 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Paraphrase Generation using Pre-trained Language Models
Jun 09, 2020
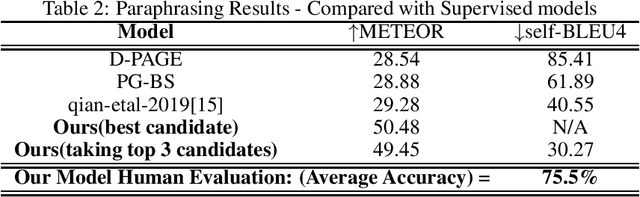
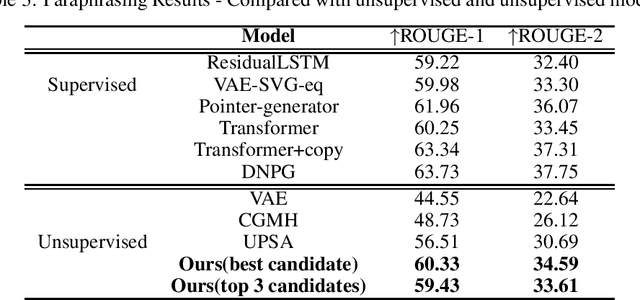

Large scale Pre-trained Language Models have proven to be very powerful approach in various Natural language tasks. OpenAI's GPT-2 \cite{radford2019language} is notable for its capability to generate fluent, well formulated, grammatically consistent text and for phrase completions. In this paper we leverage this generation capability of GPT-2 to generate paraphrases without any supervision from labelled data. We examine how the results compare with other supervised and unsupervised approaches and the effect of using paraphrases for data augmentation on downstream tasks such as classification. Our experiments show that paraphrases generated with our model are of good quality, are diverse and improves the downstream task performance when used for data augmentation.