 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Chagas Disease from the ECG: The George B. Moody PhysioNet Challenge 2025
Oct 02, 2025Objective: Chagas disease is a parasitic infection that is endemic to South America, Central America, and, more recently, the U.S., primarily transmitted by insects. Chronic Chagas disease can cause cardiovascular diseases and digestive problems. Serological testing capacities for Chagas disease are limited, but Chagas cardiomyopathy often manifests in ECGs, providing an opportunity to prioritize patients for testing and treatment. Approach: The George B. Moody PhysioNet Challenge 2025 invites teams to develop algorithmic approaches for identifying Chagas disease from electrocardiograms (ECGs). Main results: This Challenge provides multiple innovations. First, we leveraged several datasets with labels from patient reports and serological testing, provided a large dataset with weak labels and smaller datasets with strong labels. Second, we augmented the data to support model robustness and generalizability to unseen data sources. Third, we applied an evaluation metric that captured the local serological testing capacity for Chagas disease to frame the machine learning problem as a triage task. Significance: Over 630 participants from 111 teams submitted over 1300 entries during the Challenge, representing diverse approaches from academia and industry worldwide.
Cross-Learning Between ECG and PCG: Exploring Common and Exclusive Characteristics of Bimodal Electromechanical Cardiac Waveforms
Jun 11, 2025Simultaneous electrocardiography (ECG) and phonocardiogram (PCG) provide a comprehensive, multimodal perspective on cardiac function by capturing the heart's electrical and mechanical activities, respectively. However, the distinct and overlapping information content of these signals, as well as their potential for mutual reconstruction and biomarker extraction, remains incompletely understood, especially under varying physiological conditions and across individuals. In this study, we systematically investigate the common and exclusive characteristics of ECG and PCG using the EPHNOGRAM dataset of simultaneous ECG-PCG recordings during rest and exercise. We employ a suite of linear and nonlinear machine learning models, including non-causal LSTM networks, to reconstruct each modality from the other and analyze the influence of causality, physiological state, and cross-subject variability. Our results demonstrate that nonlinear models, particularly non-causal LSTM, provide superior reconstruction performance, with reconstructing ECG from PCG proving more tractable than the reverse. Exercise and cross-subject scenarios present significant challenges, but envelope-based modeling that utilizes instantaneous amplitude features substantially improves cross-subject generalizability for cross-modal learning. Furthermore, we demonstrate that clinically relevant ECG biomarkers, such as fiducial points and QT intervals, can be estimated from PCG in cross-subject settings. These findings advance our understanding of the relationship between electromechanical cardiac modalities, in terms of both waveform characteristics and the timing of cardiac events, with potential applications in novel multimodal cardiac monitoring technologies.
On the Geometry of Receiver Operating Characteristic and Precision-Recall Curves
Apr 02, 2025



We study the geometry of Receiver Operating Characteristic (ROC) and Precision-Recall (PR) curves in binary classification problems. The key finding is that many of the most commonly used binary classification metrics are merely functions of the composition function $G := F_p \circ F_n^{-1}$, where $F_p(\cdot)$ and $F_n(\cdot)$ are the class-conditional cumulative distribution functions of the classifier scores in the positive and negative classes, respectively. This geometric perspective facilitates the selection of operating points, understanding the effect of decision thresholds, and comparison between classifiers. It also helps explain how the shapes and geometry of ROC/PR curves reflect classifier behavior, providing objective tools for building classifiers optimized for specific applications with context-specific constraints. We further explore the conditions for classifier dominance, present analytical and numerical examples demonstrating the effects of class separability and variance on ROC and PR geometries, and derive a link between the positive-to-negative class leakage function $G(\cdot)$ and the Kullback--Leibler divergence. The framework highlights practical considerations, such as model calibration, cost-sensitive optimization, and operating point selection under real-world capacity constraints, enabling more informed approaches to classifier deployment and decision-making.
Edge AI for Real-time Fetal Assessment in Rural Guatemala
Mar 12, 2025Perinatal complications, defined as conditions that arise during pregnancy, childbirth, and the immediate postpartum period, represent a significant burden on maternal and neonatal health worldwide. Factors contributing to these disparities include limited access to quality healthcare, socioeconomic inequalities, and variations in healthcare infrastructure. Addressing these issues is crucial for improving health outcomes for mothers and newborns, particularly in underserved communities. To mitigate these challenges, we have developed an AI-enabled smartphone application designed to provide decision support at the point-of-care. This tool aims to enhance health monitoring during pregnancy by leveraging machine learning (ML) techniques. The intended use of this application is to assist midwives during routine home visits by offering real-time analysis and providing feedback based on collected data. The application integrates TensorFlow Lite (TFLite) and other Python-based algorithms within a Kotlin framework to process data in real-time. It is designed for use in low-resource settings, where traditional healthcare infrastructure may be lacking. The intended patient population includes pregnant women and new mothers in underserved areas and the developed system was piloted in rural Guatemala. This ML-based solution addresses the critical need for accessible and quality perinatal care by empowering healthcare providers with decision support tools to improve maternal and neonatal health outcomes.
Electromechanical Dynamics of the Heart: A Study of Cardiac Hysteresis During Physical Stress Test
Oct 25, 2024

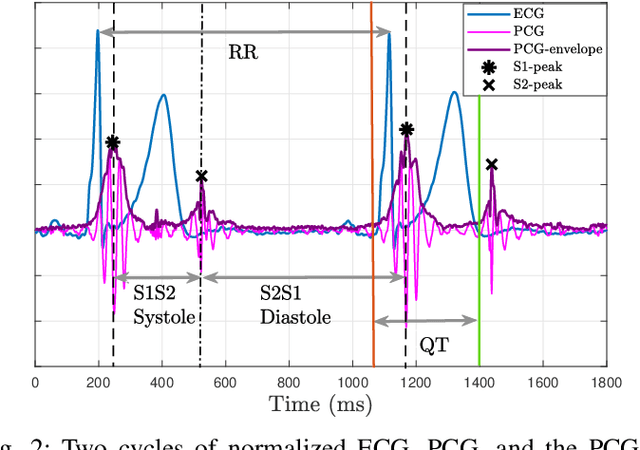

Cardiovascular diseases are best diagnosed using multiple modalities that assess both the heart's electrical and mechanical functions. While effective, imaging techniques like echocardiography and nuclear imaging are costly and not widely accessible. More affordable technologies, such as simultaneous electrocardiography (ECG) and phonocardiography (PCG), may provide valuable insights into electromechanical coupling and could be useful for prescreening in low-resource settings. Using physical stress test data from the EPHNOGRAM ECG-PCG dataset, collected from 23 healthy male subjects (age: 25.4+/-1.9 yrs), we investigated electromechanical intervals (RR, QT, systolic, and diastolic) and their interactions during exercise, along with hysteresis between cardiac electrical activity and mechanical responses. Time delay analysis revealed distinct temporal relationships between QT, systolic, and diastolic intervals, with RR as the primary driver. The diastolic interval showed near-synchrony with RR, while QT responded to RR interval changes with an average delay of 10.5s, and the systolic interval responded more slowly, with an average delay of 28.3s. We examined QT-RR, systolic-RR, and diastolic-RR hysteresis, finding narrower loops for diastolic RR and wider loops for systolic RR. Significant correlations (average:0.75) were found between heart rate changes and hysteresis loop areas, suggesting the equivalent circular area diameter as a promising biomarker for cardiac function under exercise stress. Deep learning models, including Long Short-Term Memory and Convolutional Neural Networks, estimated the QT, systolic, and diastolic intervals from RR data, confirming the nonlinear relationship between RR and other intervals. Findings highlight a significant cardiac memory effect, linking ECG and PCG morphology and timing to heart rate history.
ECG-Image-Database: A Dataset of ECG Images with Real-World Imaging and Scanning Artifacts; A Foundation for Computerized ECG Image Digitization and Analysis
Sep 25, 2024

We introduce the ECG-Image-Database, a large and diverse collection of electrocardiogram (ECG) images generated from ECG time-series data, with real-world scanning, imaging, and physical artifacts. We used ECG-Image-Kit, an open-source Python toolkit, to generate realistic images of 12-lead ECG printouts from raw ECG time-series. The images include realistic distortions such as noise, wrinkles, stains, and perspective shifts, generated both digitally and physically. The toolkit was applied to 977 12-lead ECG records from the PTB-XL database and 1,000 from Emory Healthcare to create high-fidelity synthetic ECG images. These unique images were subjected to both programmatic distortions using ECG-Image-Kit and physical effects like soaking, staining, and mold growth, followed by scanning and photography under various lighting conditions to create real-world artifacts. The resulting dataset includes 35,595 software-labeled ECG images with a wide range of imaging artifacts and distortions. The dataset provides ground truth time-series data alongside the images, offering a reference for developing machine and deep learning models for ECG digitization and classification. The images vary in quality, from clear scans of clean papers to noisy photographs of degraded papers, enabling the development of more generalizable digitization algorithms. ECG-Image-Database addresses a critical need for digitizing paper-based and non-digital ECGs for computerized analysis, providing a foundation for developing robust machine and deep learning models capable of converting ECG images into time-series. The dataset aims to serve as a reference for ECG digitization and computerized annotation efforts. ECG-Image-Database was used in the PhysioNet Challenge 2024 on ECG image digitization and classification.
Notch Filters without Transient Effects: A Constrained Optimization Design
Jun 15, 2024



Transient responses are an inherent property of recursive filters due to unknown or incorrectly selected initial conditions. Well-designed stable filters are less affected by transient responses, as the impact of initial conditions diminishes over time. However, applications that require very short data acquisition periods (for example, as short as ten seconds), such as biosignals recorded and processed by wearable technologies, can be significantly impacted by transient effects. But how feasible is it to design filters without transient responses? We propose a well-known filter design scheme based on constrained least squares (CLS) optimization to create zero-transient effect notch filters for powerline noise cancellation. We demonstrate that this filter is equivalent to the optimal Wiener smoother in the stationary case. We also discuss its limitations in removing powerline noise with nonstationary amplitude, where a Kalman filter-based formulation can be used instead.
Two-layer retrieval augmented generation framework for low-resource medical question-answering: proof of concept using Reddit data
May 29, 2024



Retrieval augmented generation (RAG) provides the capability to constrain generative model outputs, and mitigate the possibility of hallucination, by providing relevant in-context text. The number of tokens a generative large language model (LLM) can incorporate as context is finite, thus limiting the volume of knowledge from which to generate an answer. We propose a two-layer RAG framework for query-focused answer generation and evaluate a proof-of-concept for this framework in the context of query-focused summary generation from social media forums, focusing on emerging drug-related information. The evaluations demonstrate the effectiveness of the two-layer framework in resource constrained settings to enable researchers in obtaining near real-time data from users.
Learning from Two Decades of Blood Pressure Data: Demography-Specific Patterns Across 75 Million Patient Encounters
Feb 05, 2024



Hypertension remains a global health concern with a rising prevalence, necessitating effective monitoring and understanding of blood pressure (BP) dynamics. This study delves into the wealth of information derived from BP measurement, a crucial approach in informing our understanding of hypertensive trends. Numerous studies have reported on the relationship between BP variation and various factors. In this research, we leveraged an extensive dataset comprising 75 million records spanning two decades, offering a unique opportunity to explore and analyze BP variations across demographic features such as age, race, and gender. Our findings revealed that gender-based BP variation was not statistically significant, challenging conventional assumptions. Interestingly, systolic blood pressure (SBP) consistently increased with age, while diastolic blood pressure (DBP) displayed a distinctive peak in the forties age group. Moreover, our analysis uncovered intriguing similarities in the distribution of BP among some of the racial groups. This comprehensive investigation contributes to the ongoing discourse on hypertension and underscores the importance of considering diverse demographic factors in understanding BP variations. Our results provide valuable insights that may inform personalized healthcare approaches tailored to specific demographic profiles.
Leveraging Large Language Models for Analyzing Blood Pressure Variations Across Biological Sex from Scientific Literature
Feb 02, 2024Hypertension, defined as blood pressure (BP) that is above normal, holds paramount significance in the realm of public health, as it serves as a critical precursor to various cardiovascular diseases (CVDs) and significantly contributes to elevated mortality rates worldwide. However, many existing BP measurement technologies and standards might be biased because they do not consider clinical outcomes, comorbidities, or demographic factors, making them inconclusive for diagnostic purposes. There is limited data-driven research focused on studying the variance in BP measurements across these variables. In this work, we employed GPT-35-turbo, a large language model (LLM), to automatically extract the mean and standard deviation values of BP for both males and females from a dataset comprising 25 million abstracts sourced from PubMed. 993 article abstracts met our predefined inclusion criteria (i.e., presence of references to blood pressure, units of blood pressure such as mmHg, and mention of biological sex). Based on the automatically-extracted information from these articles, we conducted an analysis of the variations of BP values across biological sex. Our results showed the viability of utilizing LLMs to study the BP variations across different demographic factors.