 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Dance: Learning From Online Dance Videos
Jan 23, 2018
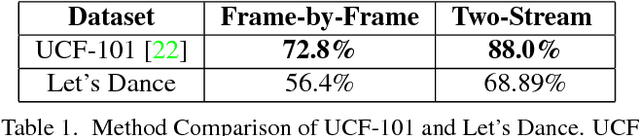

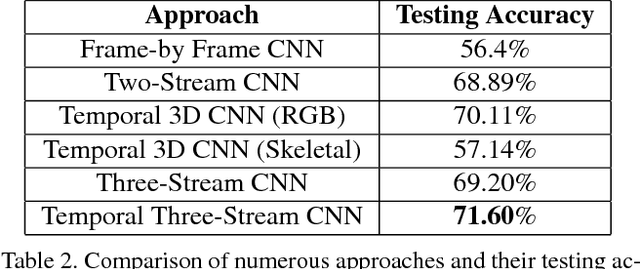
In recent years, deep neural network approaches have naturally extended to the video domain, in their simplest case by aggregating per-frame classifications as a baseline for action recognition. A majority of the work in this area extends from the imaging domain, leading to visual-feature heavy approaches on temporal data. To address this issue we introduce "Let's Dance", a 1000 video dataset (and growing) comprised of 10 visually overlapping dance categories that require motion for their classification. We stress the important of human motion as a key distinguisher in our work given that, as we show in this work, visual information is not sufficient to classify motion-heavy categories. We compare our datasets' performance using imaging techniques with UCF-101 and demonstrate this inherent difficulty. We present a comparison of numerous state-of-the-art techniques on our dataset using three different representations (video, optical flow and multi-person pose data) in order to analyze these approaches. We discuss the motion parameterization of each of them and their value in learning to categorize online dance videos. Lastly, we release this dataset (and its three representations) for the research community to use.