 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug-and-Play, Dense-Label-Free Extraction of Open-Vocabulary Semantic Segmentation from Vision-Language Models
Nov 28, 2023From an enormous amount of image-text pairs, large-scale vision-language models (VLMs) learn to implicitly associate image regions with words, which is vital for tasks such as image captioning and visual question answering. However, leveraging such pre-trained models for open-vocabulary semantic segmentation remains a challenge. In this paper, we propose a simple, yet extremely effective, training-free technique, Plug-and-Play Open-Vocabulary Semantic Segmentation (PnP-OVSS) for this task. PnP-OVSS leverages a VLM with direct text-to-image cross-attention and an image-text matching loss to produce semantic segmentation. However, cross-attention alone tends to over-segment, whereas cross-attention plus GradCAM tend to under-segment. To alleviate this issue, we introduce Salience Dropout; by iteratively dropping patches that the model is most attentive to, we are able to better resolve the entire extent of the segmentation mask. Compared to existing techniques, the proposed method does not require any neural network training and performs hyperparameter tuning without the need for any segmentation annotations, even for a validation set. PnP-OVSS demonstrates substantial improvements over a comparable baseline (+29.4% mIoU on Pascal VOC, +13.2% mIoU on Pascal Context, +14.0% mIoU on MS COCO, +2.4% mIoU on COCO Stuff) and even outperforms most baselines that conduct additional network training on top of pretrained VLMs.
Frustratingly Simple but Effective Zero-shot Detection and Segmentation: Analysis and a Strong Baseline
Feb 14, 2023Methods for object detection and segmentation often require abundant instance-level annotations for training, which are time-consuming and expensive to collect. To address this, the task of zero-shot object detection (or segmentation) aims at learning effective methods for identifying and localizing object instances for the categories that have no supervision available. Constructing architectures for these tasks requires choosing from a myriad of design options, ranging from the form of the class encoding used to transfer information from seen to unseen categories, to the nature of the function being optimized for learning. In this work, we extensively study these design choices, and carefully construct a simple yet extremely effective zero-shot recognition method. Through extensive experiments on the MSCOCO dataset on object detection and segmentation, we highlight that our proposed method outperforms existing, considerably more complex, architectures. Our findings and method, which we propose as a competitive future baseline, point towards the need to revisit some of the recent design trends in zero-shot detection / segmentation.
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
Jan 02, 2023



We introduce Argoverse 2 (AV2) - a collection of three datasets for perception and forecasting research in the self-driving domain. The annotated Sensor Dataset contains 1,000 sequences of multimodal data, encompassing high-resolution imagery from seven ring cameras, and two stereo cameras in addition to lidar point clouds, and 6-DOF map-aligned pose. Sequences contain 3D cuboid annotations for 26 object categories, all of which are sufficiently-sampled to support training and evaluation of 3D perception models. The Lidar Dataset contains 20,000 sequences of unlabeled lidar point clouds and map-aligned pose. This dataset is the largest ever collection of lidar sensor data and supports self-supervised learning and the emerging task of point cloud forecasting. Finally, the Motion Forecasting Dataset contains 250,000 scenarios mined for interesting and challenging interactions between the autonomous vehicle and other actors in each local scene. Models are tasked with the prediction of future motion for "scored actors" in each scenario and are provided with track histories that capture object location, heading, velocity, and category. In all three datasets, each scenario contains its own HD Map with 3D lane and crosswalk geometry - sourced from data captured in six distinct cities. We believe these datasets will support new and existing machine learning research problems in ways that existing datasets do not. All datasets are released under the CC BY-NC-SA 4.0 license.
Iterative Scene Graph Generation
Jul 27, 2022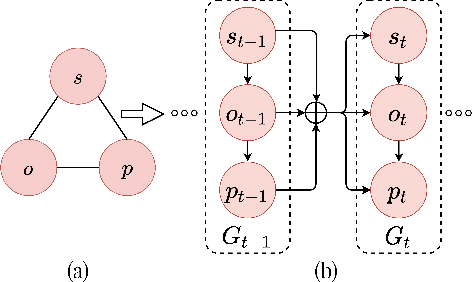
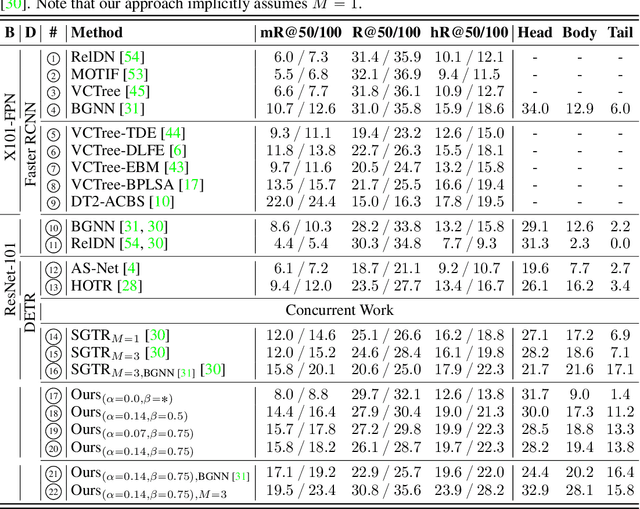
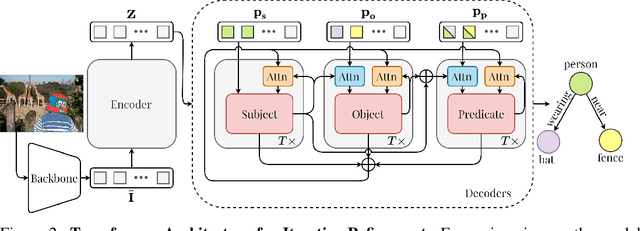
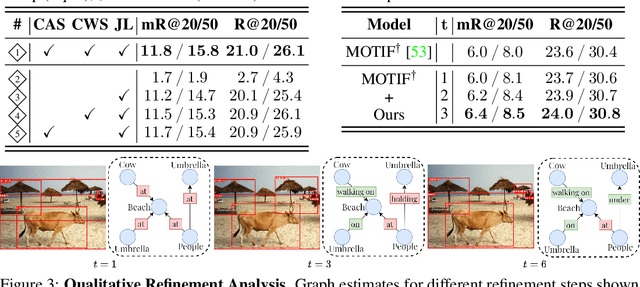
The task of scene graph generation entails identifying object entities and their corresponding interaction predicates in a given image (or video). Due to the combinatorially large solution space, existing approaches to scene graph generation assume certain factorization of the joint distribution to make the estimation feasible (e.g., assuming that objects are conditionally independent of predicate predictions). However, this fixed factorization is not ideal under all scenarios (e.g., for images where an object entailed in interaction is small and not discernible on its own). In this work, we propose a novel framework for scene graph generation that addresses this limitation, as well as introduces dynamic conditioning on the image, using message passing in a Markov Random Field. This is implemented as an iterative refinement procedure wherein each modification is conditioned on the graph generated in the previous iteration. This conditioning across refinement steps allows joint reasoning over entities and relations. This framework is realized via a novel and end-to-end trainable transformer-based architecture. In addition, the proposed framework can improve existing approach performance. Through extensive experiments on Visual Genome and Action Genome benchmark datasets we show improved performance on the scene graph generation.
Segmentation-grounded Scene Graph Generation
Apr 29, 2021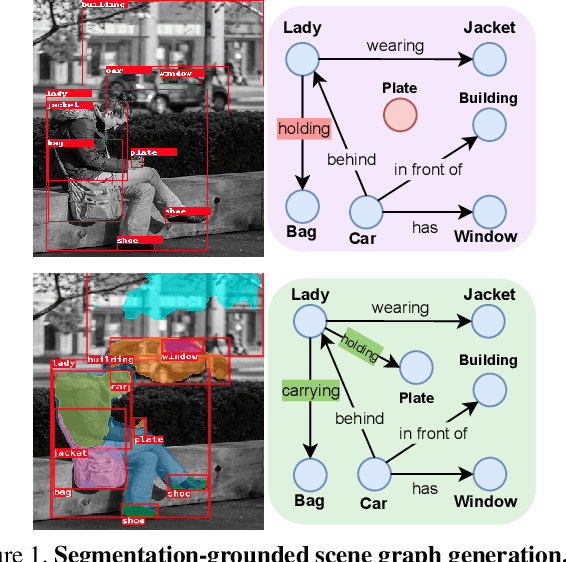
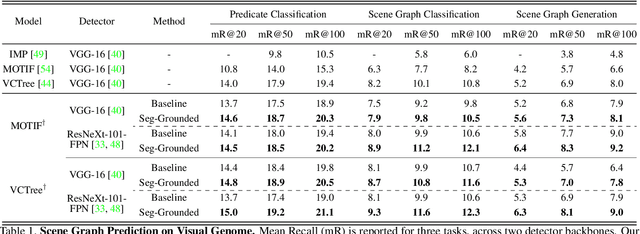
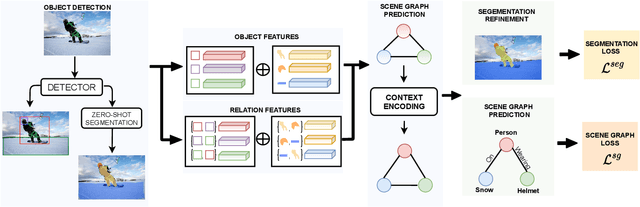
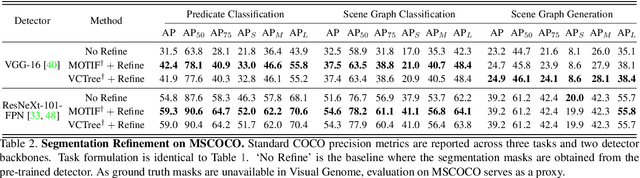
Scene graph generation has emerged as an important problem in computer vision. While scene graphs provide a grounded representation of objects, their locations and relations in an image, they do so only at the granularity of proposal bounding boxes. In this work, we propose the first, to our knowledge, framework for pixel-level segmentation-grounded scene graph generation. Our framework is agnostic to the underlying scene graph generation method and address the lack of segmentation annotations in target scene graph datasets (e.g., Visual Genome) through transfer and multi-task learning from, and with, an auxiliary dataset (e.g., MS COCO). Specifically, each target object being detected is endowed with a segmentation mask, which is expressed as a lingual-similarity weighted linear combination over categories that have annotations present in an auxiliary dataset. These inferred masks, along with a novel Gaussian attention mechanism which grounds the relations at a pixel-level within the image, allow for improved relation prediction. The entire framework is end-to-end trainable and is learned in a multi-task manner with both target and auxiliary datasets.
What-If Motion Prediction for Autonomous Driving
Aug 24, 2020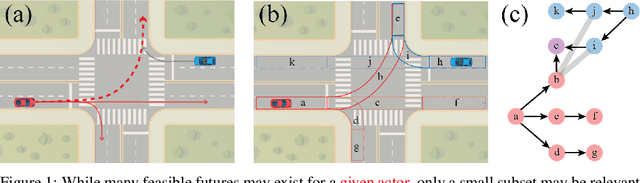
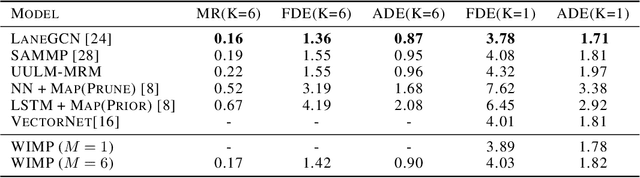
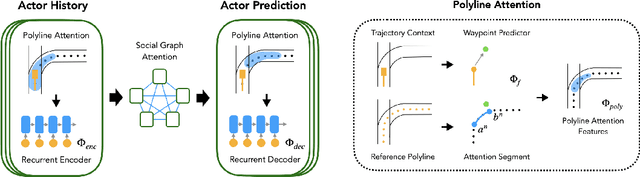
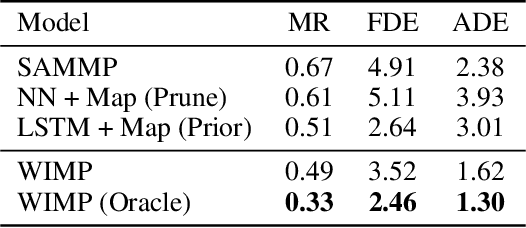
Forecasting the long-term future motion of road actors is a core challenge to the deployment of safe autonomous vehicles (AVs). Viable solutions must account for both the static geometric context, such as road lanes, and dynamic social interactions arising from multiple actors. While recent deep architectures have achieved state-of-the-art performance on distance-based forecasting metrics, these approaches produce forecasts that are predicted without regard to the AV's intended motion plan. In contrast, we propose a recurrent graph-based attentional approach with interpretable geometric (actor-lane) and social (actor-actor) relationships that supports the injection of counterfactual geometric goals and social contexts. Our model can produce diverse predictions conditioned on hypothetical or "what-if" road lanes and multi-actor interactions. We show that such an approach could be used in the planning loop to reason about unobserved causes or unlikely futures that are directly relevant to the AV's intended route.
Weakly-supervised Any-shot Object Detection
Jun 12, 2020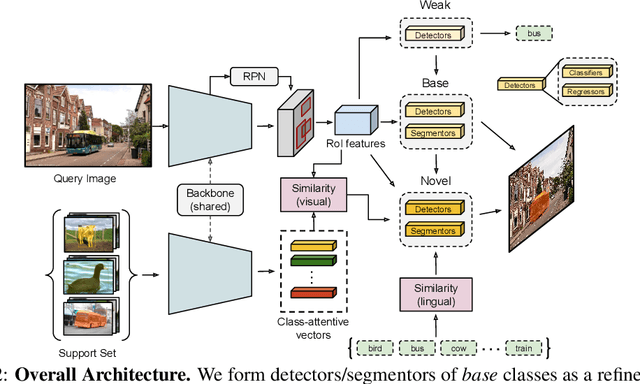
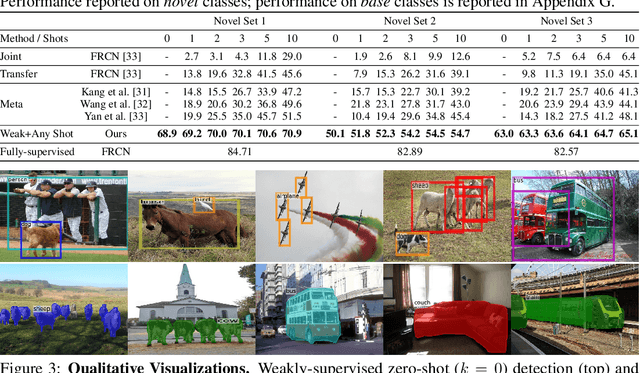
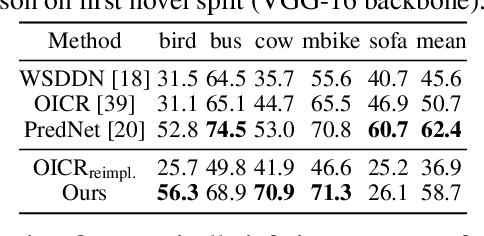
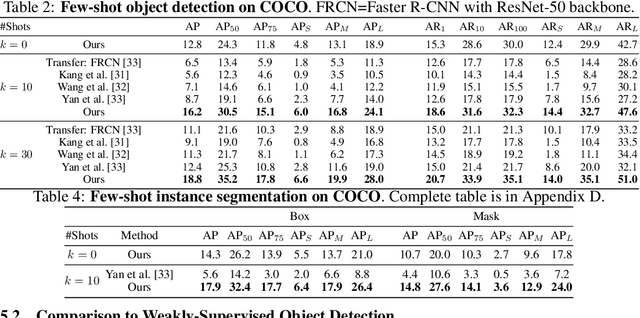
Methods for object detection and segmentation rely on large scale instance-level annotations for training, which are difficult and time-consuming to collect. Efforts to alleviate this look at varying degrees and quality of supervision. Weakly-supervised approaches draw on image-level labels to build detectors/segmentors, while zero/few-shot methods assume abundant instance-level data for a set of base classes, and none to a few examples for novel classes. This taxonomy has largely siloed algorithmic designs. In this work, we aim to bridge this divide by proposing an intuitive weakly-supervised model that is applicable to a range of supervision: from zero to a few instance-level samples per novel class. For base classes, our model learns a mapping from weakly-supervised to fully-supervised detectors/segmentors. By learning and leveraging visual and lingual similarities between the novel and base classes, we transfer those mappings to obtain detectors/segmentors for novel classes; refining them with a few novel class instance-level annotated samples, if available. The overall model is end-to-end trainable and highly flexible. Through extensive experiments on MS-COCO and Pascal VOC benchmark datasets we show improved performance in a variety of settings.
AttentionRNN: A Structured Spatial Attention Mechanism
May 22, 2019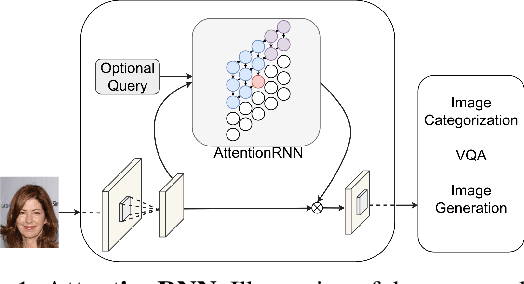
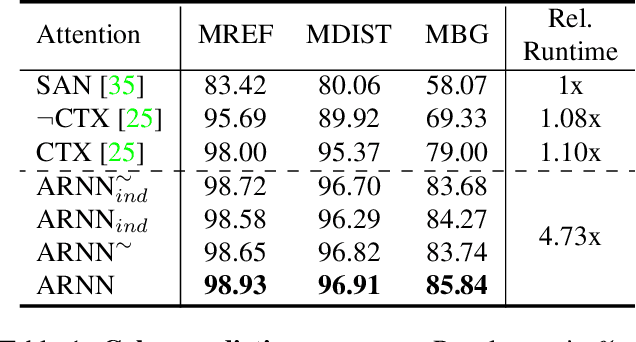
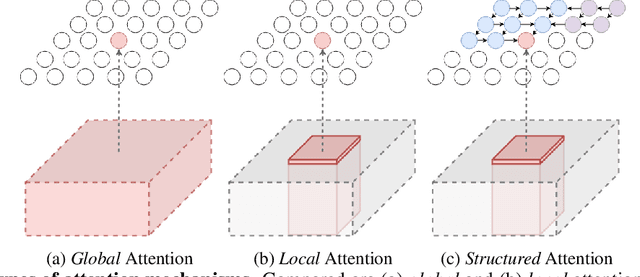
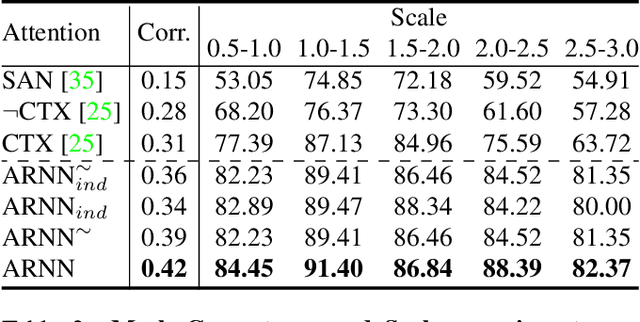
Visual attention mechanisms have proven to be integrally important constituent components of many modern deep neural architectures. They provide an efficient and effective way to utilize visual information selectively, which has shown to be especially valuable in multi-modal learning tasks. However, all prior attention frameworks lack the ability to explicitly model structural dependencies among attention variables, making it difficult to predict consistent attention masks. In this paper we develop a novel structured spatial attention mechanism which is end-to-end trainable and can be integrated with any feed-forward convolutional neural network. This proposed AttentionRNN layer explicitly enforces structure over the spatial attention variables by sequentially predicting attention values in the spatial mask in a bi-directional raster-scan and inverse raster-scan order. As a result, each attention value depends not only on local image or contextual information, but also on the previously predicted attention values. Our experiments show consistent quantitative and qualitative improvements on a variety of recognition tasks and datasets; including image categorization, question answering and image generation.
Improving Distantly Supervised Relation Extraction using Word and Entity Based Attention
Apr 19, 2018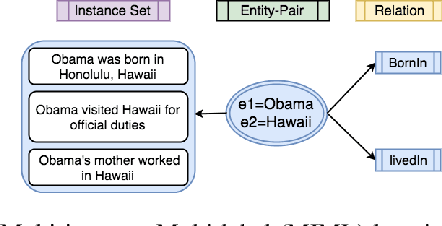

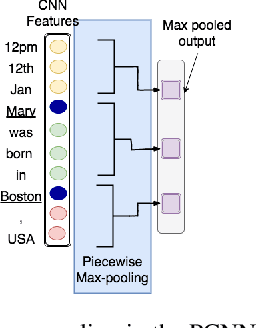
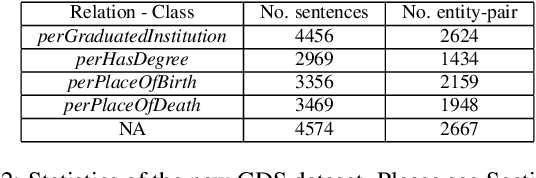
Relation extraction is the problem of classifying the relationship between two entities in a given sentence. Distant Supervision (DS) is a popular technique for developing relation extractors starting with limited supervision. We note that most of the sentences in the distant supervision relation extraction setting are very long and may benefit from word attention for better sentence representation. Our contributions in this paper are threefold. Firstly, we propose two novel word attention models for distantly- supervised relation extraction: (1) a Bi-directional Gated Recurrent Unit (Bi-GRU) based word attention model (BGWA), (2) an entity-centric attention model (EA), and (3) a combination model which combines multiple complementary models using weighted voting method for improved relation extraction. Secondly, we introduce GDS, a new distant supervision dataset for relation extraction. GDS removes test data noise present in all previous distant- supervision benchmark datasets, making credible automatic evaluation possible. Thirdly, through extensive experiments on multiple real-world datasets, we demonstrate the effectiveness of the proposed methods.
Faster K-Means Cluster Estimation
Jan 17, 2017

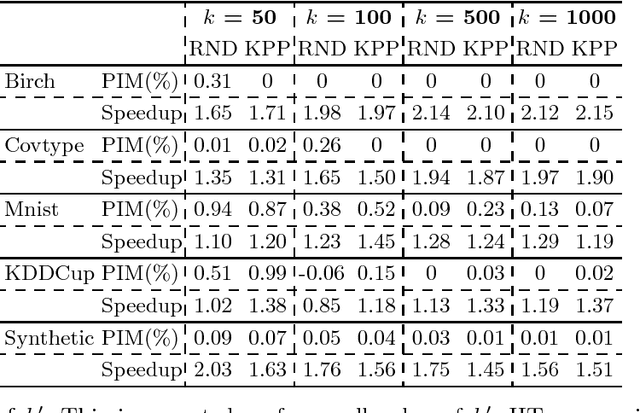
There has been considerable work on improving popular clustering algorithm `K-means' in terms of mean squared error (MSE) and speed, both. However, most of the k-means variants tend to compute distance of each data point to each cluster centroid for every iteration. We propose a fast heuristic to overcome this bottleneck with only marginal increase in MSE. We observe that across all iterations of K-means, a data point changes its membership only among a small subset of clusters. Our heuristic predicts such clusters for each data point by looking at nearby clusters after the first iteration of k-means. We augment well known variants of k-means with our heuristic to demonstrate effectiveness of our heuristic. For various synthetic and real-world datasets, our heuristic achieves speed-up of up-to 3 times when compared to efficient variants of k-means.