 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Chagas Disease from the ECG: The George B. Moody PhysioNet Challenge 2025
Oct 02, 2025Objective: Chagas disease is a parasitic infection that is endemic to South America, Central America, and, more recently, the U.S., primarily transmitted by insects. Chronic Chagas disease can cause cardiovascular diseases and digestive problems. Serological testing capacities for Chagas disease are limited, but Chagas cardiomyopathy often manifests in ECGs, providing an opportunity to prioritize patients for testing and treatment. Approach: The George B. Moody PhysioNet Challenge 2025 invites teams to develop algorithmic approaches for identifying Chagas disease from electrocardiograms (ECGs). Main results: This Challenge provides multiple innovations. First, we leveraged several datasets with labels from patient reports and serological testing, provided a large dataset with weak labels and smaller datasets with strong labels. Second, we augmented the data to support model robustness and generalizability to unseen data sources. Third, we applied an evaluation metric that captured the local serological testing capacity for Chagas disease to frame the machine learning problem as a triage task. Significance: Over 630 participants from 111 teams submitted over 1300 entries during the Challenge, representing diverse approaches from academia and industry worldwide.
Cross-Learning Between ECG and PCG: Exploring Common and Exclusive Characteristics of Bimodal Electromechanical Cardiac Waveforms
Jun 11, 2025Simultaneous electrocardiography (ECG) and phonocardiogram (PCG) provide a comprehensive, multimodal perspective on cardiac function by capturing the heart's electrical and mechanical activities, respectively. However, the distinct and overlapping information content of these signals, as well as their potential for mutual reconstruction and biomarker extraction, remains incompletely understood, especially under varying physiological conditions and across individuals. In this study, we systematically investigate the common and exclusive characteristics of ECG and PCG using the EPHNOGRAM dataset of simultaneous ECG-PCG recordings during rest and exercise. We employ a suite of linear and nonlinear machine learning models, including non-causal LSTM networks, to reconstruct each modality from the other and analyze the influence of causality, physiological state, and cross-subject variability. Our results demonstrate that nonlinear models, particularly non-causal LSTM, provide superior reconstruction performance, with reconstructing ECG from PCG proving more tractable than the reverse. Exercise and cross-subject scenarios present significant challenges, but envelope-based modeling that utilizes instantaneous amplitude features substantially improves cross-subject generalizability for cross-modal learning. Furthermore, we demonstrate that clinically relevant ECG biomarkers, such as fiducial points and QT intervals, can be estimated from PCG in cross-subject settings. These findings advance our understanding of the relationship between electromechanical cardiac modalities, in terms of both waveform characteristics and the timing of cardiac events, with potential applications in novel multimodal cardiac monitoring technologies.
Auto-FEDUS: Autoregressive Generative Modeling of Doppler Ultrasound Signals from Fetal Electrocardiograms
Apr 17, 2025Fetal health monitoring through one-dimensional Doppler ultrasound (DUS) signals offers a cost-effective and accessible approach that is increasingly gaining interest. Despite its potential, the development of machine learning based techniques to assess the health condition of mothers and fetuses using DUS signals remains limited. This scarcity is primarily due to the lack of extensive DUS datasets with a reliable reference for interpretation and data imbalance across different gestational ages. In response, we introduce a novel autoregressive generative model designed to map fetal electrocardiogram (FECG) signals to corresponding DUS waveforms (Auto-FEDUS). By leveraging a neural temporal network based on dilated causal convolutions that operate directly on the waveform level, the model effectively captures both short and long-range dependencies within the signals, preserving the integrity of generated data. Cross-subject experiments demonstrate that Auto-FEDUS outperforms conventional generative architectures across both time and frequency domain evaluations, producing DUS signals that closely resemble the morphology of their real counterparts. The realism of these synthesized signals was further gauged using a quality assessment model, which classified all as good quality, and a heart rate estimation model, which produced comparable results for generated and real data, with a Bland-Altman limit of 4.5 beats per minute. This advancement offers a promising solution for mitigating limited data availability and enhancing the training of DUS-based fetal models, making them more effective and generalizable.
Edge AI for Real-time Fetal Assessment in Rural Guatemala
Mar 12, 2025Perinatal complications, defined as conditions that arise during pregnancy, childbirth, and the immediate postpartum period, represent a significant burden on maternal and neonatal health worldwide. Factors contributing to these disparities include limited access to quality healthcare, socioeconomic inequalities, and variations in healthcare infrastructure. Addressing these issues is crucial for improving health outcomes for mothers and newborns, particularly in underserved communities. To mitigate these challenges, we have developed an AI-enabled smartphone application designed to provide decision support at the point-of-care. This tool aims to enhance health monitoring during pregnancy by leveraging machine learning (ML) techniques. The intended use of this application is to assist midwives during routine home visits by offering real-time analysis and providing feedback based on collected data. The application integrates TensorFlow Lite (TFLite) and other Python-based algorithms within a Kotlin framework to process data in real-time. It is designed for use in low-resource settings, where traditional healthcare infrastructure may be lacking. The intended patient population includes pregnant women and new mothers in underserved areas and the developed system was piloted in rural Guatemala. This ML-based solution addresses the critical need for accessible and quality perinatal care by empowering healthcare providers with decision support tools to improve maternal and neonatal health outcomes.
Detecting Cognitive Impairment and Psychological Well-being among Older Adults Using Facial, Acoustic, Linguistic, and Cardiovascular Patterns Derived from Remote Conversations
Dec 23, 2024



The aging society urgently requires scalable methods to monitor cognitive decline and identify social and psychological factors indicative of dementia risk in older adults. Our machine learning (ML) models captured facial, acoustic, linguistic, and cardiovascular features from 39 individuals with normal cognition or Mild Cognitive Impairment derived from remote video conversations and classified cognitive status, social isolation, neuroticism, and psychological well-being. Our model could distinguish Clinical Dementia Rating Scale (CDR) of 0.5 (vs. 0) with 0.78 area under the receiver operating characteristic curve (AUC), social isolation with 0.75 AUC, neuroticism with 0.71 AUC, and negative affect scales with 0.79 AUC. Recent advances in machine learning offer new opportunities to remotely detect cognitive impairment and assess associated factors, such as neuroticism and psychological well-being. Our experiment showed that speech and language patterns were more useful for quantifying cognitive impairment, whereas facial expression and cardiovascular patterns using photoplethysmography (PPG) were more useful for quantifying personality and psychological well-being.
Electromechanical Dynamics of the Heart: A Study of Cardiac Hysteresis During Physical Stress Test
Oct 25, 2024

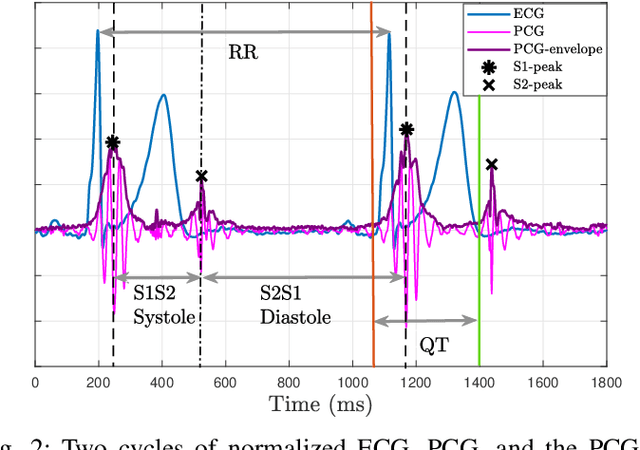

Cardiovascular diseases are best diagnosed using multiple modalities that assess both the heart's electrical and mechanical functions. While effective, imaging techniques like echocardiography and nuclear imaging are costly and not widely accessible. More affordable technologies, such as simultaneous electrocardiography (ECG) and phonocardiography (PCG), may provide valuable insights into electromechanical coupling and could be useful for prescreening in low-resource settings. Using physical stress test data from the EPHNOGRAM ECG-PCG dataset, collected from 23 healthy male subjects (age: 25.4+/-1.9 yrs), we investigated electromechanical intervals (RR, QT, systolic, and diastolic) and their interactions during exercise, along with hysteresis between cardiac electrical activity and mechanical responses. Time delay analysis revealed distinct temporal relationships between QT, systolic, and diastolic intervals, with RR as the primary driver. The diastolic interval showed near-synchrony with RR, while QT responded to RR interval changes with an average delay of 10.5s, and the systolic interval responded more slowly, with an average delay of 28.3s. We examined QT-RR, systolic-RR, and diastolic-RR hysteresis, finding narrower loops for diastolic RR and wider loops for systolic RR. Significant correlations (average:0.75) were found between heart rate changes and hysteresis loop areas, suggesting the equivalent circular area diameter as a promising biomarker for cardiac function under exercise stress. Deep learning models, including Long Short-Term Memory and Convolutional Neural Networks, estimated the QT, systolic, and diastolic intervals from RR data, confirming the nonlinear relationship between RR and other intervals. Findings highlight a significant cardiac memory effect, linking ECG and PCG morphology and timing to heart rate history.
ECG-Image-Database: A Dataset of ECG Images with Real-World Imaging and Scanning Artifacts; A Foundation for Computerized ECG Image Digitization and Analysis
Sep 25, 2024

We introduce the ECG-Image-Database, a large and diverse collection of electrocardiogram (ECG) images generated from ECG time-series data, with real-world scanning, imaging, and physical artifacts. We used ECG-Image-Kit, an open-source Python toolkit, to generate realistic images of 12-lead ECG printouts from raw ECG time-series. The images include realistic distortions such as noise, wrinkles, stains, and perspective shifts, generated both digitally and physically. The toolkit was applied to 977 12-lead ECG records from the PTB-XL database and 1,000 from Emory Healthcare to create high-fidelity synthetic ECG images. These unique images were subjected to both programmatic distortions using ECG-Image-Kit and physical effects like soaking, staining, and mold growth, followed by scanning and photography under various lighting conditions to create real-world artifacts. The resulting dataset includes 35,595 software-labeled ECG images with a wide range of imaging artifacts and distortions. The dataset provides ground truth time-series data alongside the images, offering a reference for developing machine and deep learning models for ECG digitization and classification. The images vary in quality, from clear scans of clean papers to noisy photographs of degraded papers, enabling the development of more generalizable digitization algorithms. ECG-Image-Database addresses a critical need for digitizing paper-based and non-digital ECGs for computerized analysis, providing a foundation for developing robust machine and deep learning models capable of converting ECG images into time-series. The dataset aims to serve as a reference for ECG digitization and computerized annotation efforts. ECG-Image-Database was used in the PhysioNet Challenge 2024 on ECG image digitization and classification.
Benchmarking changepoint detection algorithms on cardiac time series
Apr 16, 2024
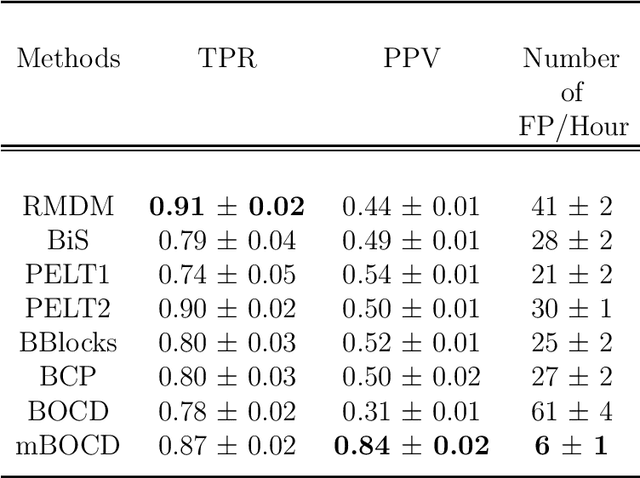

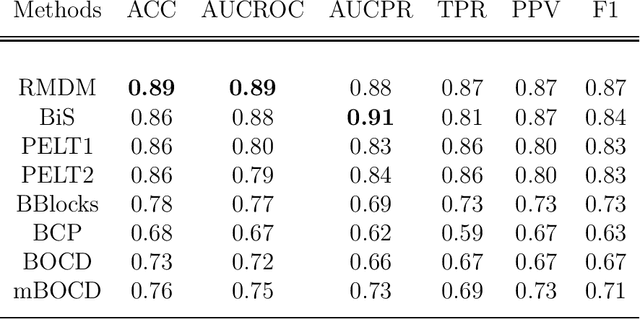
The pattern of state changes in a biomedical time series can be related to health or disease. This work presents a principled approach for selecting a changepoint detection algorithm for a specific task, such as disease classification. Eight key algorithms were compared, and the performance of each algorithm was evaluated as a function of temporal tolerance, noise, and abnormal conduction (ectopy) on realistic artificial cardiovascular time series data. All algorithms were applied to real data (cardiac time series of 22 patients with REM-behavior disorder (RBD) and 15 healthy controls) using the parameters selected on artificial data. Finally, features were derived from the detected changepoints to classify RBD patients from healthy controls using a K-Nearest Neighbors approach. On artificial data, Modified Bayesian Changepoint Detection algorithm provided superior positive predictive value for state change identification while Recursive Mean Difference Maximization (RMDM) achieved the highest true positive rate. For the classification task, features derived from the RMDM algorithm provided the highest leave one out cross validated accuracy of 0.89 and true positive rate of 0.87. Automatically detected changepoints provide useful information about subject's physiological state which cannot be directly observed. However, the choice of change point detection algorithm depends on the nature of the underlying data and the downstream application, such as a classification task. This work represents the first time change point detection algorithms have been compared in a meaningful way and utilized in a classification task, which demonstrates the effect of changepoint algorithm choice on application performance.
Indoor Localization and Multi-person Tracking Using Privacy Preserving Distributed Camera Network with Edge Computing
May 08, 2023



Localization of individuals in a built environment is a growing research topic. Estimating the positions, face orientation (or gaze direction) and trajectories of people through space has many uses, such as in crowd management, security, and healthcare. In this work, we present an open-source, low-cost, scalable and privacy-preserving edge computing framework for multi-person localization, i.e. estimating the positions, orientations, and trajectories of multiple people in an indoor space. Our computing framework consists of 38 Tensor Processing Unit (TPU)-enabled edge computing camera systems placed in the ceiling of the indoor therapeutic space. The edge compute systems are connected to an on-premise fog server through a secure and private network. A multi-person detection algorithm and a pose estimation model run on the edge TPU in real-time to collect features which are used, instead of raw images, for downstream computations. This ensures the privacy of individuals in the space, reduces data transmission/storage and improves scalability. We implemented a Kalman filter-based multi-person tracking method and a state-of-the-art body orientation estimation method to determine the positions and facing orientations of multiple people simultaneously in the indoor space. For our study site with size of 18,000 square feet, our system demonstrated an average localization error of 1.41 meters, a multiple-object tracking accuracy score of 62%, and a mean absolute body orientation error of 29{\deg}, which is sufficient for understanding group activity behaviors in indoor environments. Additionally, our study provides practical guidance for deploying the proposed system by analyzing various elements of the camera installation with respect to tracking accuracy.
A Data-Driven Gaussian Process Filter for Electrocardiogram Denoising
Jan 06, 2023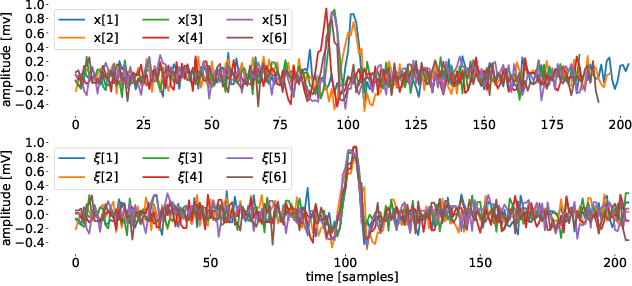
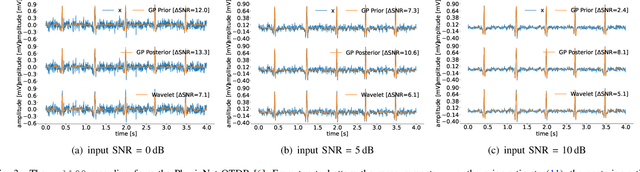
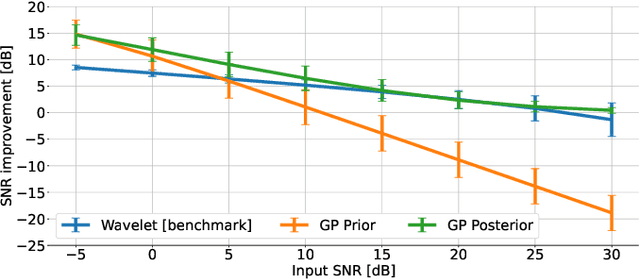
Objective: Gaussian Processes (GP)-based filters, which have been effectively used for various applications including electrocardiogram (ECG) filtering can be computationally demanding and the choice of their hyperparameters is typically ad hoc. Methods: We develop a data-driven GP filter to address both issues, using the notion of the ECG phase domain -- a time-warped representation of the ECG beats onto a fixed number of samples and aligned R-peaks, which is assumed to follow a Gaussian distribution. Under this assumption, the computation of the sample mean and covariance matrix is simplified, enabling an efficient implementation of the GP filter in a data-driven manner, with no ad hoc hyperparameters. The proposed filter is evaluated and compared with a state-of-the-art wavelet-based filter, on the PhysioNet QT Database. The performance is evaluated by measuring the signal-to-noise ratio (SNR) improvement of the filter at SNR levels ranging from -5 to 30dB, in 5dB steps, using additive noise. For a clinical evaluation, the error between the estimated QT-intervals of the original and filtered signals is measured and compared with the benchmark filter. Results: It is shown that the proposed GP filter outperforms the benchmark filter for all the tested noise levels. It also outperforms the state-of-the-art filter in terms of QT-interval estimation error bias and variance. Conclusion: The proposed GP filter is a versatile technique for preprocessing the ECG in clinical and research applications, is applicable to ECG of arbitrary lengths and sampling frequencies, and provides confidence intervals for its performance.