 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuzzle Curriculum GRPO for Vision-Centric Reasoning
Dec 16, 2025Recent reinforcement learning (RL) approaches like outcome-supervised GRPO have advanced chain-of-thought reasoning in Vision Language Models (VLMs), yet key issues linger: (i) reliance on costly and noisy hand-curated annotations or external verifiers; (ii) flat and sparse reward schemes in GRPO; and (iii) logical inconsistency between a chain's reasoning and its final answer. We present Puzzle Curriculum GRPO (PC-GRPO), a supervision-free recipe for RL with Verifiable Rewards (RLVR) that strengthens visual reasoning in VLMs without annotations or external verifiers. PC-GRPO replaces labels with three self-supervised puzzle environments: PatchFit, Rotation (with binary rewards) and Jigsaw (with graded partial credit mitigating reward sparsity). To counter flat rewards and vanishing group-relative advantages, we introduce a difficulty-aware curriculum that dynamically weights samples and peaks at medium difficulty. We further monitor Reasoning-Answer Consistency (RAC) during post-training: mirroring reports for vanilla GRPO in LLMs, RAC typically rises early then degrades; our curriculum delays this decline, and consistency-enforcing reward schemes further boost RAC. RAC correlates with downstream accuracy. Across diverse benchmarks and on Qwen-7B and Qwen-3B backbones, PC-GRPO improves reasoning quality, training stability, and end-task accuracy, offering a practical path to scalable, verifiable, and interpretable RL post-training for VLMs.
Extending Video Masked Autoencoders to 128 frames
Nov 20, 2024



Video understanding has witnessed significant progress with recent video foundation models demonstrating strong performance owing to self-supervised pre-training objectives; Masked Autoencoders (MAE) being the design of choice. Nevertheless, the majority of prior works that leverage MAE pre-training have focused on relatively short video representations (16 / 32 frames in length) largely due to hardware memory and compute limitations that scale poorly with video length due to the dense memory-intensive self-attention decoding. One natural strategy to address these challenges is to subsample tokens to reconstruct during decoding (or decoder masking). In this work, we propose an effective strategy for prioritizing tokens which allows training on longer video sequences (128 frames) and gets better performance than, more typical, random and uniform masking strategies. The core of our approach is an adaptive decoder masking strategy that prioritizes the most important tokens and uses quantized tokens as reconstruction objectives. Our adaptive strategy leverages a powerful MAGVIT-based tokenizer that jointly learns the tokens and their priority. We validate our design choices through exhaustive ablations and observe improved performance of the resulting long-video (128 frames) encoders over short-video (32 frames) counterparts. With our long-video masked autoencoder (LVMAE) strategy, we surpass state-of-the-art on Diving48 by 3.9 points and EPIC-Kitchens-100 verb classification by 2.5 points while relying on a simple core architecture and video-only pre-training (unlike some of the prior works that require millions of labeled video-text pairs or specialized encoders).
M3T: Multi-Scale Memory Matching for Video Object Segmentation and Tracking
Dec 13, 2023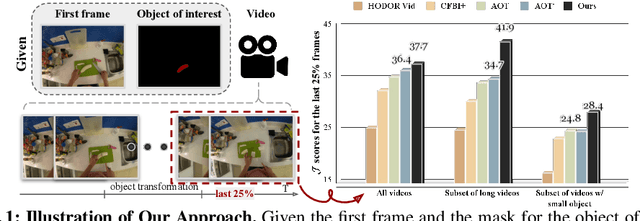

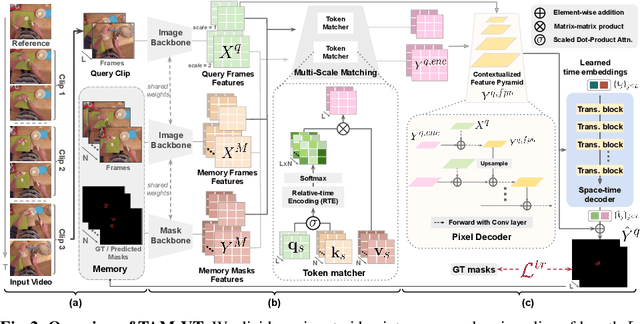
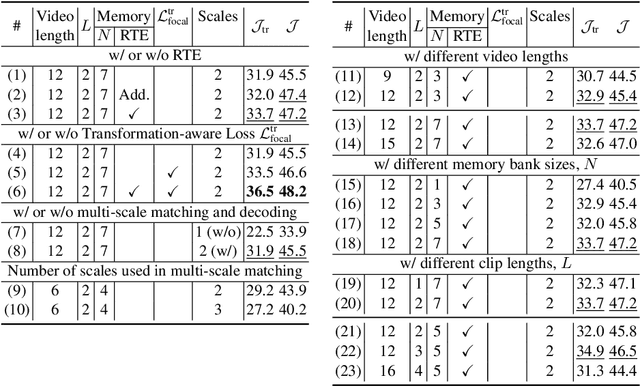
Video Object Segmentation (VOS) has became increasingly important with availability of larger datasets and more complex and realistic settings, which involve long videos with global motion (e.g, in egocentric settings), depicting small objects undergoing both rigid and non-rigid (including state) deformations. While a number of recent approaches have been explored for this task, these data characteristics still present challenges. In this work we propose a novel, DETR-style encoder-decoder architecture, which focuses on systematically analyzing and addressing aforementioned challenges. Specifically, our model enables on-line inference with long videos in a windowed fashion, by breaking the video into clips and propagating context among them using time-coded memory. We illustrate that short clip length and longer memory with learned time-coding are important design choices for achieving state-of-the-art (SoTA) performance. Further, we propose multi-scale matching and decoding to ensure sensitivity and accuracy for small objects. Finally, we propose a novel training strategy that focuses learning on portions of the video where an object undergoes significant deformations -- a form of "soft" hard-negative mining, implemented as loss-reweighting. Collectively, these technical contributions allow our model to achieve SoTA performance on two complex datasets -- VISOR and VOST. A series of detailed ablations validate our design choices as well as provide insights into the importance of parameter choices and their impact on performance.
MINOTAUR: Multi-task Video Grounding From Multimodal Queries
Feb 16, 2023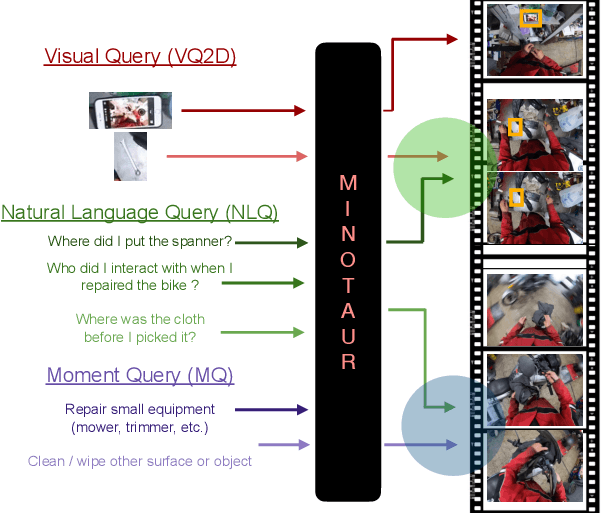

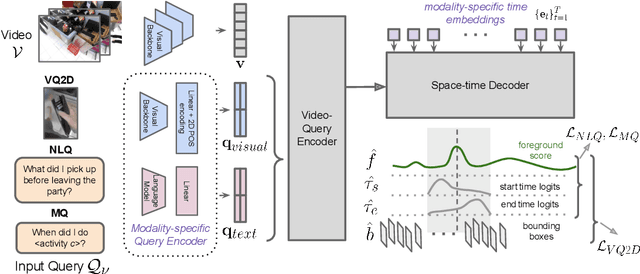
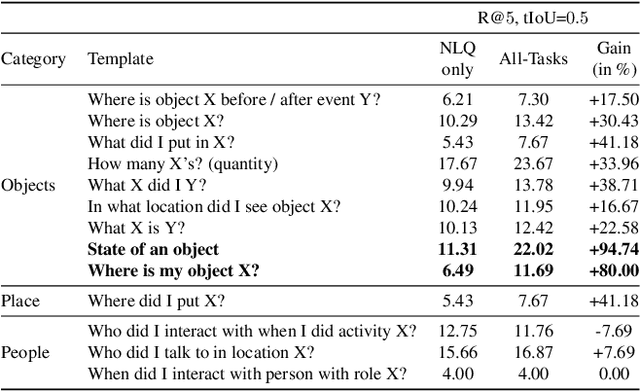
Video understanding tasks take many forms, from action detection to visual query localization and spatio-temporal grounding of sentences. These tasks differ in the type of inputs (only video, or video-query pair where query is an image region or sentence) and outputs (temporal segments or spatio-temporal tubes). However, at their core they require the same fundamental understanding of the video, i.e., the actors and objects in it, their actions and interactions. So far these tasks have been tackled in isolation with individual, highly specialized architectures, which do not exploit the interplay between tasks. In contrast, in this paper, we present a single, unified model for tackling query-based video understanding in long-form videos. In particular, our model can address all three tasks of the Ego4D Episodic Memory benchmark which entail queries of three different forms: given an egocentric video and a visual, textual or activity query, the goal is to determine when and where the answer can be seen within the video. Our model design is inspired by recent query-based approaches to spatio-temporal grounding, and contains modality-specific query encoders and task-specific sliding window inference that allow multi-task training with diverse input modalities and different structured outputs. We exhaustively analyze relationships among the tasks and illustrate that cross-task learning leads to improved performance on each individual task, as well as the ability to generalize to unseen tasks, such as zero-shot spatial localization of language queries.
Beyond Simple Meta-Learning: Multi-Purpose Models for Multi-Domain, Active and Continual Few-Shot Learning
Jan 13, 2022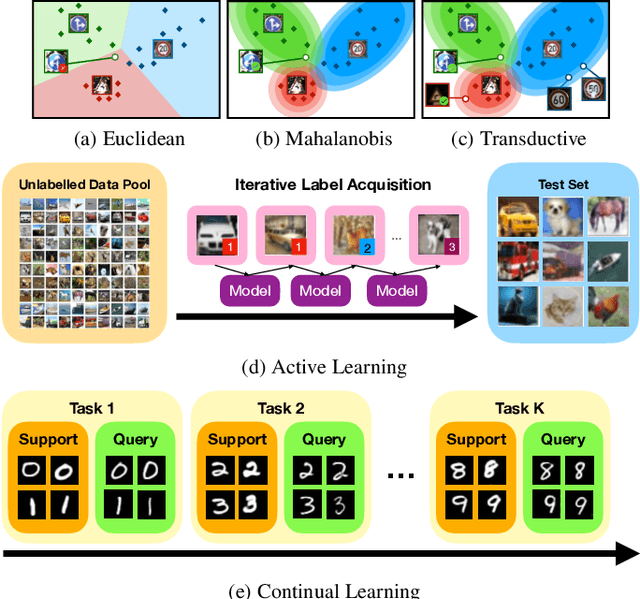
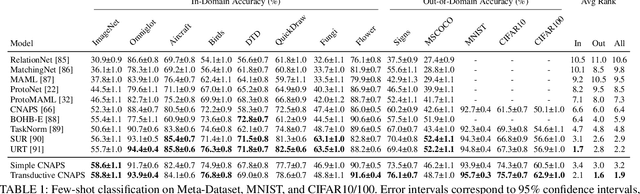
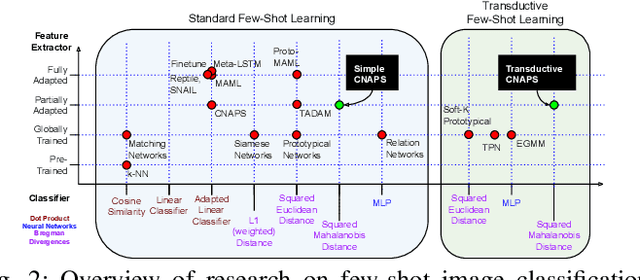
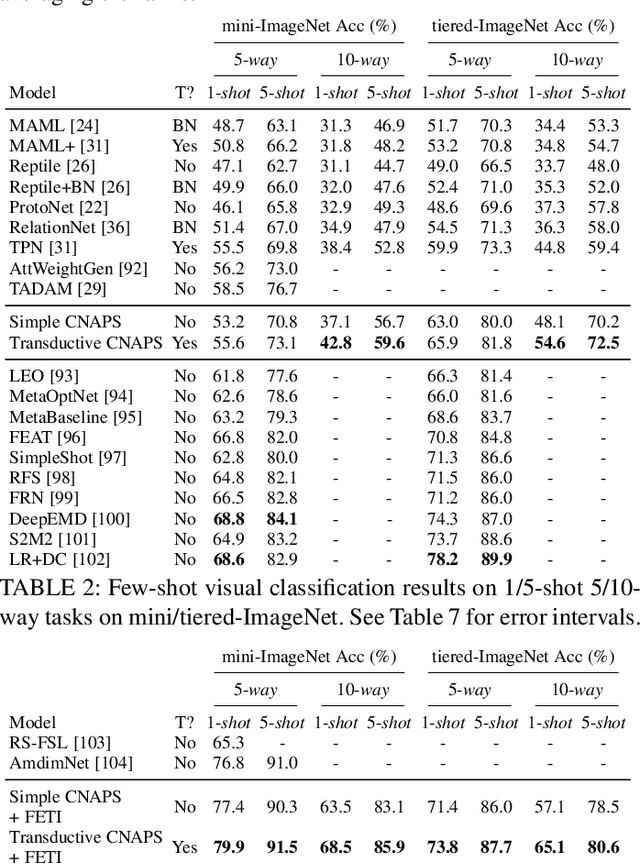
Modern deep learning requires large-scale extensively labelled datasets for training. Few-shot learning aims to alleviate this issue by learning effectively from few labelled examples. In previously proposed few-shot visual classifiers, it is assumed that the feature manifold, where classifier decisions are made, has uncorrelated feature dimensions and uniform feature variance. In this work, we focus on addressing the limitations arising from this assumption by proposing a variance-sensitive class of models that operates in a low-label regime. The first method, Simple CNAPS, employs a hierarchically regularized Mahalanobis-distance based classifier combined with a state of the art neural adaptive feature extractor to achieve strong performance on Meta-Dataset, mini-ImageNet and tiered-ImageNet benchmarks. We further extend this approach to a transductive learning setting, proposing Transductive CNAPS. This transductive method combines a soft k-means parameter refinement procedure with a two-step task encoder to achieve improved test-time classification accuracy using unlabelled data. Transductive CNAPS achieves state of the art performance on Meta-Dataset. Finally, we explore the use of our methods (Simple and Transductive) for "out of the box" continual and active learning. Extensive experiments on large scale benchmarks illustrate robustness and versatility of this, relatively speaking, simple class of models. All trained model checkpoints and corresponding source codes have been made publicly available.
Weakly-supervised Any-shot Object Detection
Jun 12, 2020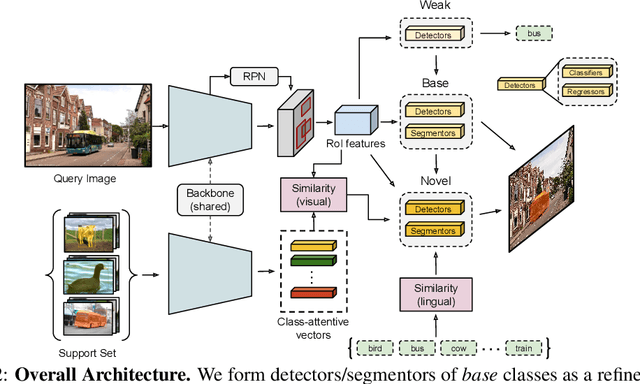
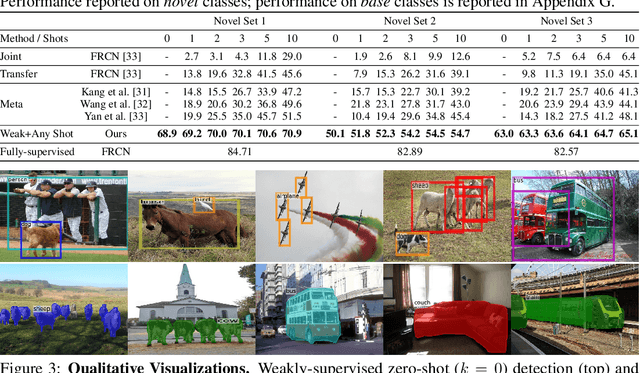
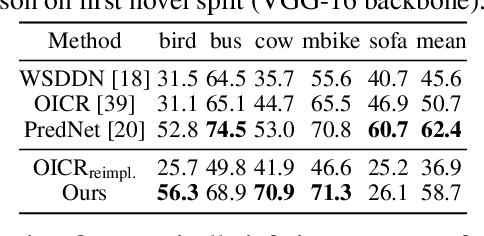
Methods for object detection and segmentation rely on large scale instance-level annotations for training, which are difficult and time-consuming to collect. Efforts to alleviate this look at varying degrees and quality of supervision. Weakly-supervised approaches draw on image-level labels to build detectors/segmentors, while zero/few-shot methods assume abundant instance-level data for a set of base classes, and none to a few examples for novel classes. This taxonomy has largely siloed algorithmic designs. In this work, we aim to bridge this divide by proposing an intuitive weakly-supervised model that is applicable to a range of supervision: from zero to a few instance-level samples per novel class. For base classes, our model learns a mapping from weakly-supervised to fully-supervised detectors/segmentors. By learning and leveraging visual and lingual similarities between the novel and base classes, we transfer those mappings to obtain detectors/segmentors for novel classes; refining them with a few novel class instance-level annotated samples, if available. The overall model is end-to-end trainable and highly flexible. Through extensive experiments on MS-COCO and Pascal VOC benchmark datasets we show improved performance in a variety of settings.
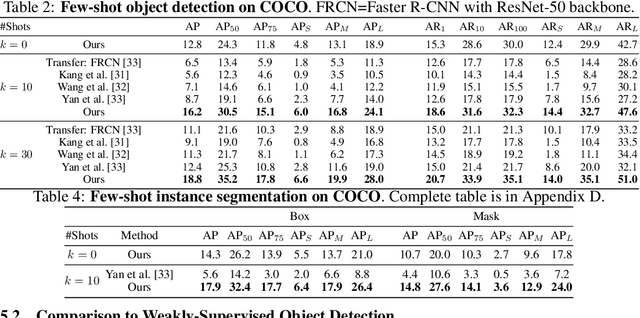
Ensemble based discriminative models for Visual Dialog Challenge 2018
Jan 15, 2020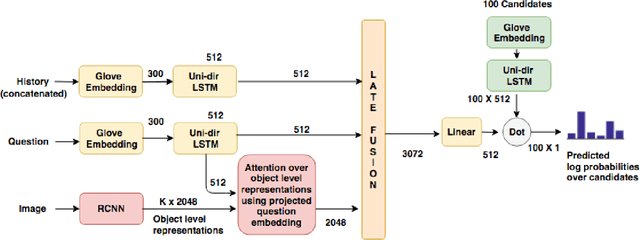

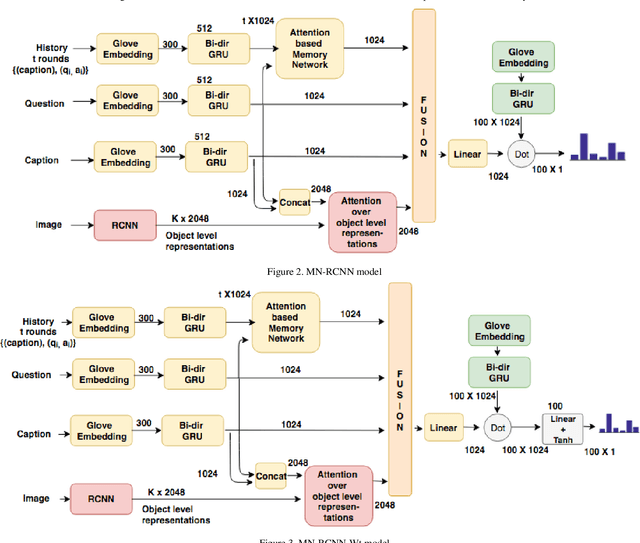
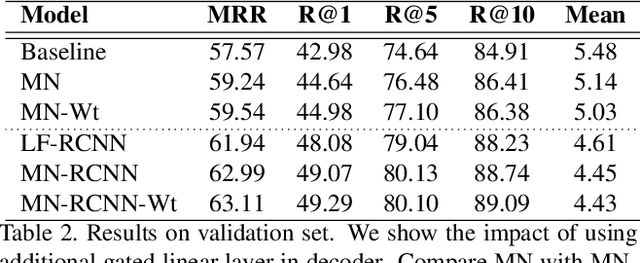
This manuscript describes our approach for the Visual Dialog Challenge 2018. We use an ensemble of three discriminative models with different encoders and decoders for our final submission. Our best performing model on 'test-std' split achieves the NDCG score of 55.46 and the MRR value of 63.77, securing third position in the challenge.
Improved Few-Shot Visual Classification
Dec 12, 2019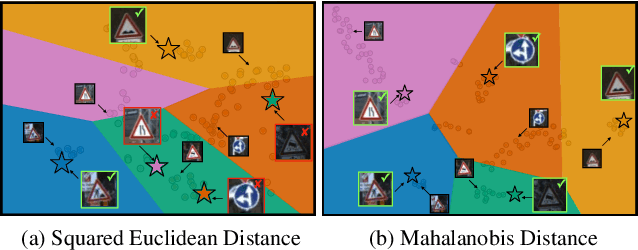

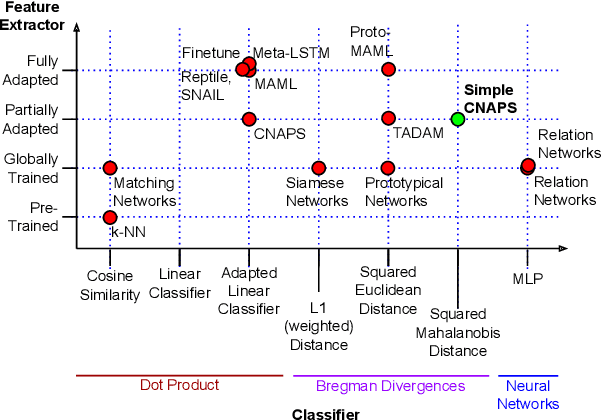

Few-shot learning is a fundamental task in computer vision that carries the promise of alleviating the need for exhaustively labeled data. Most few-shot learning approaches to date have focused on progressively more complex neural feature extractors and classifier adaptation strategies, as well as the refinement of the task definition itself. In this paper, we explore the hypothesis that a simple class-covariance-based distance metric, namely the Mahalanobis distance, adopted into a state of the art few-shot learning approach (CNAPS) can, in and of itself, lead to a significant performance improvement. We also discover that it is possible to learn adaptive feature extractors that allow useful estimation of the high dimensional feature covariances required by this metric from surprisingly few samples. The result of our work is a new "Simple CNAPS" architecture which has up to 9.2% fewer trainable parameters than CNAPS and performs up to 6.1% better than state of the art on the standard few-shot image classification benchmark dataset.
The "something something" video database for learning and evaluating visual common sense
Jun 15, 2017
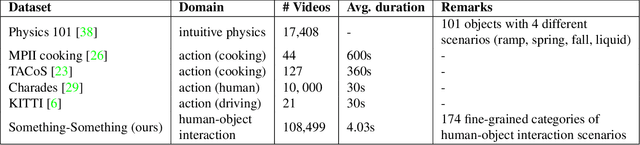

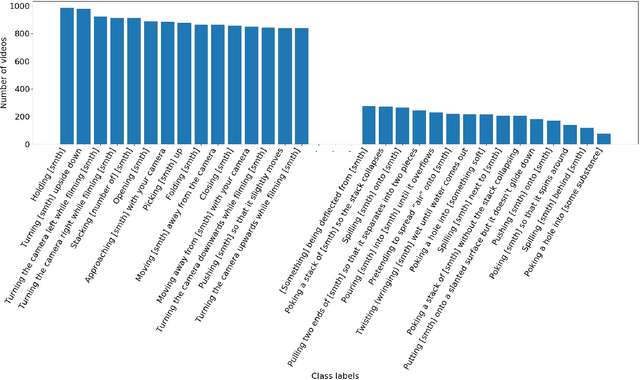
Neural networks trained on datasets such as ImageNet have led to major advances in visual object classification. One obstacle that prevents networks from reasoning more deeply about complex scenes and situations, and from integrating visual knowledge with natural language, like humans do, is their lack of common sense knowledge about the physical world. Videos, unlike still images, contain a wealth of detailed information about the physical world. However, most labelled video datasets represent high-level concepts rather than detailed physical aspects about actions and scenes. In this work, we describe our ongoing collection of the "something-something" database of video prediction tasks whose solutions require a common sense understanding of the depicted situation. The database currently contains more than 100,000 videos across 174 classes, which are defined as caption-templates. We also describe the challenges in crowd-sourcing this data at scale.