorithm's ability to produce robust, efficient segmentation is demonstrated with numerous experimental results on challenging sequences from our own as well as public RGBD data sets.
Let's Dance: Learning From Online Dance Videos
Jan 23, 2018
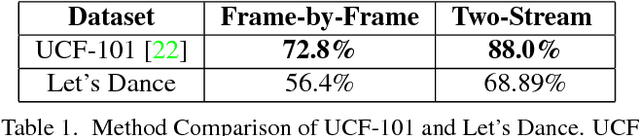

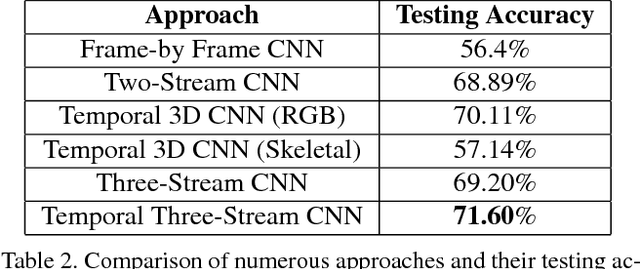
In recent years, deep neural network approaches have naturally extended to the video domain, in their simplest case by aggregating per-frame classifications as a baseline for action recognition. A majority of the work in this area extends from the imaging domain, leading to visual-feature heavy approaches on temporal data. To address this issue we introduce "Let's Dance", a 1000 video dataset (and growing) comprised of 10 visually overlapping dance categories that require motion for their classification. We stress the important of human motion as a key distinguisher in our work given that, as we show in this work, visual information is not sufficient to classify motion-heavy categories. We compare our datasets' performance using imaging techniques with UCF-101 and demonstrate this inherent difficulty. We present a comparison of numerous state-of-the-art techniques on our dataset using three different representations (video, optical flow and multi-person pose data) in order to analyze these approaches. We discuss the motion parameterization of each of them and their value in learning to categorize online dance videos. Lastly, we release this dataset (and its three representations) for the research community to use.
Semantic Instance Labeling Leveraging Hierarchical Segmentation
Aug 02, 2017
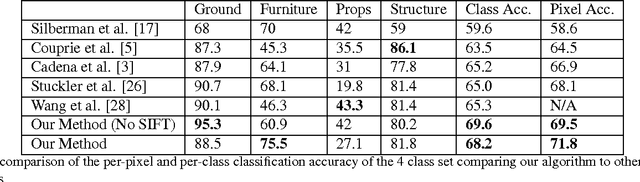
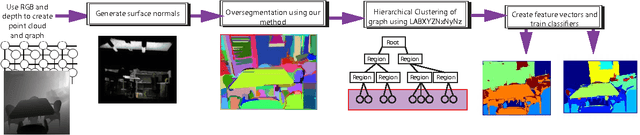
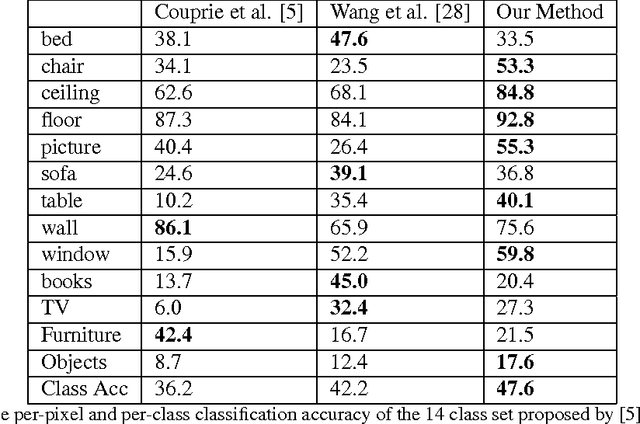
Most of the approaches for indoor RGBD semantic la- beling focus on using pixels or superpixels to train a classi- fier. In this paper, we implement a higher level segmentation using a hierarchy of superpixels to obtain a better segmen- tation for training our classifier. By focusing on meaningful segments that conform more directly to objects, regardless of size, we train a random forest of decision trees as a clas- sifier using simple features such as the 3D size, LAB color histogram, width, height, and shape as specified by a his- togram of surface normals. We test our method on the NYU V2 depth dataset, a challenging dataset of cluttered indoor environments. Our experiments using the NYU V2 depth dataset show that our method achieves state of the art re- sults on both a general semantic labeling introduced by the dataset (floor, structure, furniture, and objects) and a more object specific semantic labeling. We show that training a classifier on a segmentation from a hierarchy of super pixels yields better results than training directly on super pixels, patches, or pixels as in previous work.
An Energy Minimization Approach to 3D Non-Rigid Deformable Surface Estimation Using RGBD Data
Aug 02, 2017
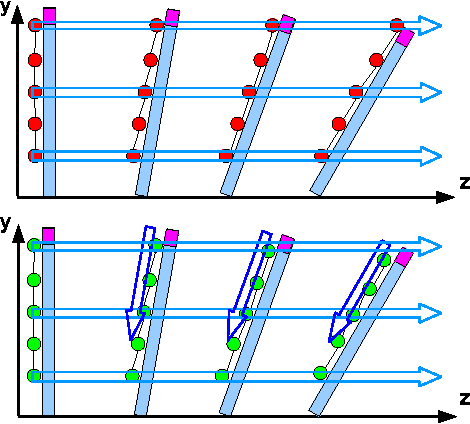
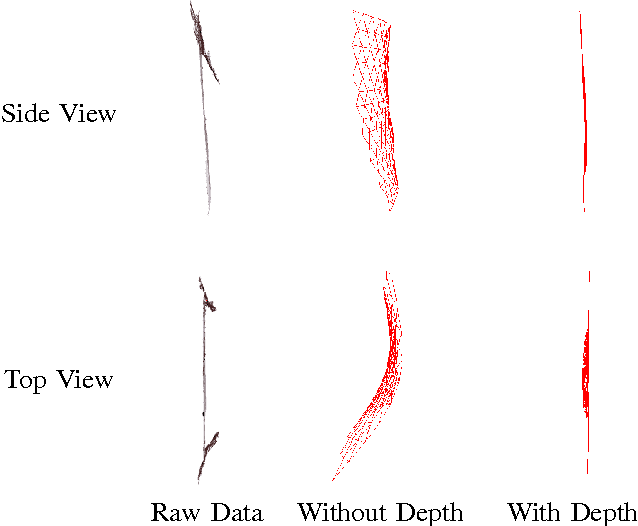
We propose an algorithm that uses energy mini- mization to estimate the current configuration of a non-rigid object. Our approach utilizes an RGBD image to calculate corresponding SURF features, depth, and boundary informa- tion. We do not use predetermined features, thus enabling our system to operate on unmodified objects. Our approach relies on a 3D nonlinear energy minimization framework to solve for the configuration using a semi-implicit scheme. Results show various scenarios of dynamic posters and shirts in different configurations to illustrate the performance of the method. In particular, we show that our method is able to estimate the configuration of a textureless nonrigid object with no correspondences available.
Eyemotion: Classifying facial expressions in VR using eye-tracking cameras
Jul 28, 2017
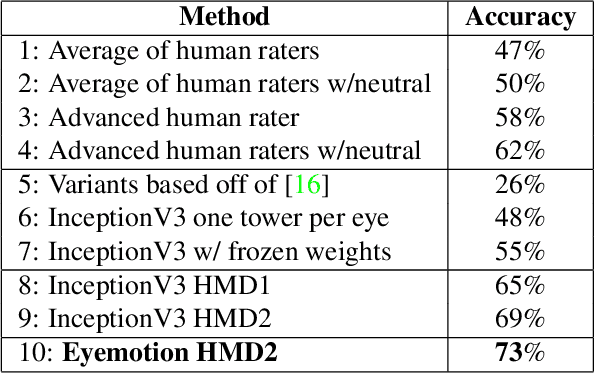
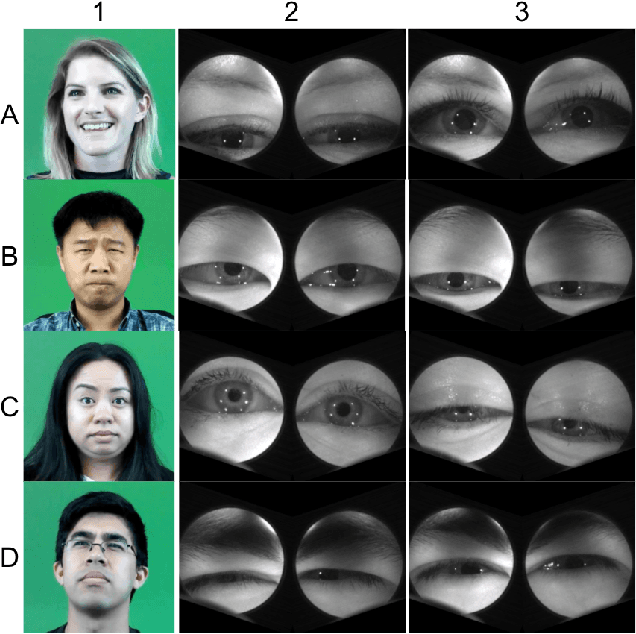
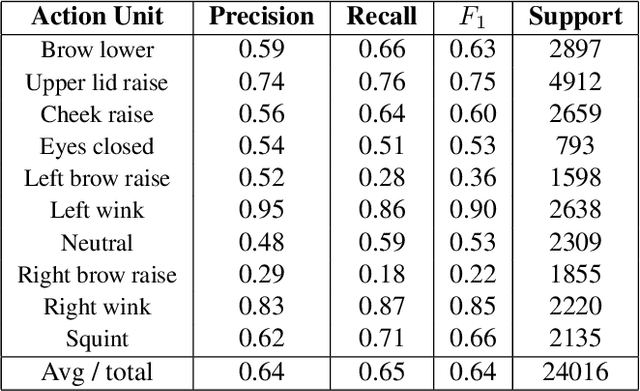
One of the main challenges of social interaction in virtual reality settings is that head-mounted displays occlude a large portion of the face, blocking facial expressions and thereby restricting social engagement cues among users. Hence, auxiliary means of sensing and conveying these expressions are needed. We present an algorithm to automatically infer expressions by analyzing only a partially occluded face while the user is engaged in a virtual reality experience. Specifically, we show that images of the user's eyes captured from an IR gaze-tracking camera within a VR headset are sufficient to infer a select subset of facial expressions without the use of any fixed external camera. Using these inferences, we can generate dynamic avatars in real-time which function as an expressive surrogate for the user. We propose a novel data collection pipeline as well as a novel approach for increasing CNN accuracy via personalization. Our results show a mean accuracy of 74% ($F1$ of 0.73) among 5 `emotive' expressions and a mean accuracy of 70% ($F1$ of 0.68) among 10 distinct facial action units, outperforming human raters.
Predicting Daily Activities From Egocentric Images Using Deep Learning
Oct 06, 2015
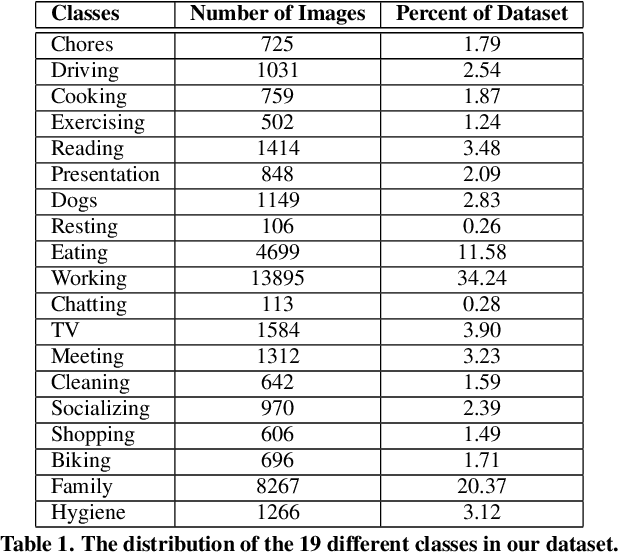

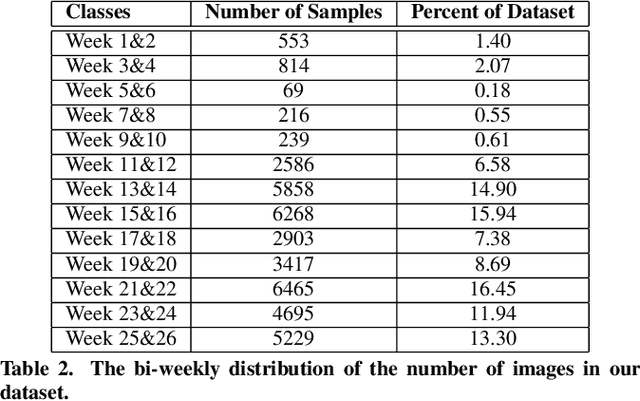
We present a method to analyze images taken from a passive egocentric wearable camera along with the contextual information, such as time and day of week, to learn and predict everyday activities of an individual. We collected a dataset of 40,103 egocentric images over a 6 month period with 19 activity classes and demonstrate the benefit of state-of-the-art deep learning techniques for learning and predicting daily activities. Classification is conducted using a Convolutional Neural Network (CNN) with a classification method we introduce called a late fusion ensemble. This late fusion ensemble incorporates relevant contextual information and increases our classification accuracy. Our technique achieves an overall accuracy of 83.07% in predicting a person's activity across the 19 activity classes. We also demonstrate some promising results from two additional users by fine-tuning the classifier with one day of training data.
* 8 pages