 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARE-PD: A Multi-Site Anonymized Clinical Dataset for Parkinson's Disease Gait Assessment
Oct 05, 2025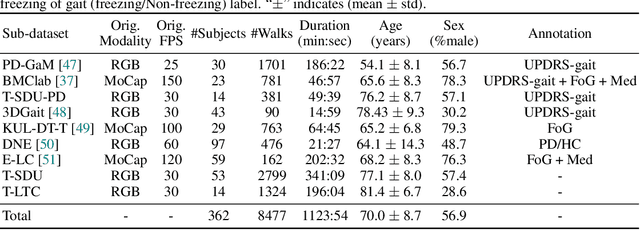
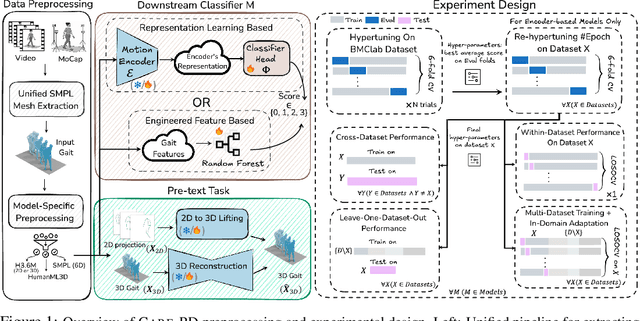
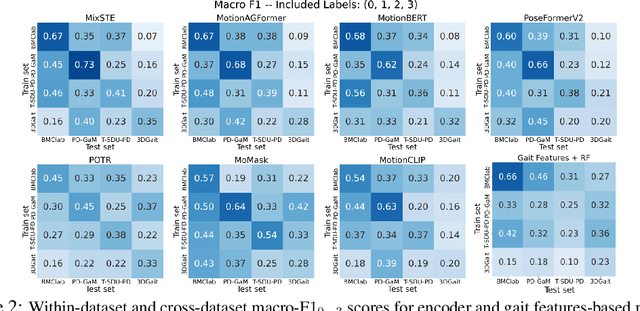
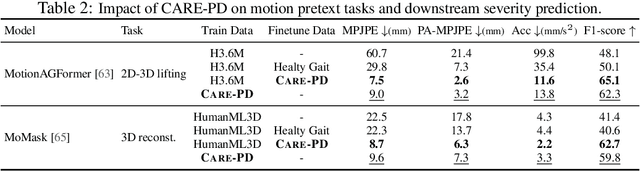
Objective gait assessment in Parkinson's Disease (PD) is limited by the absence of large, diverse, and clinically annotated motion datasets. We introduce CARE-PD, the largest publicly available archive of 3D mesh gait data for PD, and the first multi-site collection spanning 9 cohorts from 8 clinical centers. All recordings (RGB video or motion capture) are converted into anonymized SMPL meshes via a harmonized preprocessing pipeline. CARE-PD supports two key benchmarks: supervised clinical score prediction (estimating Unified Parkinson's Disease Rating Scale, UPDRS, gait scores) and unsupervised motion pretext tasks (2D-to-3D keypoint lifting and full-body 3D reconstruction). Clinical prediction is evaluated under four generalization protocols: within-dataset, cross-dataset, leave-one-dataset-out, and multi-dataset in-domain adaptation. To assess clinical relevance, we compare state-of-the-art motion encoders with a traditional gait-feature baseline, finding that encoders consistently outperform handcrafted features. Pretraining on CARE-PD reduces MPJPE (from 60.8mm to 7.5mm) and boosts PD severity macro-F1 by 17 percentage points, underscoring the value of clinically curated, diverse training data. CARE-PD and all benchmark code are released for non-commercial research at https://neurips2025.care-pd.ca/.
Detecting Cognitive Impairment and Psychological Well-being among Older Adults Using Facial, Acoustic, Linguistic, and Cardiovascular Patterns Derived from Remote Conversations
Dec 23, 2024



The aging society urgently requires scalable methods to monitor cognitive decline and identify social and psychological factors indicative of dementia risk in older adults. Our machine learning (ML) models captured facial, acoustic, linguistic, and cardiovascular features from 39 individuals with normal cognition or Mild Cognitive Impairment derived from remote video conversations and classified cognitive status, social isolation, neuroticism, and psychological well-being. Our model could distinguish Clinical Dementia Rating Scale (CDR) of 0.5 (vs. 0) with 0.78 area under the receiver operating characteristic curve (AUC), social isolation with 0.75 AUC, neuroticism with 0.71 AUC, and negative affect scales with 0.79 AUC. Recent advances in machine learning offer new opportunities to remotely detect cognitive impairment and assess associated factors, such as neuroticism and psychological well-being. Our experiment showed that speech and language patterns were more useful for quantifying cognitive impairment, whereas facial expression and cardiovascular patterns using photoplethysmography (PPG) were more useful for quantifying personality and psychological well-being.
Classifying Simulated Gait Impairments using Privacy-preserving Explainable Artificial Intelligence and Mobile Phone Videos
Dec 02, 2024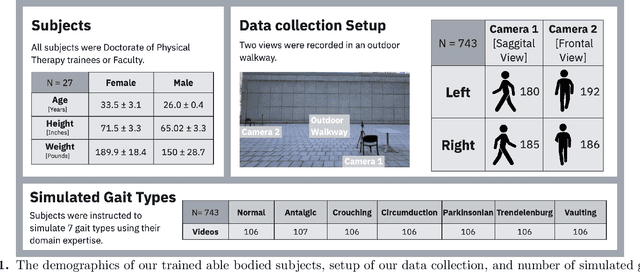


Accurate diagnosis of gait impairments is often hindered by subjective or costly assessment methods, with current solutions requiring either expensive multi-camera equipment or relying on subjective clinical observation. There is a critical need for accessible, objective tools that can aid in gait assessment while preserving patient privacy. In this work, we present a mobile phone-based, privacy-preserving artificial intelligence (AI) system for classifying gait impairments and introduce a novel dataset of 743 videos capturing seven distinct gait patterns. The dataset consists of frontal and sagittal views of trained subjects simulating normal gait and six types of pathological gait (circumduction, Trendelenburg, antalgic, crouch, Parkinsonian, and vaulting), recorded using standard mobile phone cameras. Our system achieved 86.5% accuracy using combined frontal and sagittal views, with sagittal views generally outperforming frontal views except for specific gait patterns like Circumduction. Model feature importance analysis revealed that frequency-domain features and entropy measures were critical for classifcation performance, specifically lower limb keypoints proved most important for classification, aligning with clinical understanding of gait assessment. These findings demonstrate that mobile phone-based systems can effectively classify diverse gait patterns while preserving privacy through on-device processing. The high accuracy achieved using simulated gait data suggests their potential for rapid prototyping of gait analysis systems, though clinical validation with patient data remains necessary. This work represents a significant step toward accessible, objective gait assessment tools for clinical, community, and tele-rehabilitation settings
Feasibility of assessing cognitive impairment via distributed camera network and privacy-preserving edge computing
Aug 19, 2024INTRODUCTION: Mild cognitive impairment (MCI) is characterized by a decline in cognitive functions beyond typical age and education-related expectations. Since, MCI has been linked to reduced social interactions and increased aimless movements, we aimed to automate the capture of these behaviors to enhance longitudinal monitoring. METHODS: Using a privacy-preserving distributed camera network, we collected movement and social interaction data from groups of individuals with MCI undergoing therapy within a 1700$m^2$ space. We developed movement and social interaction features, which were then used to train a series of machine learning algorithms to distinguish between higher and lower cognitive functioning MCI groups. RESULTS: A Wilcoxon rank-sum test revealed statistically significant differences between high and low-functioning cohorts in features such as linear path length, walking speed, change in direction while walking, entropy of velocity and direction change, and number of group formations in the indoor space. Despite lacking individual identifiers to associate with specific levels of MCI, a machine learning approach using the most significant features provided a 71% accuracy. DISCUSSION: We provide evidence to show that a privacy-preserving low-cost camera network using edge computing framework has the potential to distinguish between different levels of cognitive impairment from the movements and social interactions captured during group activities.
IMUGPT 2.0: Language-Based Cross Modality Transfer for Sensor-Based Human Activity Recognition
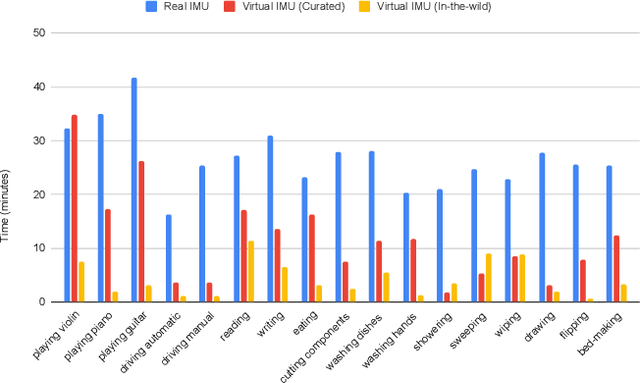
Feb 01, 2024One of the primary challenges in the field of human activity recognition (HAR) is the lack of large labeled datasets. This hinders the development of robust and generalizable models. Recently, cross modality transfer approaches have been explored that can alleviate the problem of data scarcity. These approaches convert existing datasets from a source modality, such as video, to a target modality (IMU). With the emergence of generative AI models such as large language models (LLMs) and text-driven motion synthesis models, language has become a promising source data modality as well as shown in proof of concepts such as IMUGPT. In this work, we conduct a large-scale evaluation of language-based cross modality transfer to determine their effectiveness for HAR. Based on this study, we introduce two new extensions for IMUGPT that enhance its use for practical HAR application scenarios: a motion filter capable of filtering out irrelevant motion sequences to ensure the relevance of the generated virtual IMU data, and a set of metrics that measure the diversity of the generated data facilitating the determination of when to stop generating virtual IMU data for both effective and efficient processing. We demonstrate that our diversity metrics can reduce the effort needed for the generation of virtual IMU data by at least 50%, which open up IMUGPT for practical use cases beyond a mere proof of concept.
On the Benefit of Generative Foundation Models for Human Activity Recognition
Oct 18, 2023In human activity recognition (HAR), the limited availability of annotated data presents a significant challenge. Drawing inspiration from the latest advancements in generative AI, including Large Language Models (LLMs) and motion synthesis models, we believe that generative AI can address this data scarcity by autonomously generating virtual IMU data from text descriptions. Beyond this, we spotlight several promising research pathways that could benefit from generative AI for the community, including the generating benchmark datasets, the development of foundational models specific to HAR, the exploration of hierarchical structures within HAR, breaking down complex activities, and applications in health sensing and activity summarization.
Indoor Localization and Multi-person Tracking Using Privacy Preserving Distributed Camera Network with Edge Computing
May 08, 2023



Localization of individuals in a built environment is a growing research topic. Estimating the positions, face orientation (or gaze direction) and trajectories of people through space has many uses, such as in crowd management, security, and healthcare. In this work, we present an open-source, low-cost, scalable and privacy-preserving edge computing framework for multi-person localization, i.e. estimating the positions, orientations, and trajectories of multiple people in an indoor space. Our computing framework consists of 38 Tensor Processing Unit (TPU)-enabled edge computing camera systems placed in the ceiling of the indoor therapeutic space. The edge compute systems are connected to an on-premise fog server through a secure and private network. A multi-person detection algorithm and a pose estimation model run on the edge TPU in real-time to collect features which are used, instead of raw images, for downstream computations. This ensures the privacy of individuals in the space, reduces data transmission/storage and improves scalability. We implemented a Kalman filter-based multi-person tracking method and a state-of-the-art body orientation estimation method to determine the positions and facing orientations of multiple people simultaneously in the indoor space. For our study site with size of 18,000 square feet, our system demonstrated an average localization error of 1.41 meters, a multiple-object tracking accuracy score of 62%, and a mean absolute body orientation error of 29{\deg}, which is sufficient for understanding group activity behaviors in indoor environments. Additionally, our study provides practical guidance for deploying the proposed system by analyzing various elements of the camera installation with respect to tracking accuracy.
Generating Virtual On-body Accelerometer Data from Virtual Textual Descriptions for Human Activity Recognition
May 04, 2023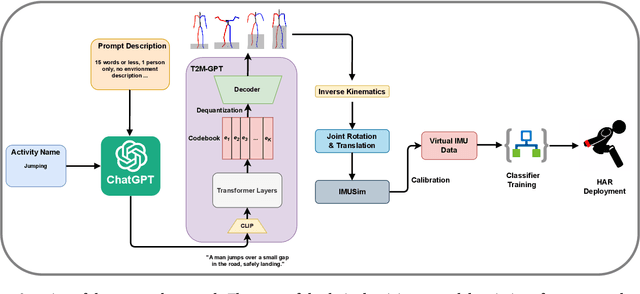
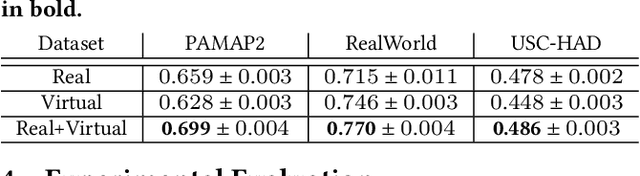
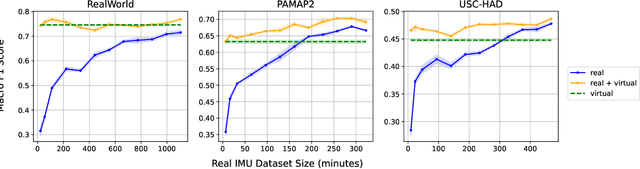
The development of robust, generalized models in human activity recognition (HAR) has been hindered by the scarcity of large-scale, labeled data sets. Recent work has shown that virtual IMU data extracted from videos using computer vision techniques can lead to substantial performance improvements when training HAR models combined with small portions of real IMU data. Inspired by recent advances in motion synthesis from textual descriptions and connecting Large Language Models (LLMs) to various AI models, we introduce an automated pipeline that first uses ChatGPT to generate diverse textual descriptions of activities. These textual descriptions are then used to generate 3D human motion sequences via a motion synthesis model, T2M-GPT, and later converted to streams of virtual IMU data. We benchmarked our approach on three HAR datasets (RealWorld, PAMAP2, and USC-HAD) and demonstrate that the use of virtual IMU training data generated using our new approach leads to significantly improved HAR model performance compared to only using real IMU data. Our approach contributes to the growing field of cross-modality transfer methods and illustrate how HAR models can be improved through the generation of virtual training data that do not require any manual effort.
Fine-grained Human Activity Recognition Using Virtual On-body Acceleration Data
Nov 02, 2022
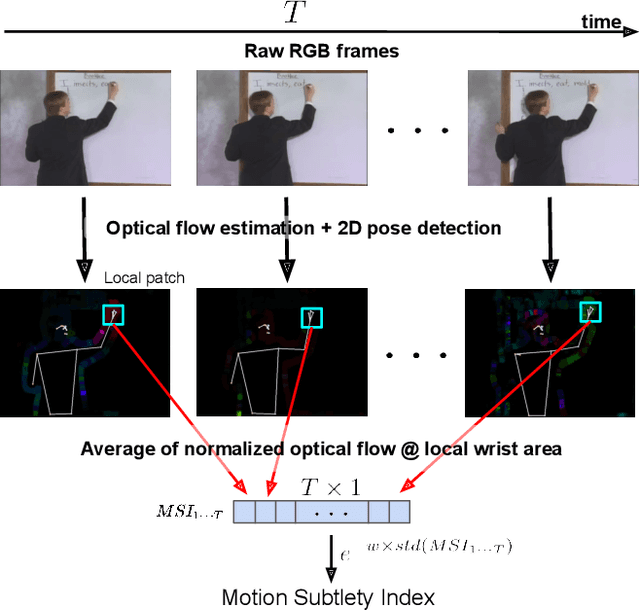

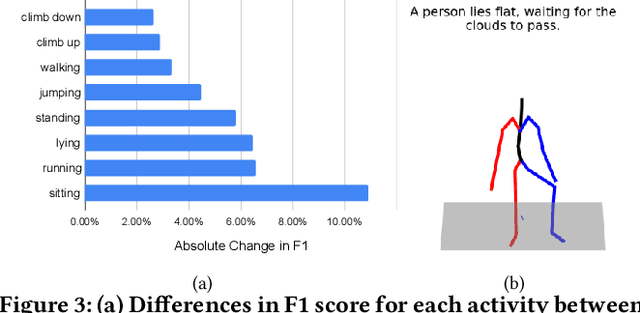
Previous work has demonstrated that virtual accelerometry data, extracted from videos using cross-modality transfer approaches like IMUTube, is beneficial for training complex and effective human activity recognition (HAR) models. Systems like IMUTube were originally designed to cover activities that are based on substantial body (part) movements. Yet, life is complex, and a range of activities of daily living is based on only rather subtle movements, which bears the question to what extent systems like IMUTube are of value also for fine-grained HAR, i.e., When does IMUTube break? In this work we first introduce a measure to quantitatively assess the subtlety of human movements that are underlying activities of interest--the motion subtlety index (MSI)--which captures local pixel movements and pose changes in the vicinity of target virtual sensor locations, and correlate it to the eventual activity recognition accuracy. We then perform a "stress-test" on IMUTube and explore for which activities with underlying subtle movements a cross-modality transfer approach works, and for which not. As such, the work presented in this paper allows us to map out the landscape for IMUTube applications in practical scenarios.
IMUTube: Automatic extraction of virtual on-body accelerometry from video for human activity recognition
May 29, 2020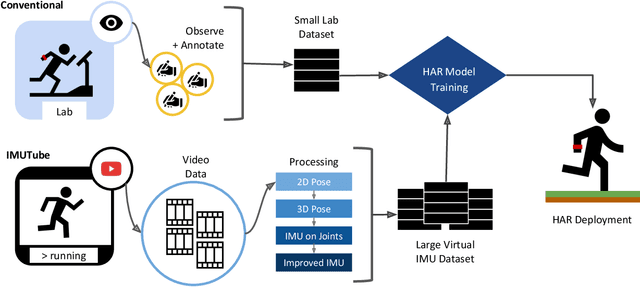

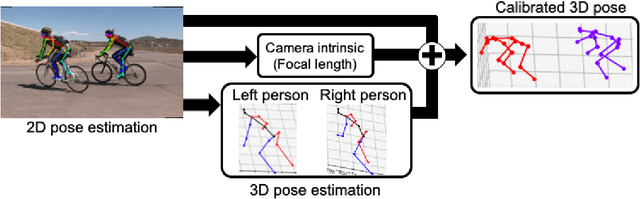

The lack of large-scale, labeled data sets impedes progress in developing robust and generalized predictive models for on-body sensor-based human activity recognition (HAR). Labeled data in human activity recognition is scarce and hard to come by, as sensor data collection is expensive, and the annotation is time-consuming and error-prone. To address this problem, we introduce IMUTube, an automated processing pipeline that integrates existing computer vision and signal processing techniques to convert videos of human activity into virtual streams of IMU data. These virtual IMU streams represent accelerometry at a wide variety of locations on the human body. We show how the virtually-generated IMU data improves the performance of a variety of models on known HAR datasets. Our initial results are very promising, but the greater promise of this work lies in a collective approach by the computer vision, signal processing, and activity recognition communities to extend this work in ways that we outline. This should lead to on-body, sensor-based HAR becoming yet another success story in large-dataset breakthroughs in recognition.