 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Matters in Range View 3D Object Detection
Jul 25, 2024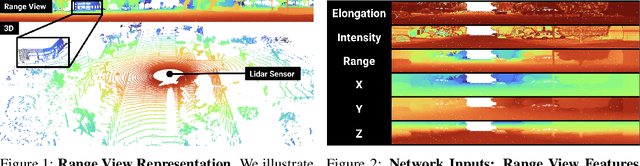
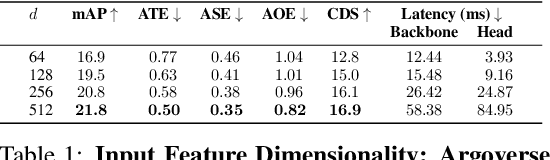
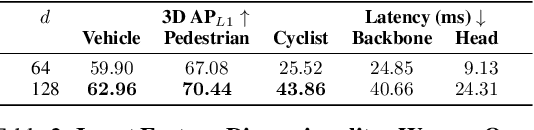
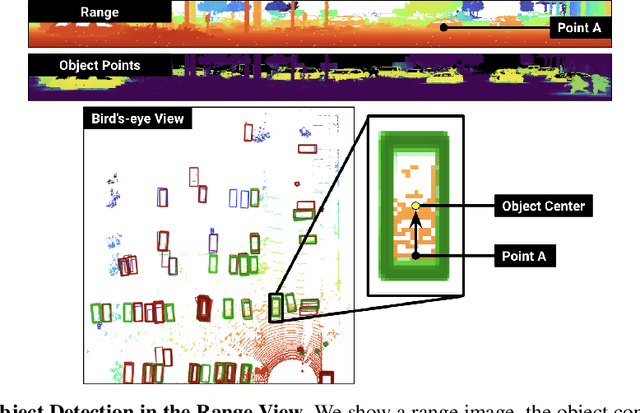
Lidar-based perception pipelines rely on 3D object detection models to interpret complex scenes. While multiple representations for lidar exist, the range-view is enticing since it losslessly encodes the entire lidar sensor output. In this work, we achieve state-of-the-art amongst range-view 3D object detection models without using multiple techniques proposed in past range-view literature. We explore range-view 3D object detection across two modern datasets with substantially different properties: Argoverse 2 and Waymo Open. Our investigation reveals key insights: (1) input feature dimensionality significantly influences the overall performance, (2) surprisingly, employing a classification loss grounded in 3D spatial proximity works as well or better compared to more elaborate IoU-based losses, and (3) addressing non-uniform lidar density via a straightforward range subsampling technique outperforms existing multi-resolution, range-conditioned networks. Our experiments reveal that techniques proposed in recent range-view literature are not needed to achieve state-of-the-art performance. Combining the above findings, we establish a new state-of-the-art model for range-view 3D object detection -- improving AP by 2.2% on the Waymo Open dataset while maintaining a runtime of 10 Hz. We establish the first range-view model on the Argoverse 2 dataset and outperform strong voxel-based baselines. All models are multi-class and open-source. Code is available at https://github.com/benjaminrwilson/range-view-3d-detection.
Fast Neural Scene Flow
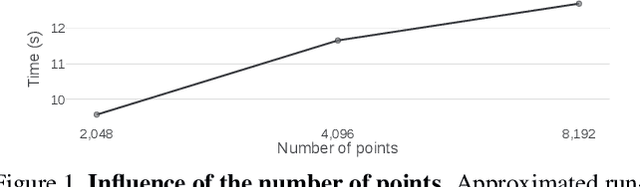
Apr 20, 2023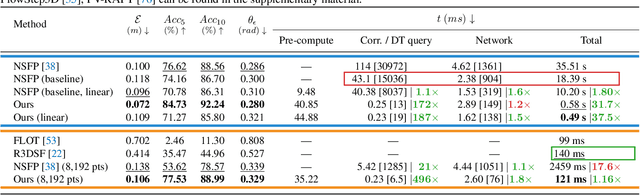



Neural Scene Flow Prior (NSFP) is of significant interest to the vision community due to its inherent robustness to out-of-distribution (OOD) effects and its ability to deal with dense lidar points. The approach utilizes a coordinate neural network to estimate scene flow at runtime, without any training. However, it is up to 100 times slower than current state-of-the-art learning methods. In other applications such as image, video, and radiance function reconstruction innovations in speeding up the runtime performance of coordinate networks have centered upon architectural changes. In this paper, we demonstrate that scene flow is different -- with the dominant computational bottleneck stemming from the loss function itself (i.e., Chamfer distance). Further, we rediscover the distance transform (DT) as an efficient, correspondence-free loss function that dramatically speeds up the runtime optimization. Our fast neural scene flow (FNSF) approach reports for the first time real-time performance comparable to learning methods, without any training or OOD bias on two of the largest open autonomous driving (AV) lidar datasets Waymo Open and Argoverse.
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
Jan 02, 2023



We introduce Argoverse 2 (AV2) - a collection of three datasets for perception and forecasting research in the self-driving domain. The annotated Sensor Dataset contains 1,000 sequences of multimodal data, encompassing high-resolution imagery from seven ring cameras, and two stereo cameras in addition to lidar point clouds, and 6-DOF map-aligned pose. Sequences contain 3D cuboid annotations for 26 object categories, all of which are sufficiently-sampled to support training and evaluation of 3D perception models. The Lidar Dataset contains 20,000 sequences of unlabeled lidar point clouds and map-aligned pose. This dataset is the largest ever collection of lidar sensor data and supports self-supervised learning and the emerging task of point cloud forecasting. Finally, the Motion Forecasting Dataset contains 250,000 scenarios mined for interesting and challenging interactions between the autonomous vehicle and other actors in each local scene. Models are tasked with the prediction of future motion for "scored actors" in each scenario and are provided with track histories that capture object location, heading, velocity, and category. In all three datasets, each scenario contains its own HD Map with 3D lane and crosswalk geometry - sourced from data captured in six distinct cities. We believe these datasets will support new and existing machine learning research problems in ways that existing datasets do not. All datasets are released under the CC BY-NC-SA 4.0 license.
Neural Scene Flow Prior
Nov 01, 2021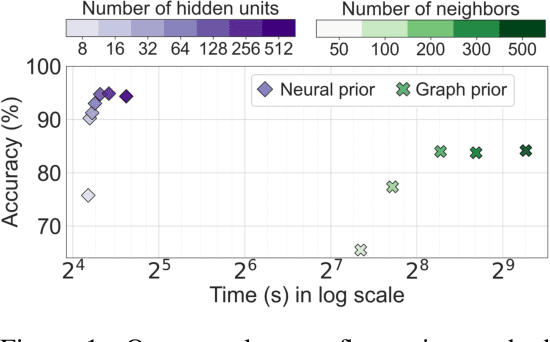
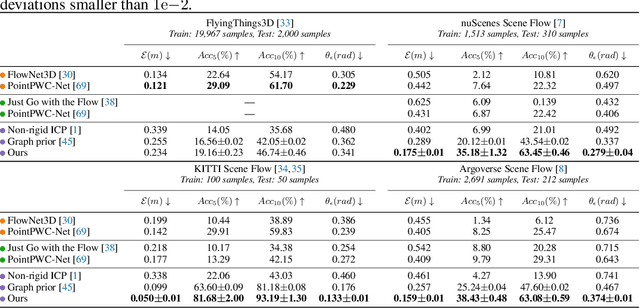


Before the deep learning revolution, many perception algorithms were based on runtime optimization in conjunction with a strong prior/regularization penalty. A prime example of this in computer vision is optical and scene flow. Supervised learning has largely displaced the need for explicit regularization. Instead, they rely on large amounts of labeled data to capture prior statistics, which are not always readily available for many problems. Although optimization is employed to learn the neural network, the weights of this network are frozen at runtime. As a result, these learning solutions are domain-specific and do not generalize well to other statistically different scenarios. This paper revisits the scene flow problem that relies predominantly on runtime optimization and strong regularization. A central innovation here is the inclusion of a neural scene flow prior, which uses the architecture of neural networks as a new type of implicit regularizer. Unlike learning-based scene flow methods, optimization occurs at runtime, and our approach needs no offline datasets -- making it ideal for deployment in new environments such as autonomous driving. We show that an architecture based exclusively on multilayer perceptrons (MLPs) can be used as a scene flow prior. Our method attains competitive -- if not better -- results on scene flow benchmarks. Also, our neural prior's implicit and continuous scene flow representation allows us to estimate dense long-term correspondences across a sequence of point clouds. The dense motion information is represented by scene flow fields where points can be propagated through time by integrating motion vectors. We demonstrate such a capability by accumulating a sequence of lidar point clouds.
Scene Flow from Point Clouds with or without Learning
Oct 31, 2020

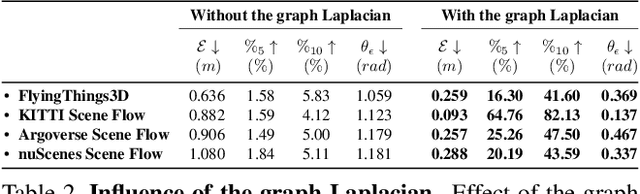
Scene flow is the three-dimensional (3D) motion field of a scene. It provides information about the spatial arrangement and rate of change of objects in dynamic environments. Current learning-based approaches seek to estimate the scene flow directly from point clouds and have achieved state-of-the-art performance. However, supervised learning methods are inherently domain specific and require a large amount of labeled data. Annotation of scene flow on real-world point clouds is expensive and challenging, and the lack of such datasets has recently sparked interest in self-supervised learning methods. How to accurately and robustly learn scene flow representations without labeled real-world data is still an open problem. Here we present a simple and interpretable objective function to recover the scene flow from point clouds. We use the graph Laplacian of a point cloud to regularize the scene flow to be "as-rigid-as-possible". Our proposed objective function can be used with or without learning---as a self-supervisory signal to learn scene flow representations, or as a non-learning-based method in which the scene flow is optimized during runtime. Our approach outperforms related works in many datasets. We also show the immediate applications of our proposed method for two applications: motion segmentation and point cloud densification.
Deterministic PointNetLK for Generalized Registration
Aug 21, 2020
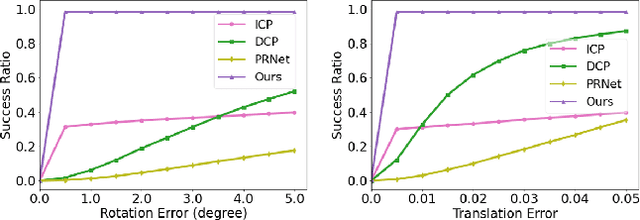
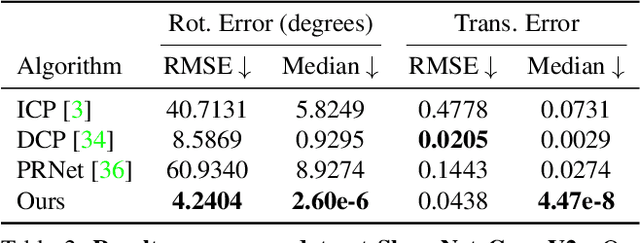
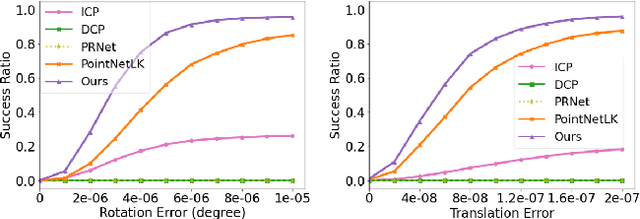
There has been remarkable progress in the application of deep learning to 3D point cloud registration in recent years. Despite their success, these approaches tend to have poor generalization properties when attempting to align unseen point clouds at test time. PointNetLK has proven the exception to this rule by leveraging the intrinsic generalization properties of the Lucas & Kanade (LK) image alignment algorithm to point cloud registration. The approach relies heavily upon the estimation of a gradient through finite differentiation -- a strategy that is inherently ill-conditioned and highly sensitive to the step-size choice. To avoid these problems, we propose a deterministic PointNetLK method that uses analytical gradients. We also develop several strategies to improve large-volume point cloud processing. We compare our approach to canonical PointNetLK and other state-of-the-art methods and demonstrate how our approach provides accurate, reliable registration with high fidelity. Extended experiments on noisy, sparse, and partial point clouds depict the utility of our approach for many real-world scenarios. Further, the decomposition of the Jacobian matrix affords the reuse of feature embeddings for alternate warp functions.