 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
Orthrus: Memory-Efficient Parallel Token Generation via Dual-View Diffusion
May 12, 2026We introduce Orthrus, a simple and efficient dual-architecture framework that unifies the exact generation fidelity of autoregressive Large Language Models (LLMs) with the high-speed parallel token generation of diffusion models. The sequential nature of standard autoregressive decoding represents a fundamental bottleneck for high-throughput inference. While diffusion language models attempt to break this barrier via parallel generation, they suffer from significant performance degradation, high training costs, and a lack of rigorous convergence guarantees. Orthrus resolves this dichotomy natively. Designed to seamlessly integrate into existing Transformers, the framework augments a frozen LLM with a lightweight, trainable module to create a parallel diffusion view alongside the standard autoregressive view. In this unified system, both views attend to the exact same high-fidelity Key-Value (KV) cache; the autoregressive head executes context pre-filling to construct accurate KV representations, while the diffusion head executes parallel generation. By employing an exact consensus mechanism between the two views, Orthrus guarantees lossless inference, delivering up to a 7.8x speedup with only an O(1) memory cache overhead and minimal parameter additions.
Extending Video Masked Autoencoders to 128 frames
Nov 20, 2024



Video understanding has witnessed significant progress with recent video foundation models demonstrating strong performance owing to self-supervised pre-training objectives; Masked Autoencoders (MAE) being the design of choice. Nevertheless, the majority of prior works that leverage MAE pre-training have focused on relatively short video representations (16 / 32 frames in length) largely due to hardware memory and compute limitations that scale poorly with video length due to the dense memory-intensive self-attention decoding. One natural strategy to address these challenges is to subsample tokens to reconstruct during decoding (or decoder masking). In this work, we propose an effective strategy for prioritizing tokens which allows training on longer video sequences (128 frames) and gets better performance than, more typical, random and uniform masking strategies. The core of our approach is an adaptive decoder masking strategy that prioritizes the most important tokens and uses quantized tokens as reconstruction objectives. Our adaptive strategy leverages a powerful MAGVIT-based tokenizer that jointly learns the tokens and their priority. We validate our design choices through exhaustive ablations and observe improved performance of the resulting long-video (128 frames) encoders over short-video (32 frames) counterparts. With our long-video masked autoencoder (LVMAE) strategy, we surpass state-of-the-art on Diving48 by 3.9 points and EPIC-Kitchens-100 verb classification by 2.5 points while relying on a simple core architecture and video-only pre-training (unlike some of the prior works that require millions of labeled video-text pairs or specialized encoders).
Feasibility of assessing cognitive impairment via distributed camera network and privacy-preserving edge computing
Aug 19, 2024INTRODUCTION: Mild cognitive impairment (MCI) is characterized by a decline in cognitive functions beyond typical age and education-related expectations. Since, MCI has been linked to reduced social interactions and increased aimless movements, we aimed to automate the capture of these behaviors to enhance longitudinal monitoring. METHODS: Using a privacy-preserving distributed camera network, we collected movement and social interaction data from groups of individuals with MCI undergoing therapy within a 1700$m^2$ space. We developed movement and social interaction features, which were then used to train a series of machine learning algorithms to distinguish between higher and lower cognitive functioning MCI groups. RESULTS: A Wilcoxon rank-sum test revealed statistically significant differences between high and low-functioning cohorts in features such as linear path length, walking speed, change in direction while walking, entropy of velocity and direction change, and number of group formations in the indoor space. Despite lacking individual identifiers to associate with specific levels of MCI, a machine learning approach using the most significant features provided a 71% accuracy. DISCUSSION: We provide evidence to show that a privacy-preserving low-cost camera network using edge computing framework has the potential to distinguish between different levels of cognitive impairment from the movements and social interactions captured during group activities.
Unsupervised Paraphrase Generation using Pre-trained Language Models
Jun 09, 2020
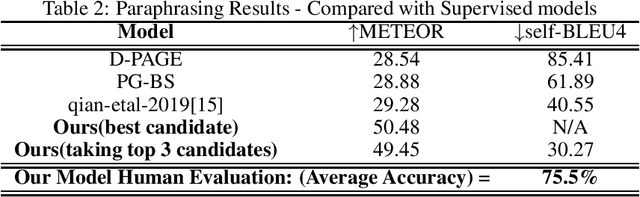
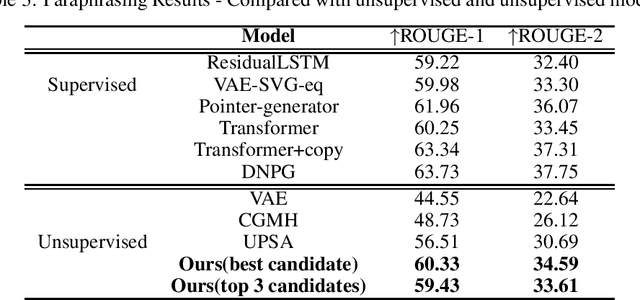

Large scale Pre-trained Language Models have proven to be very powerful approach in various Natural language tasks. OpenAI's GPT-2 \cite{radford2019language} is notable for its capability to generate fluent, well formulated, grammatically consistent text and for phrase completions. In this paper we leverage this generation capability of GPT-2 to generate paraphrases without any supervision from labelled data. We examine how the results compare with other supervised and unsupervised approaches and the effect of using paraphrases for data augmentation on downstream tasks such as classification. Our experiments show that paraphrases generated with our model are of good quality, are diverse and improves the downstream task performance when used for data augmentation.