 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Virtual On-body Accelerometer Data from Virtual Textual Descriptions for Human Activity Recognition
Paper and Code
May 04, 2023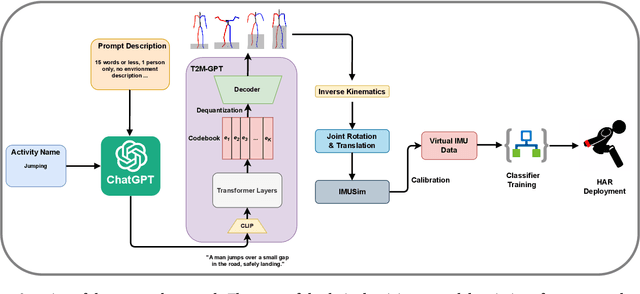
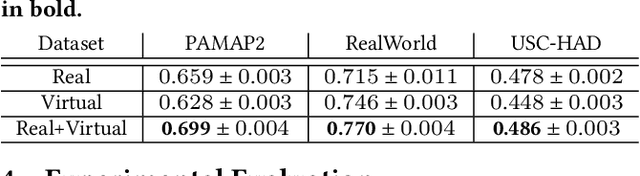
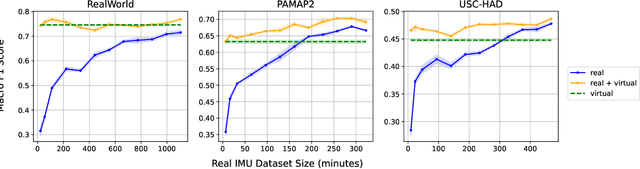
The development of robust, generalized models in human activity recognition (HAR) has been hindered by the scarcity of large-scale, labeled data sets. Recent work has shown that virtual IMU data extracted from videos using computer vision techniques can lead to substantial performance improvements when training HAR models combined with small portions of real IMU data. Inspired by recent advances in motion synthesis from textual descriptions and connecting Large Language Models (LLMs) to various AI models, we introduce an automated pipeline that first uses ChatGPT to generate diverse textual descriptions of activities. These textual descriptions are then used to generate 3D human motion sequences via a motion synthesis model, T2M-GPT, and later converted to streams of virtual IMU data. We benchmarked our approach on three HAR datasets (RealWorld, PAMAP2, and USC-HAD) and demonstrate that the use of virtual IMU training data generated using our new approach leads to significantly improved HAR model performance compared to only using real IMU data. Our approach contributes to the growing field of cross-modality transfer methods and illustrate how HAR models can be improved through the generation of virtual training data that do not require any manual effort.