 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Cognitive Impairment and Psychological Well-being among Older Adults Using Facial, Acoustic, Linguistic, and Cardiovascular Patterns Derived from Remote Conversations
Dec 23, 2024



The aging society urgently requires scalable methods to monitor cognitive decline and identify social and psychological factors indicative of dementia risk in older adults. Our machine learning (ML) models captured facial, acoustic, linguistic, and cardiovascular features from 39 individuals with normal cognition or Mild Cognitive Impairment derived from remote video conversations and classified cognitive status, social isolation, neuroticism, and psychological well-being. Our model could distinguish Clinical Dementia Rating Scale (CDR) of 0.5 (vs. 0) with 0.78 area under the receiver operating characteristic curve (AUC), social isolation with 0.75 AUC, neuroticism with 0.71 AUC, and negative affect scales with 0.79 AUC. Recent advances in machine learning offer new opportunities to remotely detect cognitive impairment and assess associated factors, such as neuroticism and psychological well-being. Our experiment showed that speech and language patterns were more useful for quantifying cognitive impairment, whereas facial expression and cardiovascular patterns using photoplethysmography (PPG) were more useful for quantifying personality and psychological well-being.
An End-to-End Neural Network for Image-to-Audio Transformation
Mar 10, 2023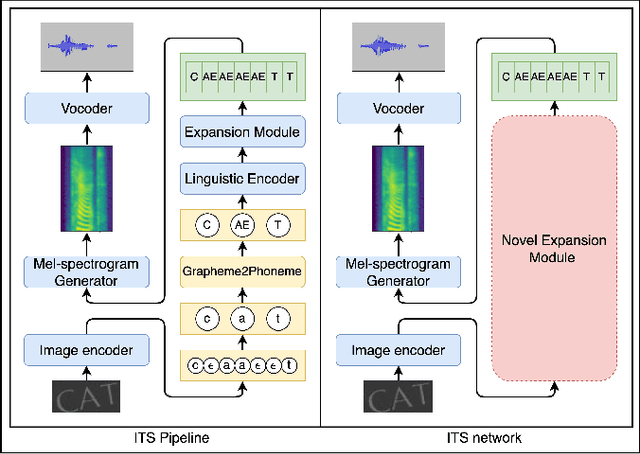
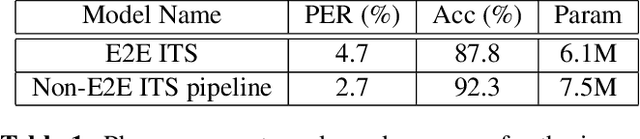
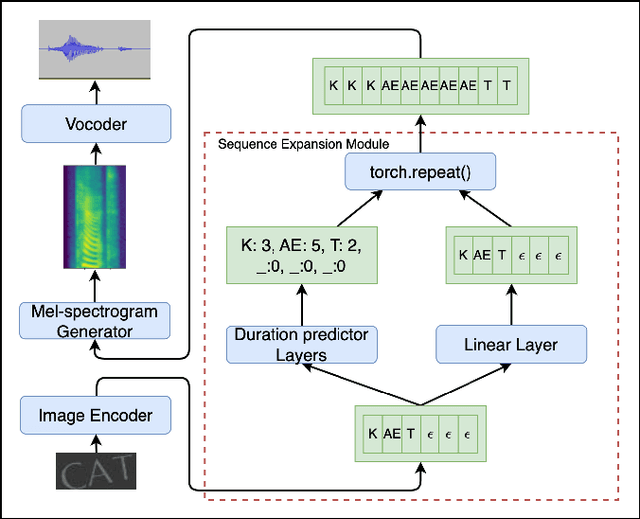
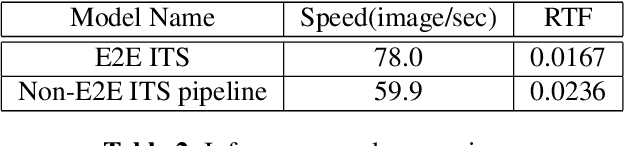
This paper describes an end-to-end (E2E) neural architecture for the audio rendering of small portions of display content on low resource personal computing devices. It is intended to address the problem of accessibility for vision-impaired or vision-distracted users at the hardware level. Neural image-to-text (ITT) and text-to-speech (TTS) approaches are reviewed and a new technique is introduced to efficiently integrate them in a way that is both efficient and back-propagate-able, leading to a non-autoregressive E2E image-to-speech (ITS) neural network that is efficient and trainable. Experimental results are presented showing that, compared with the non-E2E approach, the proposed E2E system is 29% faster and uses 19% fewer parameters with a 2% reduction in phone accuracy. A future direction to address accuracy is presented.
Interpreting A Pre-trained Model Is A Key For Model Architecture Optimization: A Case Study On Wav2Vec 2.0
Apr 07, 2021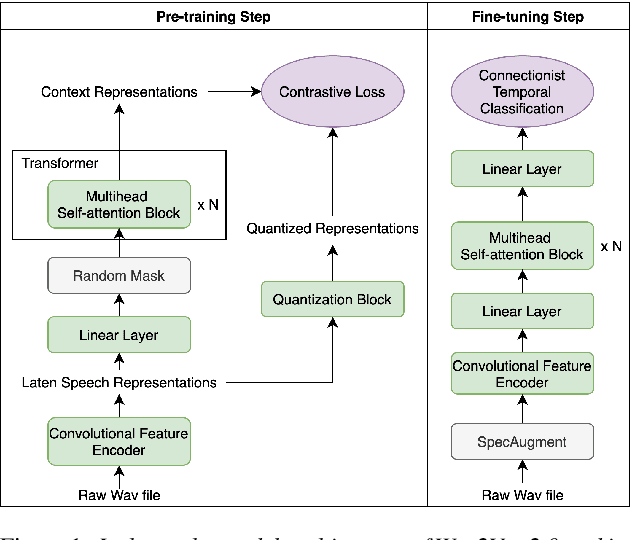
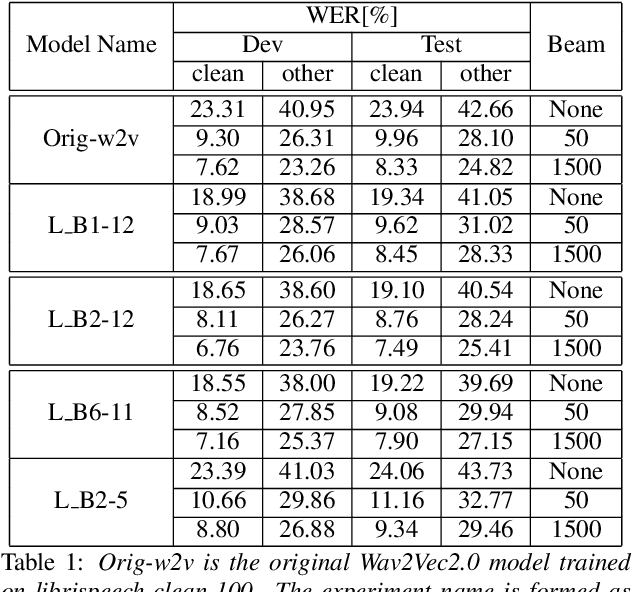
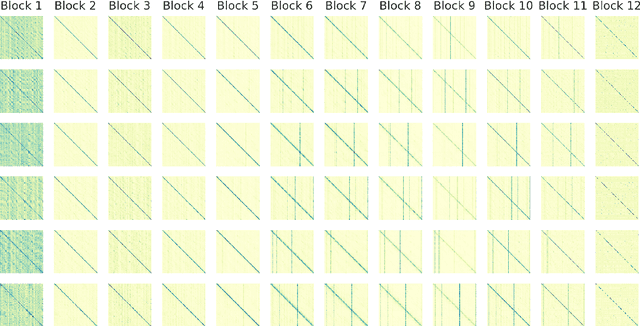
A deep Transformer model with good evaluation score does not mean each subnetwork (a.k.a transformer block) learns reasonable representation. Diagnosing abnormal representation and avoiding it can contribute to achieving a better evaluation score. We propose an innovative perspective for analyzing attention patterns: summarize block-level patterns and assume abnormal patterns contribute negative influence. We leverage Wav2Vec 2.0 as a research target and analyze a pre-trained model's pattern. All experiments leverage Librispeech-100-clean as training data. Through avoiding diagnosed abnormal ones, our custom Wav2Vec 2.0 outperforms the original version about 4.8% absolute word error rate (WER) on test-clean with viterbi decoding. Our version is still 0.9% better when decoding with a 4-gram language model. Moreover, we identify that avoiding abnormal patterns is the main contributor for performance boosting.
Refining Automatic Speech Recognition System for older adults
Nov 17, 2020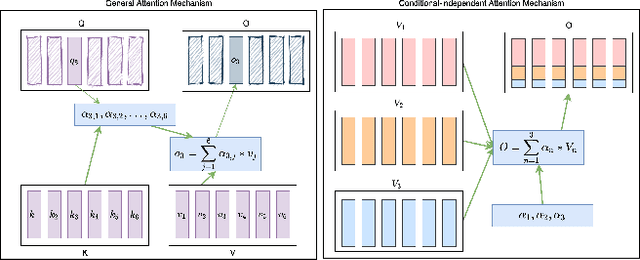
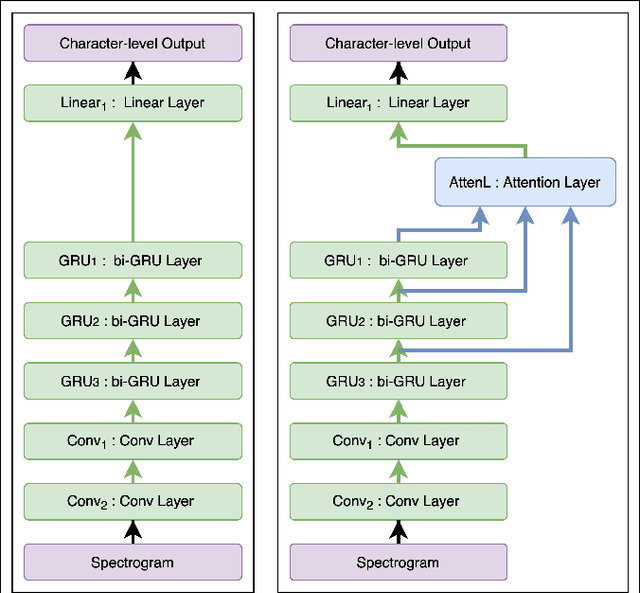
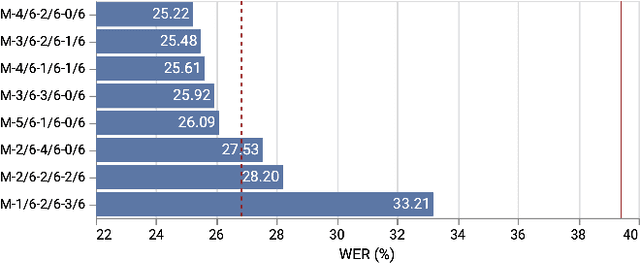
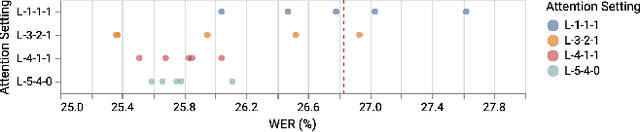
Building a high quality automatic speech recognition (ASR) system with limited training data has been a challenging task particularly for a narrow target population. Open-sourced ASR systems, trained on sufficient data from adults, are susceptible on seniors' speech due to acoustic mismatch between adults and seniors. With 12 hours of training data, we attempt to develop an ASR system for socially isolated seniors (80+ years old) with possible cognitive impairments. We experimentally identify that ASR for the adult population performs poorly on our target population and transfer learning (TL) can boost the system's performance. Standing on the fundamental idea of TL, tuning model parameters, we further improve the system by leveraging an attention mechanism to utilize the model's intermediate information. Our approach achieves 1.58% absolute improvements over the TL model.