 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot learning for medical text: A systematic review
Apr 21, 2022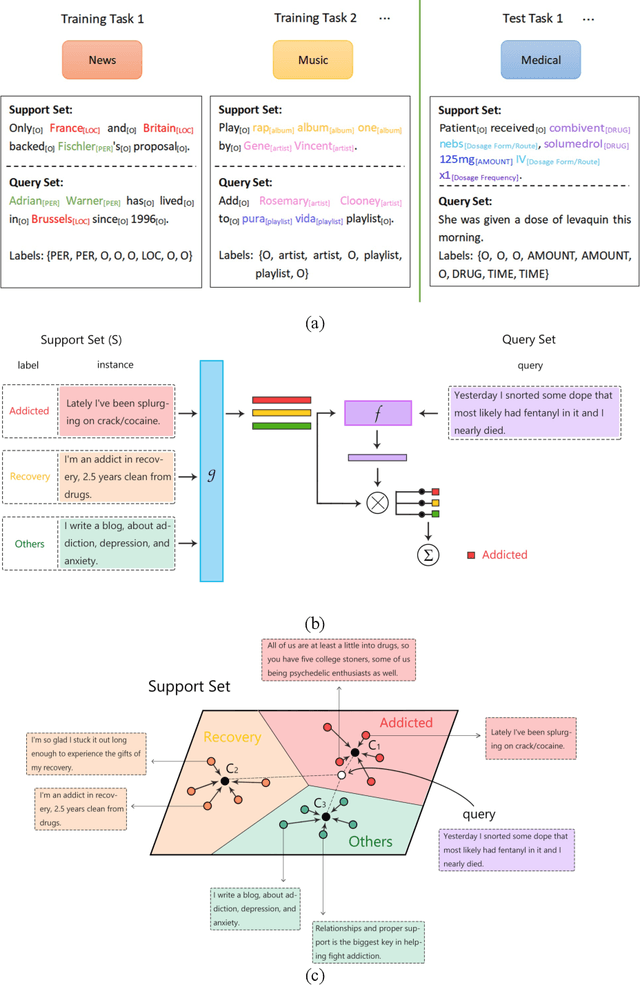
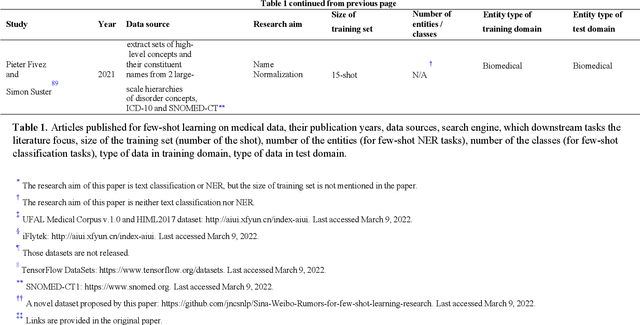
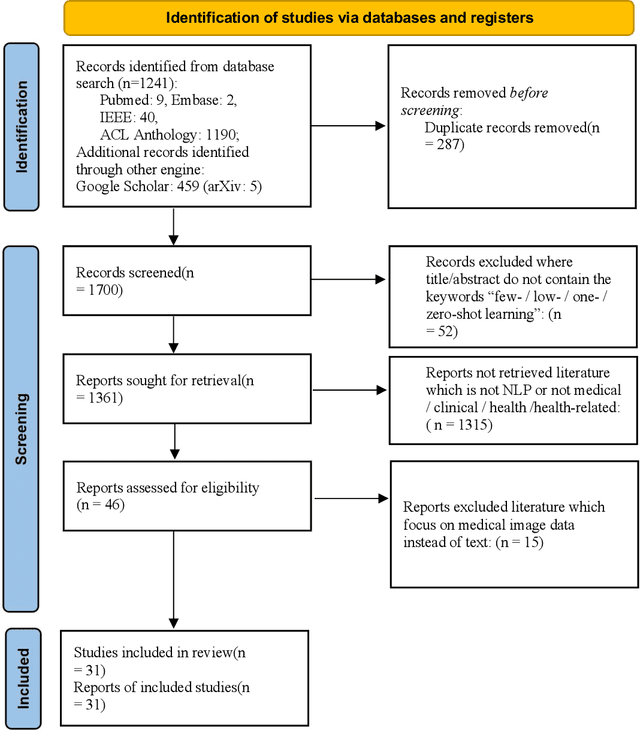
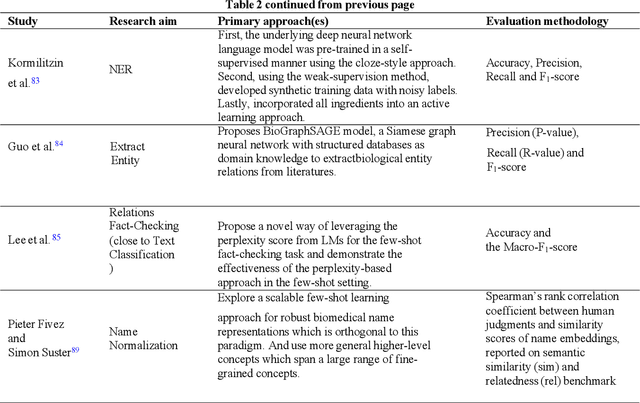
Objective: Few-shot learning (FSL) methods require small numbers of labeled instances for training. As many medical topics have limited annotated textual data in practical settings, FSL-based natural language processing (NLP) methods hold substantial promise. We aimed to conduct a systematic review to explore the state of FSL methods for medical NLP. Materials and Methods: We searched for articles published between January 2016 and August 2021 using PubMed/Medline, Embase, ACL Anthology, and IEEE Xplore Digital Library. To identify the latest relevant methods, we also searched other sources such as preprint servers (eg., medRxiv) via Google Scholar. We included all articles that involved FSL and any type of medical text. We abstracted articles based on data source(s), aim(s), training set size(s), primary method(s)/approach(es), and evaluation method(s). Results: 31 studies met our inclusion criteria-all published after 2018; 22 (71%) since 2020. Concept extraction/named entity recognition was the most frequently addressed task (13/31; 42%), followed by text classification (10/31; 32%). Twenty-one (68%) studies reconstructed existing datasets to create few-shot scenarios synthetically, and MIMIC-III was the most frequently used dataset (7/31; 23%). Common methods included FSL with attention mechanisms (12/31; 39%), prototypical networks (8/31; 26%), and meta-learning (6/31; 19%). Discussion: Despite the potential for FSL in biomedical NLP, progress has been limited compared to domain-independent FSL. This may be due to the paucity of standardized, public datasets, and the relative underperformance of FSL methods on biomedical topics. Creation and release of specialized datasets for biomedical FSL may aid method development by enabling comparative analyses.