 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORB: Operating Room Bot, Automating Operating Room Logistics through Mobile Manipulation
Sep 19, 2025
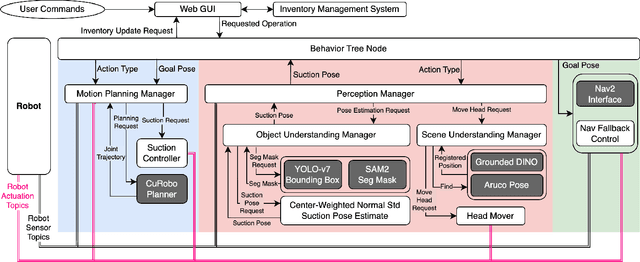


Efficiently delivering items to an ongoing surgery in a hospital operating room can be a matter of life or death. In modern hospital settings, delivery robots have successfully transported bulk items between rooms and floors. However, automating item-level operating room logistics presents unique challenges in perception, efficiency, and maintaining sterility. We propose the Operating Room Bot (ORB), a robot framework to automate logistics tasks in hospital operating rooms (OR). ORB leverages a robust, hierarchical behavior tree (BT) architecture to integrate diverse functionalities of object recognition, scene interpretation, and GPU-accelerated motion planning. The contributions of this paper include: (1) a modular software architecture facilitating robust mobile manipulation through behavior trees; (2) a novel real-time object recognition pipeline integrating YOLOv7, Segment Anything Model 2 (SAM2), and Grounded DINO; (3) the adaptation of the cuRobo parallelized trajectory optimization framework to real-time, collision-free mobile manipulation; and (4) empirical validation demonstrating an 80% success rate in OR supply retrieval and a 96% success rate in restocking operations. These contributions establish ORB as a reliable and adaptable system for autonomous OR logistics.
Modeling Dynamic Environments with Scene Graph Memory
Jun 12, 2023Embodied AI agents that search for objects in large environments such as households often need to make efficient decisions by predicting object locations based on partial information. We pose this as a new type of link prediction problem: link prediction on partially observable dynamic graphs. Our graph is a representation of a scene in which rooms and objects are nodes, and their relationships are encoded in the edges; only parts of the changing graph are known to the agent at each timestep. This partial observability poses a challenge to existing link prediction approaches, which we address. We propose a novel state representation -- Scene Graph Memory (SGM) -- with captures the agent's accumulated set of observations, as well as a neural net architecture called a Node Edge Predictor (NEP) that extracts information from the SGM to search efficiently. We evaluate our method in the Dynamic House Simulator, a new benchmark that creates diverse dynamic graphs following the semantic patterns typically seen at homes, and show that NEP can be trained to predict the locations of objects in a variety of environments with diverse object movement dynamics, outperforming baselines both in terms of new scene adaptability and overall accuracy. The codebase and more can be found at https://www.scenegraphmemory.com.
The ObjectFolder Benchmark: Multisensory Learning with Neural and Real Objects
Jun 01, 2023



We introduce the ObjectFolder Benchmark, a benchmark suite of 10 tasks for multisensory object-centric learning, centered around object recognition, reconstruction, and manipulation with sight, sound, and touch. We also introduce the ObjectFolder Real dataset, including the multisensory measurements for 100 real-world household objects, building upon a newly designed pipeline for collecting the 3D meshes, videos, impact sounds, and tactile readings of real-world objects. We conduct systematic benchmarking on both the 1,000 multisensory neural objects from ObjectFolder, and the real multisensory data from ObjectFolder Real. Our results demonstrate the importance of multisensory perception and reveal the respective roles of vision, audio, and touch for different object-centric learning tasks. By publicly releasing our dataset and benchmark suite, we hope to catalyze and enable new research in multisensory object-centric learning in computer vision, robotics, and beyond. Project page: https://objectfolder.stanford.edu
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
Jan 02, 2023



We introduce Argoverse 2 (AV2) - a collection of three datasets for perception and forecasting research in the self-driving domain. The annotated Sensor Dataset contains 1,000 sequences of multimodal data, encompassing high-resolution imagery from seven ring cameras, and two stereo cameras in addition to lidar point clouds, and 6-DOF map-aligned pose. Sequences contain 3D cuboid annotations for 26 object categories, all of which are sufficiently-sampled to support training and evaluation of 3D perception models. The Lidar Dataset contains 20,000 sequences of unlabeled lidar point clouds and map-aligned pose. This dataset is the largest ever collection of lidar sensor data and supports self-supervised learning and the emerging task of point cloud forecasting. Finally, the Motion Forecasting Dataset contains 250,000 scenarios mined for interesting and challenging interactions between the autonomous vehicle and other actors in each local scene. Models are tasked with the prediction of future motion for "scored actors" in each scenario and are provided with track histories that capture object location, heading, velocity, and category. In all three datasets, each scenario contains its own HD Map with 3D lane and crosswalk geometry - sourced from data captured in six distinct cities. We believe these datasets will support new and existing machine learning research problems in ways that existing datasets do not. All datasets are released under the CC BY-NC-SA 4.0 license.
Affordance-based Reinforcement Learning for Urban Driving
Jan 15, 2021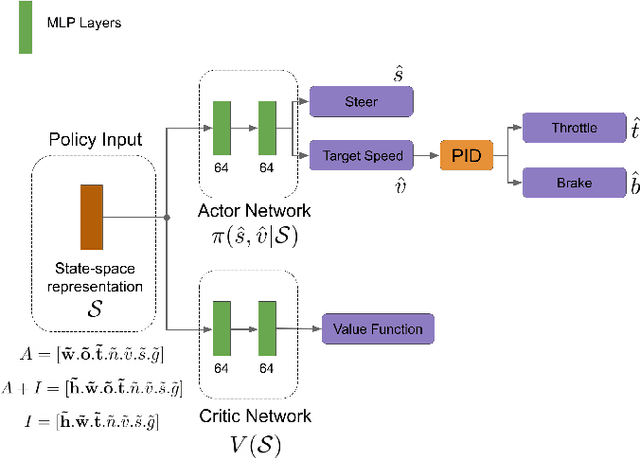

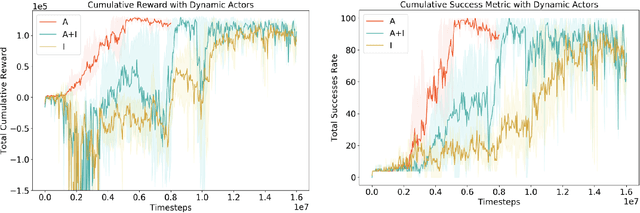

Traditional autonomous vehicle pipelines that follow a modular approach have been very successful in the past both in academia and industry, which has led to autonomy deployed on road. Though this approach provides ease of interpretation, its generalizability to unseen environments is limited and hand-engineering of numerous parameters is required, especially in the prediction and planning systems. Recently, deep reinforcement learning has been shown to learn complex strategic games and perform challenging robotic tasks, which provides an appealing framework for learning to drive. In this work, we propose a deep reinforcement learning framework to learn optimal control policy using waypoints and low-dimensional visual representations, also known as affordances. We demonstrate that our agents when trained from scratch learn the tasks of lane-following, driving around inter-sections as well as stopping in front of other actors or traffic lights even in the dense traffic setting. We note that our method achieves comparable or better performance than the baseline methods on the original and NoCrash benchmarks on the CARLA simulator.