 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Vision-Language Models Respect Contextual Integrity in Location Disclosure?
Feb 04, 2026Vision-language models (VLMs) have demonstrated strong performance in image geolocation, a capability further sharpened by frontier multimodal large reasoning models (MLRMs). This poses a significant privacy risk, as these widely accessible models can be exploited to infer sensitive locations from casually shared photos, often at street-level precision, potentially surpassing the level of detail the sharer consented or intended to disclose. While recent work has proposed applying a blanket restriction on geolocation disclosure to combat this risk, these measures fail to distinguish valid geolocation uses from malicious behavior. Instead, VLMs should maintain contextual integrity by reasoning about elements within an image to determine the appropriate level of information disclosure, balancing privacy and utility. To evaluate how well models respect contextual integrity, we introduce VLM-GEOPRIVACY, a benchmark that challenges VLMs to interpret latent social norms and contextual cues in real-world images and determine the appropriate level of location disclosure. Our evaluation of 14 leading VLMs shows that, despite their ability to precisely geolocate images, the models are poorly aligned with human privacy expectations. They often over-disclose in sensitive contexts and are vulnerable to prompt-based attacks. Our results call for new design principles in multimodal systems to incorporate context-conditioned privacy reasoning.
GeoRC: A Benchmark for Geolocation Reasoning Chains
Jan 29, 2026Vision Language Models (VLMs) are good at recognizing the global location of a photograph -- their geolocation prediction accuracy rivals the best human experts. But many VLMs are startlingly bad at explaining which image evidence led to their prediction, even when their location prediction is correct. The reasoning chains produced by VLMs frequently hallucinate scene attributes to support their location prediction (e.g. phantom writing, imagined infrastructure, misidentified flora). In this paper, we introduce the first benchmark for geolocation reasoning chains. We focus on the global location prediction task in the popular GeoGuessr game which draws from Google Street View spanning more than 100 countries. We collaborate with expert GeoGuessr players, including the reigning world champion, to produce 800 ground truth reasoning chains for 500 query scenes. These expert reasoning chains address hundreds of different discriminative visual attributes such as license plate shape, architecture, and soil properties to name just a few. We evaluate LLM-as-a-judge and VLM-as-a-judge strategies for scoring VLM-generated reasoning chains against our expert reasoning chains and find that Qwen 3 LLM-as-a-judge correlates best with human scoring. Our benchmark reveals that while large, closed-source VLMs such as Gemini and GPT 5 rival human experts at prediction locations, they still lag behind human experts when it comes to producing auditable reasoning chains. Open weights VLMs such as Llama and Qwen catastrophically fail on our benchmark -- they perform only slightly better than a baseline in which an LLM hallucinates a reasoning chain with oracle knowledge of the photo location but no visual information at all. We believe the gap between human experts and VLMs on this task points to VLM limitations at extracting fine-grained visual attributes from high resolution images.
3D Gaussian Point Encoders
Nov 06, 2025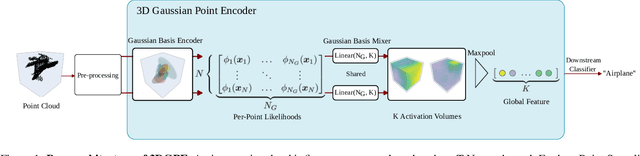
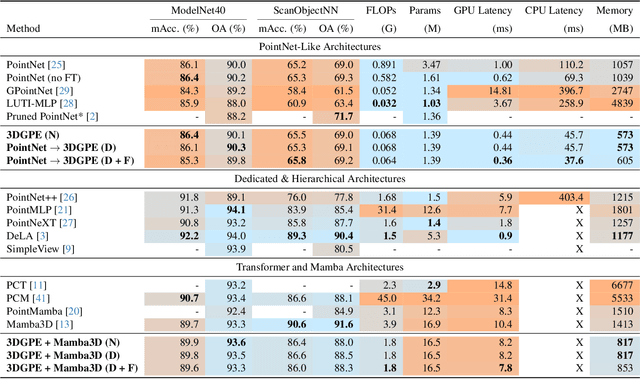
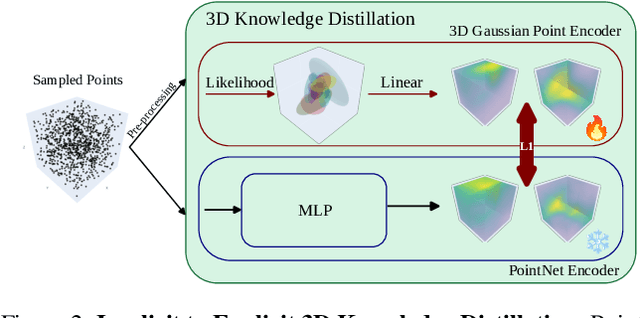
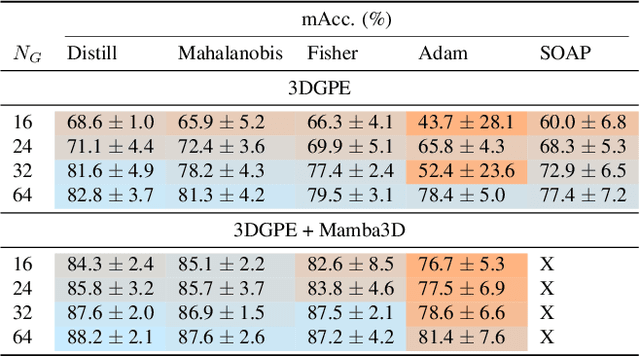
In this work, we introduce the 3D Gaussian Point Encoder, an explicit per-point embedding built on mixtures of learned 3D Gaussians. This explicit geometric representation for 3D recognition tasks is a departure from widely used implicit representations such as PointNet. However, it is difficult to learn 3D Gaussian encoders in end-to-end fashion with standard optimizers. We develop optimization techniques based on natural gradients and distillation from PointNets to find a Gaussian Basis that can reconstruct PointNet activations. The resulting 3D Gaussian Point Encoders are faster and more parameter efficient than traditional PointNets. As in the 3D reconstruction literature where there has been considerable interest in the move from implicit (e.g., NeRF) to explicit (e.g., Gaussian Splatting) representations, we can take advantage of computational geometry heuristics to accelerate 3D Gaussian Point Encoders further. We extend filtering techniques from 3D Gaussian Splatting to construct encoders that run 2.7 times faster as a comparable accuracy PointNet while using 46% less memory and 88% fewer FLOPs. Furthermore, we demonstrate the effectiveness of 3D Gaussian Point Encoders as a component in Mamba3D, running 1.27 times faster and achieving a reduction in memory and FLOPs by 42% and 54% respectively. 3D Gaussian Point Encoders are lightweight enough to achieve high framerates on CPU-only devices.
Clink! Chop! Thud! -- Learning Object Sounds from Real-World Interactions
Oct 02, 2025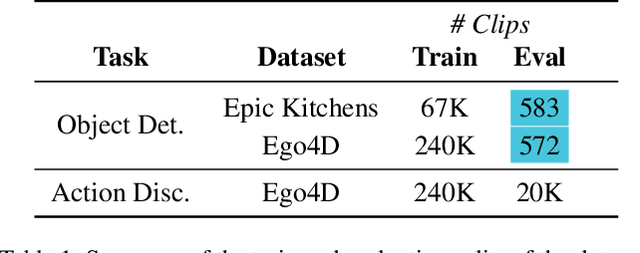

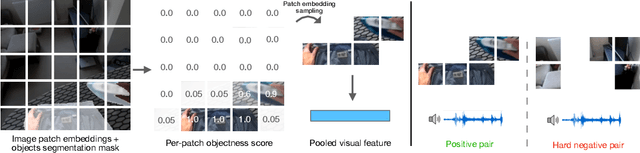
Can a model distinguish between the sound of a spoon hitting a hardwood floor versus a carpeted one? Everyday object interactions produce sounds unique to the objects involved. We introduce the sounding object detection task to evaluate a model's ability to link these sounds to the objects directly involved. Inspired by human perception, our multimodal object-aware framework learns from in-the-wild egocentric videos. To encourage an object-centric approach, we first develop an automatic pipeline to compute segmentation masks of the objects involved to guide the model's focus during training towards the most informative regions of the interaction. A slot attention visual encoder is used to further enforce an object prior. We demonstrate state of the art performance on our new task along with existing multimodal action understanding tasks.
Uncertainty-aware Accurate Elevation Modeling for Off-road Navigation via Neural Processes
Aug 05, 2025Terrain elevation modeling for off-road navigation aims to accurately estimate changes in terrain geometry in real-time and quantify the corresponding uncertainties. Having precise estimations and uncertainties plays a crucial role in planning and control algorithms to explore safe and reliable maneuver strategies. However, existing approaches, such as Gaussian Processes (GPs) and neural network-based methods, often fail to meet these needs. They are either unable to perform in real-time due to high computational demands, underestimating sharp geometry changes, or harming elevation accuracy when learned with uncertainties. Recently, Neural Processes (NPs) have emerged as a promising approach that integrates the Bayesian uncertainty estimation of GPs with the efficiency and flexibility of neural networks. Inspired by NPs, we propose an effective NP-based method that precisely estimates sharp elevation changes and quantifies the corresponding predictive uncertainty without losing elevation accuracy. Our method leverages semantic features from LiDAR and camera sensors to improve interpolation and extrapolation accuracy in unobserved regions. Also, we introduce a local ball-query attention mechanism to effectively reduce the computational complexity of global attention by 17\% while preserving crucial local and spatial information. We evaluate our method on off-road datasets having interesting geometric features, collected from trails, deserts, and hills. Our results demonstrate superior performance over baselines and showcase the potential of neural processes for effective and expressive terrain modeling in complex off-road environments.
GaussianFormer3D: Multi-Modal Gaussian-based Semantic Occupancy Prediction with 3D Deformable Attention
May 15, 2025
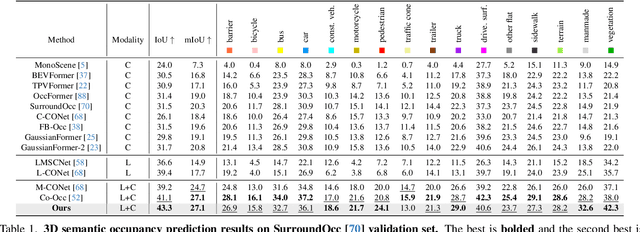
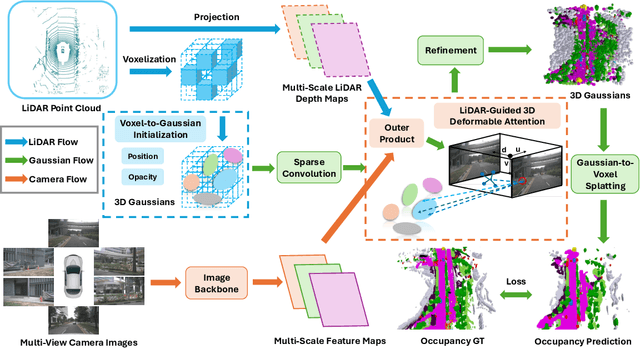
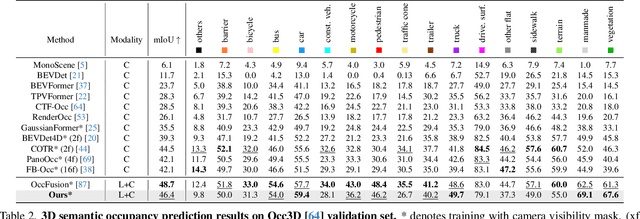
3D semantic occupancy prediction is critical for achieving safe and reliable autonomous driving. Compared to camera-only perception systems, multi-modal pipelines, especially LiDAR-camera fusion methods, can produce more accurate and detailed predictions. Although most existing works utilize a dense grid-based representation, in which the entire 3D space is uniformly divided into discrete voxels, the emergence of 3D Gaussians provides a compact and continuous object-centric representation. In this work, we propose a multi-modal Gaussian-based semantic occupancy prediction framework utilizing 3D deformable attention, named as GaussianFormer3D. We introduce a voxel-to-Gaussian initialization strategy to provide 3D Gaussians with geometry priors from LiDAR data, and design a LiDAR-guided 3D deformable attention mechanism for refining 3D Gaussians with LiDAR-camera fusion features in a lifted 3D space. We conducted extensive experiments on both on-road and off-road datasets, demonstrating that our GaussianFormer3D achieves high prediction accuracy that is comparable to state-of-the-art multi-modal fusion-based methods with reduced memory consumption and improved efficiency.
Dynamic Motion Synthesis: Masked Audio-Text Conditioned Spatio-Temporal Transformers
Sep 03, 2024Our research presents a novel motion generation framework designed to produce whole-body motion sequences conditioned on multiple modalities simultaneously, specifically text and audio inputs. Leveraging Vector Quantized Variational Autoencoders (VQVAEs) for motion discretization and a bidirectional Masked Language Modeling (MLM) strategy for efficient token prediction, our approach achieves improved processing efficiency and coherence in the generated motions. By integrating spatial attention mechanisms and a token critic we ensure consistency and naturalness in the generated motions. This framework expands the possibilities of motion generation, addressing the limitations of existing approaches and opening avenues for multimodal motion synthesis.
What Matters in Range View 3D Object Detection
Jul 25, 2024
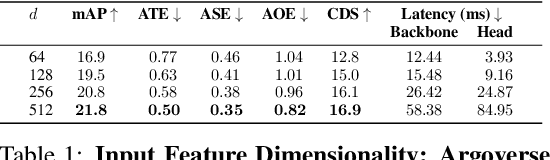
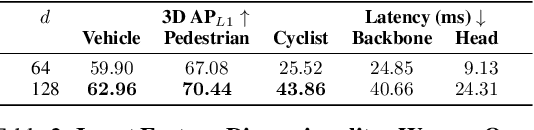
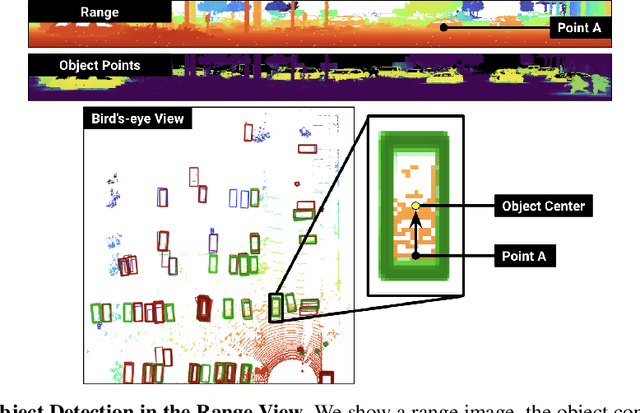
Lidar-based perception pipelines rely on 3D object detection models to interpret complex scenes. While multiple representations for lidar exist, the range-view is enticing since it losslessly encodes the entire lidar sensor output. In this work, we achieve state-of-the-art amongst range-view 3D object detection models without using multiple techniques proposed in past range-view literature. We explore range-view 3D object detection across two modern datasets with substantially different properties: Argoverse 2 and Waymo Open. Our investigation reveals key insights: (1) input feature dimensionality significantly influences the overall performance, (2) surprisingly, employing a classification loss grounded in 3D spatial proximity works as well or better compared to more elaborate IoU-based losses, and (3) addressing non-uniform lidar density via a straightforward range subsampling technique outperforms existing multi-resolution, range-conditioned networks. Our experiments reveal that techniques proposed in recent range-view literature are not needed to achieve state-of-the-art performance. Combining the above findings, we establish a new state-of-the-art model for range-view 3D object detection -- improving AP by 2.2% on the Waymo Open dataset while maintaining a runtime of 10 Hz. We establish the first range-view model on the Argoverse 2 dataset and outperform strong voxel-based baselines. All models are multi-class and open-source. Code is available at https://github.com/benjaminrwilson/range-view-3d-detection.
OmniNOCS: A unified NOCS dataset and model for 3D lifting of 2D objects
Jul 11, 2024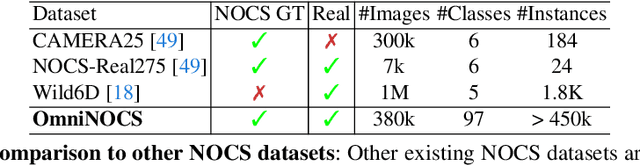


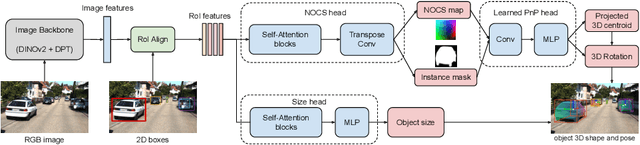
We propose OmniNOCS, a large-scale monocular dataset with 3D Normalized Object Coordinate Space (NOCS) maps, object masks, and 3D bounding box annotations for indoor and outdoor scenes. OmniNOCS has 20 times more object classes and 200 times more instances than existing NOCS datasets (NOCS-Real275, Wild6D). We use OmniNOCS to train a novel, transformer-based monocular NOCS prediction model (NOCSformer) that can predict accurate NOCS, instance masks and poses from 2D object detections across diverse classes. It is the first NOCS model that can generalize to a broad range of classes when prompted with 2D boxes. We evaluate our model on the task of 3D oriented bounding box prediction, where it achieves comparable results to state-of-the-art 3D detection methods such as Cube R-CNN. Unlike other 3D detection methods, our model also provides detailed and accurate 3D object shape and segmentation. We propose a novel benchmark for the task of NOCS prediction based on OmniNOCS, which we hope will serve as a useful baseline for future work in this area. Our dataset and code will be at the project website: https://omninocs.github.io.
Granular Privacy Control for Geolocation with Vision Language Models
Jul 06, 2024

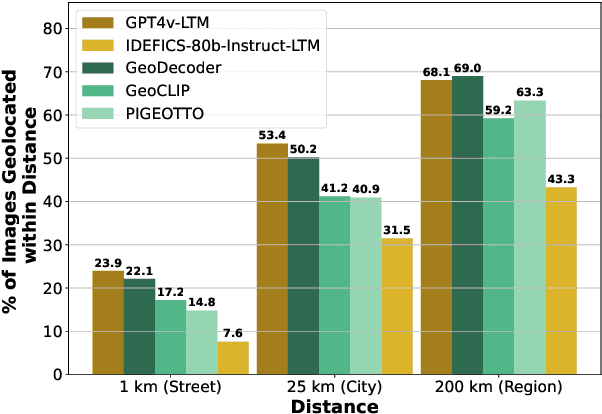
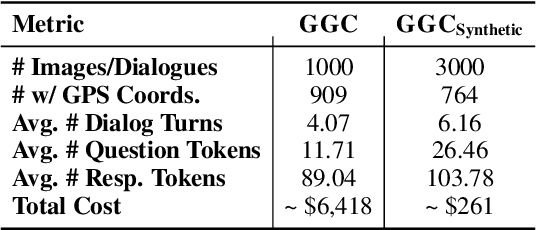
Vision Language Models (VLMs) are rapidly advancing in their capability to answer information-seeking questions. As these models are widely deployed in consumer applications, they could lead to new privacy risks due to emergent abilities to identify people in photos, geolocate images, etc. As we demonstrate, somewhat surprisingly, current open-source and proprietary VLMs are very capable image geolocators, making widespread geolocation with VLMs an immediate privacy risk, rather than merely a theoretical future concern. As a first step to address this challenge, we develop a new benchmark, GPTGeoChat, to test the ability of VLMs to moderate geolocation dialogues with users. We collect a set of 1,000 image geolocation conversations between in-house annotators and GPT-4v, which are annotated with the granularity of location information revealed at each turn. Using this new dataset, we evaluate the ability of various VLMs to moderate GPT-4v geolocation conversations by determining when too much location information has been revealed. We find that custom fine-tuned models perform on par with prompted API-based models when identifying leaked location information at the country or city level; however, fine-tuning on supervised data appears to be needed to accurately moderate finer granularities, such as the name of a restaurant or building.