 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging large language models and traditional machine learning ensembles for ADHD detection from narrative transcripts
May 27, 2025Despite rapid advances in large language models (LLMs), their integration with traditional supervised machine learning (ML) techniques that have proven applicability to medical data remains underexplored. This is particularly true for psychiatric applications, where narrative data often exhibit nuanced linguistic and contextual complexity, and can benefit from the combination of multiple models with differing characteristics. In this study, we introduce an ensemble framework for automatically classifying Attention-Deficit/Hyperactivity Disorder (ADHD) diagnosis (binary) using narrative transcripts. Our approach integrates three complementary models: LLaMA3, an open-source LLM that captures long-range semantic structure; RoBERTa, a pre-trained transformer model fine-tuned on labeled clinical narratives; and a Support Vector Machine (SVM) classifier trained using TF-IDF-based lexical features. These models are aggregated through a majority voting mechanism to enhance predictive robustness. The dataset includes 441 instances, including 352 for training and 89 for validation. Empirical results show that the ensemble outperforms individual models, achieving an F$_1$ score of 0.71 (95\% CI: [0.60-0.80]). Compared to the best-performing individual model (SVM), the ensemble improved recall while maintaining competitive precision. This indicates the strong sensitivity of the ensemble in identifying ADHD-related linguistic cues. These findings demonstrate the promise of hybrid architectures that leverage the semantic richness of LLMs alongside the interpretability and pattern recognition capabilities of traditional supervised ML, offering a new direction for robust and generalizable psychiatric text classification.
Comparing Llama3 and DeepSeekR1 on Biomedical Text Classification Tasks
Mar 19, 2025


This study compares the performance of two open-source large language models (LLMs)-Llama3-70B and DeepSeekR1-distill-Llama3-70B-on six biomedical text classification tasks. Four tasks involve data from social media, while two tasks focus on clinical notes from electronic health records, and all experiments were performed in zero-shot settings. Performance metrics, including precision, recall, and F1 scores, were measured for each task, along with their 95% confidence intervals. Results demonstrated that DeepSeekR1-distill-Llama3-70B generally performs better in terms of precision on most tasks, with mixed results on recall. While the zero-shot LLMs demonstrated high F1 scores for some tasks, they grossly underperformed on others, for data from both sources. The findings suggest that model selection should be guided by the specific requirements of the health-related text classification tasks, particularly when considering the precision-recall trade-offs, and that, in the presence of annotated data, supervised classification approaches may be more reliable than zero-shot LLMs.
HILGEN: Hierarchically-Informed Data Generation for Biomedical NER Using Knowledgebases and Large Language Models
Mar 06, 2025We present HILGEN, a Hierarchically-Informed Data Generation approach that combines domain knowledge from the Unified Medical Language System (UMLS) with synthetic data generated by large language models (LLMs), specifically GPT-3.5. Our approach leverages UMLS's hierarchical structure to expand training data with related concepts, while incorporating contextual information from LLMs through targeted prompts aimed at automatically generating synthetic examples for sparsely occurring named entities. The performance of the HILGEN approach was evaluated across four biomedical NER datasets (MIMIC III, BC5CDR, NCBI-Disease, and Med-Mentions) using BERT-Large and DANN (Data Augmentation with Nearest Neighbor Classifier) models, applying various data generation strategies, including UMLS, GPT-3.5, and their best ensemble. For the BERT-Large model, incorporating UMLS led to an average F1 score improvement of 40.36%, while using GPT-3.5 resulted in a comparable average increase of 40.52%. The Best-Ensemble approach using BERT-Large achieved the highest improvement, with an average increase of 42.29%. DANN model's F1 score improved by 22.74% on average using the UMLS-only approach. The GPT-3.5-based method resulted in a 21.53% increase, and the Best-Ensemble DANN model showed a more notable improvement, with an average increase of 25.03%. Our proposed HILGEN approach improves NER performance in few-shot settings without requiring additional manually annotated data. Our experiments demonstrate that an effective strategy for optimizing biomedical NER is to combine biomedical knowledge curated in the past, such as the UMLS, and generative LLMs to create synthetic training instances. Our future research will focus on exploring additional innovative synthetic data generation strategies for further improving NER performance.
Two-layer retrieval augmented generation framework for low-resource medical question-answering: proof of concept using Reddit data
May 29, 2024



Retrieval augmented generation (RAG) provides the capability to constrain generative model outputs, and mitigate the possibility of hallucination, by providing relevant in-context text. The number of tokens a generative large language model (LLM) can incorporate as context is finite, thus limiting the volume of knowledge from which to generate an answer. We propose a two-layer RAG framework for query-focused answer generation and evaluate a proof-of-concept for this framework in the context of query-focused summary generation from social media forums, focusing on emerging drug-related information. The evaluations demonstrate the effectiveness of the two-layer framework in resource constrained settings to enable researchers in obtaining near real-time data from users.
Evaluating Large Language Models for Health-Related Text Classification Tasks with Public Social Media Data
Mar 27, 2024



Large language models (LLMs) have demonstrated remarkable success in NLP tasks. However, there is a paucity of studies that attempt to evaluate their performances on social media-based health-related natural language processing tasks, which have traditionally been difficult to achieve high scores in. We benchmarked one supervised classic machine learning model based on Support Vector Machines (SVMs), three supervised pretrained language models (PLMs) based on RoBERTa, BERTweet, and SocBERT, and two LLM based classifiers (GPT3.5 and GPT4), across 6 text classification tasks. We developed three approaches for leveraging LLMs for text classification: employing LLMs as zero-shot classifiers, us-ing LLMs as annotators to annotate training data for supervised classifiers, and utilizing LLMs with few-shot examples for augmentation of manually annotated data. Our comprehensive experiments demonstrate that employ-ing data augmentation using LLMs (GPT-4) with relatively small human-annotated data to train lightweight supervised classification models achieves superior results compared to training with human-annotated data alone. Supervised learners also outperform GPT-4 and GPT-3.5 in zero-shot settings. By leveraging this data augmentation strategy, we can harness the power of LLMs to develop smaller, more effective domain-specific NLP models. LLM-annotated data without human guidance for training light-weight supervised classification models is an ineffective strategy. However, LLM, as a zero-shot classifier, shows promise in excluding false negatives and potentially reducing the human effort required for data annotation. Future investigations are imperative to explore optimal training data sizes and the optimal amounts of augmented data.
Learning from Two Decades of Blood Pressure Data: Demography-Specific Patterns Across 75 Million Patient Encounters
Feb 05, 2024



Hypertension remains a global health concern with a rising prevalence, necessitating effective monitoring and understanding of blood pressure (BP) dynamics. This study delves into the wealth of information derived from BP measurement, a crucial approach in informing our understanding of hypertensive trends. Numerous studies have reported on the relationship between BP variation and various factors. In this research, we leveraged an extensive dataset comprising 75 million records spanning two decades, offering a unique opportunity to explore and analyze BP variations across demographic features such as age, race, and gender. Our findings revealed that gender-based BP variation was not statistically significant, challenging conventional assumptions. Interestingly, systolic blood pressure (SBP) consistently increased with age, while diastolic blood pressure (DBP) displayed a distinctive peak in the forties age group. Moreover, our analysis uncovered intriguing similarities in the distribution of BP among some of the racial groups. This comprehensive investigation contributes to the ongoing discourse on hypertension and underscores the importance of considering diverse demographic factors in understanding BP variations. Our results provide valuable insights that may inform personalized healthcare approaches tailored to specific demographic profiles.
Leveraging Large Language Models for Analyzing Blood Pressure Variations Across Biological Sex from Scientific Literature
Feb 02, 2024Hypertension, defined as blood pressure (BP) that is above normal, holds paramount significance in the realm of public health, as it serves as a critical precursor to various cardiovascular diseases (CVDs) and significantly contributes to elevated mortality rates worldwide. However, many existing BP measurement technologies and standards might be biased because they do not consider clinical outcomes, comorbidities, or demographic factors, making them inconclusive for diagnostic purposes. There is limited data-driven research focused on studying the variance in BP measurements across these variables. In this work, we employed GPT-35-turbo, a large language model (LLM), to automatically extract the mean and standard deviation values of BP for both males and females from a dataset comprising 25 million abstracts sourced from PubMed. 993 article abstracts met our predefined inclusion criteria (i.e., presence of references to blood pressure, units of blood pressure such as mmHg, and mention of biological sex). Based on the automatically-extracted information from these articles, we conducted an analysis of the variations of BP values across biological sex. Our results showed the viability of utilizing LLMs to study the BP variations across different demographic factors.
Few-Shot Recognition and Classification of Jamming Signal via CGAN-Based Fusion CNN Algorithm
Nov 09, 2023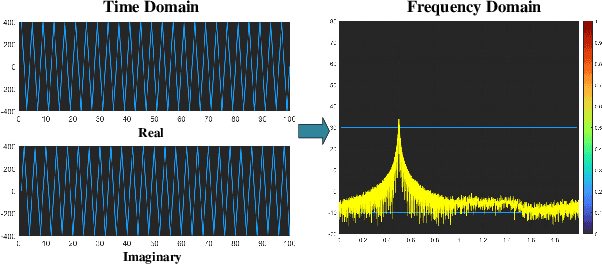



The precise classification of jamming signals holds paramount significance in the effective implementation of anti-jamming strategies within communication systems subject to intricate environmental variables. In light of this imperative, we propose an innovative fusion algorithm based on conditional generative adversarial network (CGAN) and convolutional neural network (CNN) to solve the problem of difficulty in applying deep learning (DL) algorithms due to the instantaneous nature of jamming signals in practical communication systems. Compared with previous methods, our algorithm achieved an 8% improvement in accuracy even when working with a limited dataset. Unlike previous research, we have simulated real-world satellite communication scenarios using a hardware platform and validated our algorithm using the resulting time-domain waveform data. The experimental results indicate that our algorithm still performs extremely well, which demonstrates significant potential for practical application in real-world communication scenarios.
Generalizable Natural Language Processing Framework for Migraine Reporting from Social Media
Dec 23, 2022



Migraine is a high-prevalence and disabling neurological disorder. However, information migraine management in real-world settings could be limited to traditional health information sources. In this paper, we (i) verify that there is substantial migraine-related chatter available on social media (Twitter and Reddit), self-reported by migraine sufferers; (ii) develop a platform-independent text classification system for automatically detecting self-reported migraine-related posts, and (iii) conduct analyses of the self-reported posts to assess the utility of social media for studying this problem. We manually annotated 5750 Twitter posts and 302 Reddit posts. Our system achieved an F1 score of 0.90 on Twitter and 0.93 on Reddit. Analysis of information posted by our 'migraine cohort' revealed the presence of a plethora of relevant information about migraine therapies and patient sentiments associated with them. Our study forms the foundation for conducting an in-depth analysis of migraine-related information using social media data.
Few-shot learning for medical text: A systematic review
Apr 21, 2022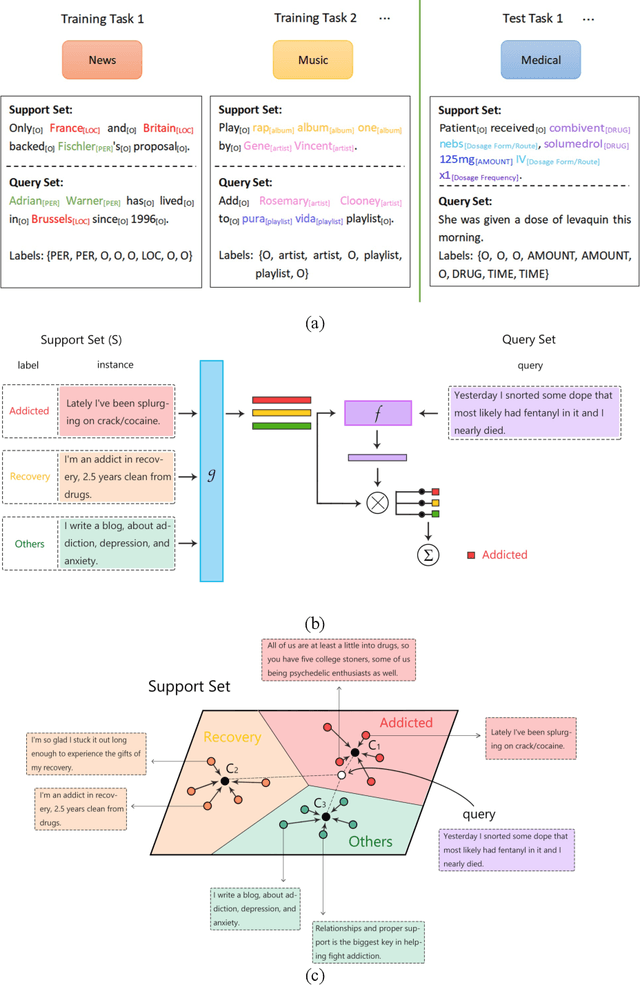
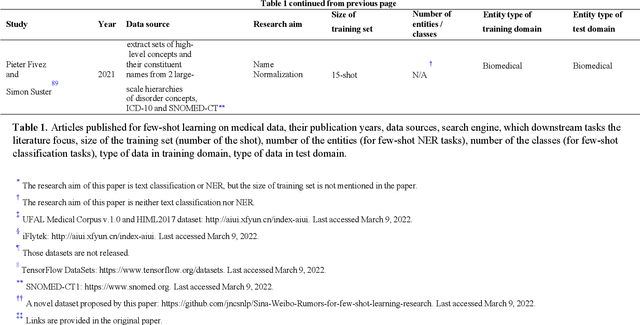
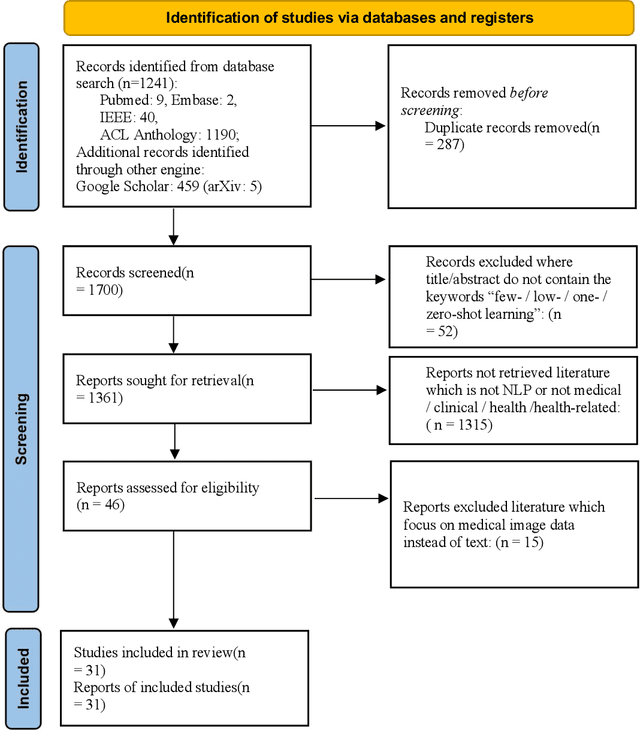
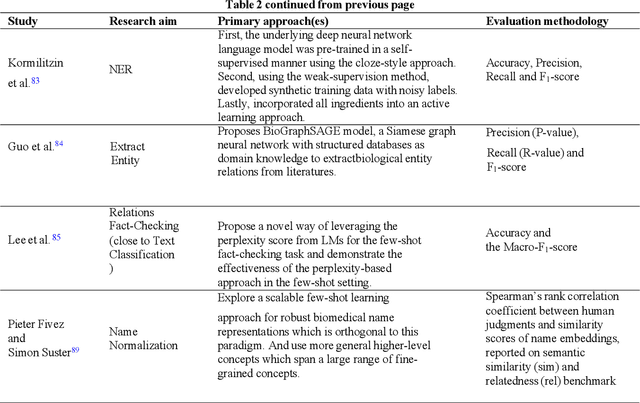
Objective: Few-shot learning (FSL) methods require small numbers of labeled instances for training. As many medical topics have limited annotated textual data in practical settings, FSL-based natural language processing (NLP) methods hold substantial promise. We aimed to conduct a systematic review to explore the state of FSL methods for medical NLP. Materials and Methods: We searched for articles published between January 2016 and August 2021 using PubMed/Medline, Embase, ACL Anthology, and IEEE Xplore Digital Library. To identify the latest relevant methods, we also searched other sources such as preprint servers (eg., medRxiv) via Google Scholar. We included all articles that involved FSL and any type of medical text. We abstracted articles based on data source(s), aim(s), training set size(s), primary method(s)/approach(es), and evaluation method(s). Results: 31 studies met our inclusion criteria-all published after 2018; 22 (71%) since 2020. Concept extraction/named entity recognition was the most frequently addressed task (13/31; 42%), followed by text classification (10/31; 32%). Twenty-one (68%) studies reconstructed existing datasets to create few-shot scenarios synthetically, and MIMIC-III was the most frequently used dataset (7/31; 23%). Common methods included FSL with attention mechanisms (12/31; 39%), prototypical networks (8/31; 26%), and meta-learning (6/31; 19%). Discussion: Despite the potential for FSL in biomedical NLP, progress has been limited compared to domain-independent FSL. This may be due to the paucity of standardized, public datasets, and the relative underperformance of FSL methods on biomedical topics. Creation and release of specialized datasets for biomedical FSL may aid method development by enabling comparative analyses.